This chapter presents a proof-of-concept for a risk model that the General Comptroller of the State Administration (Intervención General de la Administración del Estado, IGAE) of Spain can employ to assess fraud risks and detect likely fraud cases. The chapter presents an overview of the machine learning methodology that underlies the risk model, as well as a detailed account of how the model was built, based on data that are readily available to the IGAE. The chapter concludes with a discussion about the results of the model and recommendations for the IGAE to build on the proof-of-concept.
Countering Public Grant Fraud in Spain
Machine Learning for Assessing Risks and Targeting Control Activities
OECD Public Governance Reviews

2. Fraud in public grants: Piloting a data-driven risk model in Spain
Abstract
Introduction
Data-driven fraud risk assessment frameworks can have multiple uses, among which identifying investigative priorities is central. When investigative resources are scarce and a random selection of cases for investigation is likely to yield a low success rate (e.g. because fraud is rare on the target population), a risk-based case selection can deliver material benefits. To this end, a risk score assigned to all potentially investigated cases can feed into the prioritisation of cases for investigation. This typically does not imply a full automation of case selection; rather analytics offers a crucial input into the organisational decision-making process.
For a large-scale risk assessment to deliver benefits, it has to be accurate enough to be used for risk scoring transactions or organisations on an ongoing basis, including new cases. In general, risk scores can be defined to be valid for such purposes either by explicitly defining the risk factors from known relationships and risk descriptions (e.g. grant recipient organisation’s ultimate owner being based in a tax haven) or by defining the combination of risk features through statistical means, including machine learning from past investigations. Either way, what is crucial is that the risk model not only considers known fraudulent cases and their features but it also takes into account the features of a much larger group of cases which were not investigated, hence whose fraud status is unknown. In short, indicator validation and continuous improvement are of crucial importance, as shown in this chapter.
When developing new analytical approaches, often insights and learning comes from doing. This is why many audit institutions, for instance, have established “Innovation Labs” and internal communities of practice to test and experiment with new audit techniques, analytics and technologies and uses of data. This incremental approach allows audit and control bodies to take measured risks and contain costs, before either scaling up or winding down pilot initiatives. In this spirit and in response to the interest of the General Comptroller of the State Administration (Intervención General de la Administración del Estado, IGAE) in strengthening its use of data to detect grant fraud risks, this chapter presents a proof-of-concept for a data-driven risk model for the IGAE to adopt in part or in its entirety.
The methodology in this chapter aims to make use of the data that was already at the IGAE’s disposal, including the National Subsidies Database (Base de Datos Nacional de Subvenciones, BDNS), and in doing so, implicitly takes into account the IGAE’s context. As noted in Chapter 1, like any investment to improve data governance, data management, or analytics, this approach may require investments in skills and digital capacity. For this reason, the chapter provides a detailed account of all stages of the methodology and its development to support the IGAE’s own assessment of what it is able to do with its existing resources and skills in-house. In addition, the process of developing the proof-of-concept for the risk model led to several insights and the identification of areas for improvement, which are addressed in the results section.
Overview of the machine learning model
A brief primer on machine learning for risk assessments
The IGAE’s current approach to assessing fraud risks, described in Chapter 1, is outlined in its 2021 Financial Audit and Control Plan of Subsidies and Public Aid. The IGAE considers the grant amount, previous levels of fraud and other qualitative factors, such as the justification and verification procedures. The machine learning model described in this chapter advances a more data-driven approach, which can complement the IGAE’s existing processes. In reality, given resource constraints, the IGAE can only carry out a finite number of control activities in any year. The machine learning methodology described in this chapter should not replace auditors’ judgement. For instance, the model can highlight cases of likely fraud, but the auditor will also need to assess which of these cases would be the most profitable in terms of further investigatory or control activities. Taking this nuance into account, the model can be a useful input into auditors’ decision-making, and help the IGAE to target its resources more effectively.
The risk model developed to support the IGAE is based on a random forest methodology. Random forests is a supervised machine learning method which predicts the output by constructing multiple decision trees with given features (Breiman, 2001[1]). It is particularly well suited for datasets with a large number of explanatory variables or potential risk indicators. By using random forests, it is possible to include a wide list of explanatory factors of different types (numeric and categorical).
Selection of the methodology
In order to analyse the data using machine learning methods such as random forests, the dataset was cleaned by removing missing values and variables lacking variability (i.e. where the variables take almost always the same value in the entire dataset). Random forests allow for working with a large number of observations as well as variables, performing algorithm training on a reduced and balanced sample, and testing models on a set-aside sample. Random Forest algorithms are sensitive to missing values. For this reason, variables with high missing rates were dropped. The method is also sensitive to imbalance in the dependent variable (i.e. sanctioned versus non-sanctioned), as described below. In general, the approach can be broken down into the following steps:
1. Identify which grantees were sanctioned, and then mark all awards of the sanctioned organisations from the last 2 to 3 years prior to sanctions. In this period, proven fraudulent activity is very likely to have taken place. This gives a full set of proven positive cases (sanctioned awards); however it leaves a very large sample of unlabelled cases (non-sanctioned). Some of these cases likely should have been sanctioned, but were not investigated, and others are true negative cases where sanctioning would not have occurred even if they were investigated. In other words, the dataset is strongly imbalanced. In most of the cases, it is unknown if the award was not sanctioned, either because it was not investigated, or because it was yet no violations were discovered. Therefore, the majority of observations are neither positives nor negatives, but rather they are unlabelled.
2. Choose the method that fits the particular problem in the data, that is, an imbalanced sample and the presence of a large, unlabelled subsample. For these purposes, a positive unlabelled (PU) bagging model is applied. This machine learning method enables training a model on random samples of observations, both positive and unlabelled, in order to assign likely negative status (not sanctioned) and likely positive (sanctioned) status to unlabelled cases. Box 2.1 provides additional background on PU bagging and random forest models.
3. After the labels are assigned, use the relabelled dataset to train the model and identify factors that influence the probability of being sanctioned. The influence can be both positive and negative. The model then calculates the probability for each award to be sanctioned on any number of observations.
4. Once the model is trained and achieves a sufficient accuracy, apply it to the full dataset of awards in order to predict a fraud risk score for all observations.1
Box 2.1. Overview of positive unlabelled learning and bagging
Positive unlabelled (PU) learning is a semi-supervised machine learning technique, which allows working with highly unbalanced data (Elkan and Noto, 2008[2]). PU learning could be used in cases when the majority of all available observations belongs to unlabelled cases. For example, this includes situations when a binary variable (i.e. values of 1 and 0) has positive observations (1) that appear only in case of treatment, and when it is unknown whether the remaining negative cases (0) were treated but remained negative, or they were not treated at all. PU learning observes all the positive and negative cases, identifies the most typical characteristics referring to each, and relabels observations accordingly.
A PU bagging approach consists of several steps (Li and Hua, 2014[3]). First, it involves building a classifier by analysing the variety and combination of factors influencing positive and negative outcomes. To build a classifier, a subset of data are created, consisting of all positive cases and a random sample of unlabelled ones. This classifier is further applied to the rest of unlabelled cases to assign the probability scores for the rest of the observations. Each step is repeated several times, and then the average score received by each observation is calculated.
After relabelling, all observations are divided into training and testing samples. The ratio of the split is flexible, but it is usually between 60-70% for the training sample and 30-40% for the testing sample. Next, the random forests method is applied to the training set of data. The parameters of the model can be specified manually, including the number of trees, maximum number of features in each individual tree and the size of terminal nodes. The choice of the parameters depends on the overall size of the data, namely, the number of observations and indicators included in the model. After applying the random forests method to the training sample, the output probabilities can be predicted for the rest of the data.
Additionally, to identify the impact of each feature, SHAP values (Shapley Additive Explanations) can be calculated once the model is constructed. SHAP values show how much and in which direction (positive or negative) a given indicator changed the predicted output. To estimate the model fit, such parameters as accuracy, recall and precision should be calculated. All of them calculate the number of correctly predicted scores in either absolute or relative numbers.
Source: (Mordelet and Vert, 2014[4])
Consideration of strengths, weaknesses and assumptions
The validity of the analysis depends on two factors: the quality of the learning dataset and the availability of the relevant award, grant and grantee features. First, the main indicator differentiating fraudulent cases from non-fraudulent ones is the presence of sanctions. For positive-unlabelled learning to produce valid results, it was assumed that positive cases have been selected at random, hence are a representative sample of all positive cases. This also implies that if the observed sanctions sample missed out on some typical fraud schemes (i.e. not even one example is to be found among observed sanctions cases), the machine learning model will not capture such fraud types, hence will be biased. Similarly, if cases were selected following a particular variable, say the size of the grantee, the model will overestimate the importance of such a variable in the risk prediction. In other words, supervised machine learning uses the information given by proven cases, therefore if there is a bias in the sample of sanctioned awards - it will be replicated in the prediction process.
Second, the machine learning model can only learn features of fraud which are captured by the data. The presence of certain indicators in the dataset influences the predictive power of the model: if some crucial characteristics are missing from the data, they will not be taken into account by the model. Missing features or indicators also imply that the final list of influential indicators may be biased, overstating the importance of those features which are correlated with influential but unobserved features (e.g. if a particular region is found to be of higher risk, it may actually mean that some entities in that region have risky features, say links to corrupt politicians, rather than the region itself, its culture, administrative structures etc. being more prone to fraud.). Nevertheless, the chosen machine learning method based on Random Forests is particularly well suited for large datasets with a big number of explanatory variables or potential risk indicators (James et al., 2015[5]) It is possible to include a wide list of explanatory factors of different types (numeric and categorical).
Developing a proof-of-concept for a data-driven risk model
Identifying relevant data sources and variables for assessing grant fraud risks
The data provided by the IGAE consists of 17 datasets covering different pieces of information on awards, third parties, projects, grants and grantees. They could be grouped into three main categories.
The first category consists of seven datasets that cover information about the grant, such as location, type of economic activity, objectives and instruments.2
The second category covers awards information, including information on refunds, projects, returns and details of the awards to beneficiaries.3
The third category includes datasets that cover information on the beneficiaries themselves, which can include a range of actors responsible for implementing a project (e.g. a government entity, contractor or sub-contractor), such as whether a beneficiary was sanctioned or disqualified, as well as the type of economic activity, location, and so forth.4
In total, these datasets consist of around 100 variables covering details of the awards (amount, date of receiving, type of economic activity, etc.), grant calls (publicity, type of economic support, regulatory base, etc.), and details of the third parties (location, legal nature, economic activities, etc.). The time period covered is 2018-2020.
All three groups of datasets present different levels of data: the first category covers grant-level information, and each grant could embrace a few awards. The second category includes award-level, and could be linked to the main dataset BDNS_CONCESIONES by unique award IDs. Finally, the last category is third party-level, and the same third party can receive multiple awards. Therefore, for the sake of merging all datasets between each other, the award level was used as a main unit of analysis, providing unique IDs.
The list of variables relevant for fraud risk assessment could be divided into background and risk indicators. Background indicators are needed to describe specific characteristics of grants, grantors, grantees and third parties which are potentially associated with sanctions. Risk indicators refer to certain phases of grant advertisement, selection, execution and monitoring. Table 2.1 shows the full list of background indicators, Table 2.2 shows risk indicators that could be extracted from IGAE’s datasets.
Table 2.1. Background indicators
Source: Author
Table 2.2. Risk indicators
Source: Author
Merging, cleaning and understanding the limitations of the data
The first step of data processing was to merge all the datasets provided by Spanish government to the main dataset covering all grants and awards, BDNS_CONCESIONES. In order to do that each dataset was aligned to the same unit of analysis - award ID. When multiple observations were related to the same award ID (e.g. one award relating to multiple sectors), the data was aggregated, for example by placing each duplicate observation in a separate column. When observations related to a series of award IDs (e.g. when the dataset contained information on calls for applications), the relevant characteristics were copied over to all awards relating to that higher level observation. The merged, but uncleaned dataset contains 1 792 546 awards and 152 variables. The full list of variables included could be found in Annex B.
The next step of data processing was data cleaning. This involved removing variables with high missing rate or low variance. Such data problems impact a high number of variables as shown in Figure 2.1. All variables with a missing rate higher than 50% were removed as they would have introduced a high degree of noise into the analysis. Most of these variables with high missing rate correspond to sanctions and project description. Additionally, some of the variables showed very low variance less than 0.3, which means that they carry very little relevant information for the subsequent analysis (i.e. in technical terms: their discriminant value is low as they do not vary sufficiently between sanctioned and non-sanctioned observations). Finally, text variables which are not directly relevant for risk scoring were removed such as text descriptors of categorical variables (e.g. sector descriptions in Spanish) and free text variables carrying little relevant information (e.g. title of the call for grant applications).
Figure 2.1. Missing values rates
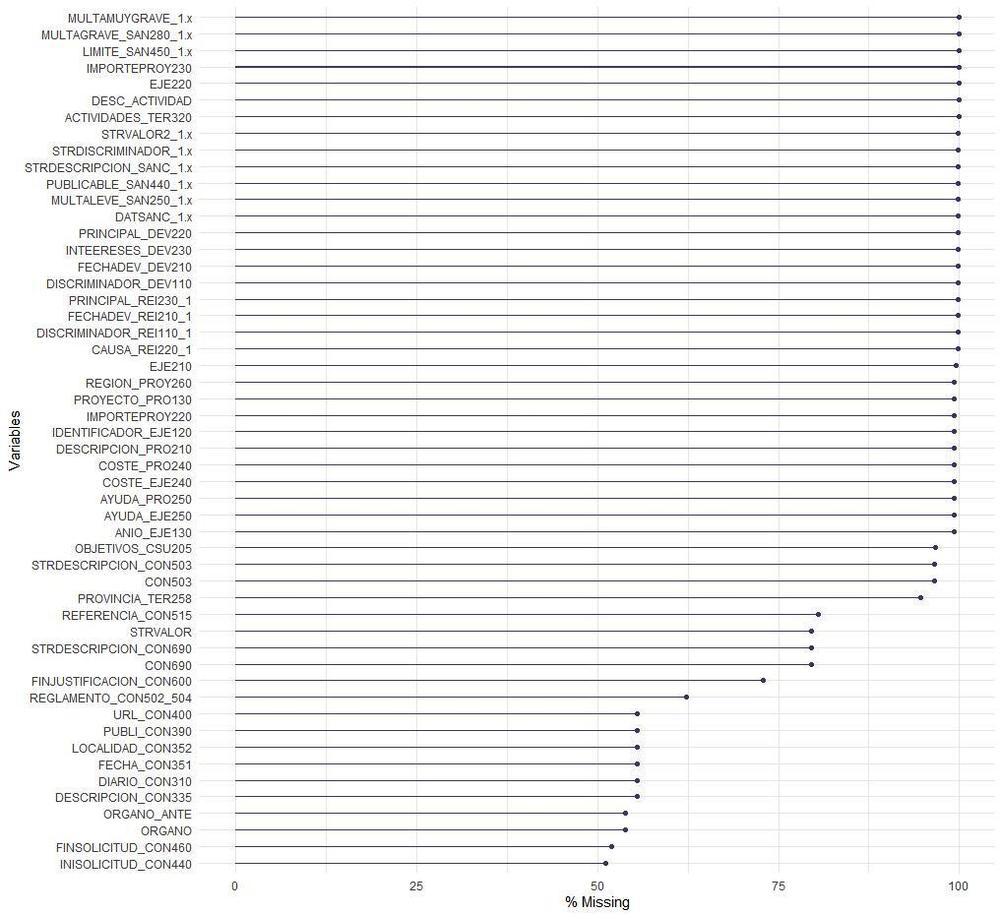
Source: Author
As the analytical methods used can be sensitive to missing information, only those observations, i.e. awards, which had no missing values on all the variables considered in the analysis were retained. After conducting all these steps of data processing, the final dataset used in the analysis consists of 1 050 470 observations, awards, and 60 variables for the years from 2018 to 2020 (inclusive).
Using existing data to create new indicators
While most indicators used in the analysis directly derive from the data received, a few indicators were also calculated by combining other variables. The first group of such calculated indicators refer to the size and number of awards received by the same beneficiary. The second group consists of location-related variables: the territorial level of grantor and grantee: national, regional or local. Additionally, a binary variable was created for identifying if the execution of the contract was located in the same place as the third party. Third, an indicator was calculated capturing the month of grant award which can indicate seasonality in spending and the corresponding risks. Finally, the sector of the award was cleaned to only capture the highest level of the NACE classification. See Annex B for a table that describes all the variables from these additional variable calculations and the previously described data processing steps. This is the final list of variables used for risk modelling.
Defining the dependent variable based on sanctioning status
The main dependent variable used for the analysis is a binary variable indicating if the third party receiving the award was sanctioned or not; with the sanctioning interpreted as a reliable indication of fraud in an award. The variable turns value “1” if the third party was sanctioned for corresponding award, as well as for all previous awards received by the same party, as fraudulent practices have taken place earlier than the date of sanction. In case if the third party was not sanctioned, the corresponding award gets value “0” in the dummy variable. The classes in the sanction variable are very imbalanced - it shows 1 031 cases of sanctions against 1 049 439 cases of no sanctions.
In order to make the random forest algorithm run efficiently, a random sample was drawn of 90 000 awards from the unlabelled portion of the dataset. Hence, the training dataset used in the below analysis makes use of the initial sample of 91 031 awards, consisting of 1 031 positive (known sanctions) and 90 000 unlabelled (unclear fraud status) awards.
Assigning sanctions status to unlabelled awards
In order to assign positive and negative labels to unlabelled observations, the positive unlabelled learning methodology was used. This method starts off by creating a training subset of the data, consisting of all positive cases and a random sample of unlabelled cases. On this sample, PU bagging builds a classifier which assigns the probability of sanctioning to each award, based on which it is possible to assign the positive and negative label (sanctioning probability >50% → positive label). These steps are repeated 1 000 times in order to build a reliable classifier which identifies the likely negative and likely positive cases in the unlabelled sample (please note that the average predicted sanctioning probability across all models will become the eventual predicted score).
As a result of running these algorithms, all unlabelled cases received a sanctioning probability and hence a likely sanctioning label (positive vs negative). For the training dataset, Figure 2.2 presents the distribution of sanctioning (i.e. fraud) probabilities. This highlights that most awards are considered low to very low risk with only a handful of awards receiving a high risk score. In other words, most awards can be classified as non-sanctioned while very few awards receive the sanctioned label: compared to the initial positive-unlabelled sample, the number of likely positive (sanctioned) cases increased to 4 430 with the 86 601 being identified as likely negative (not sanctioned).
Figure 2.2. PU bagging classifier: sanctioning probability prediction on the initial sample
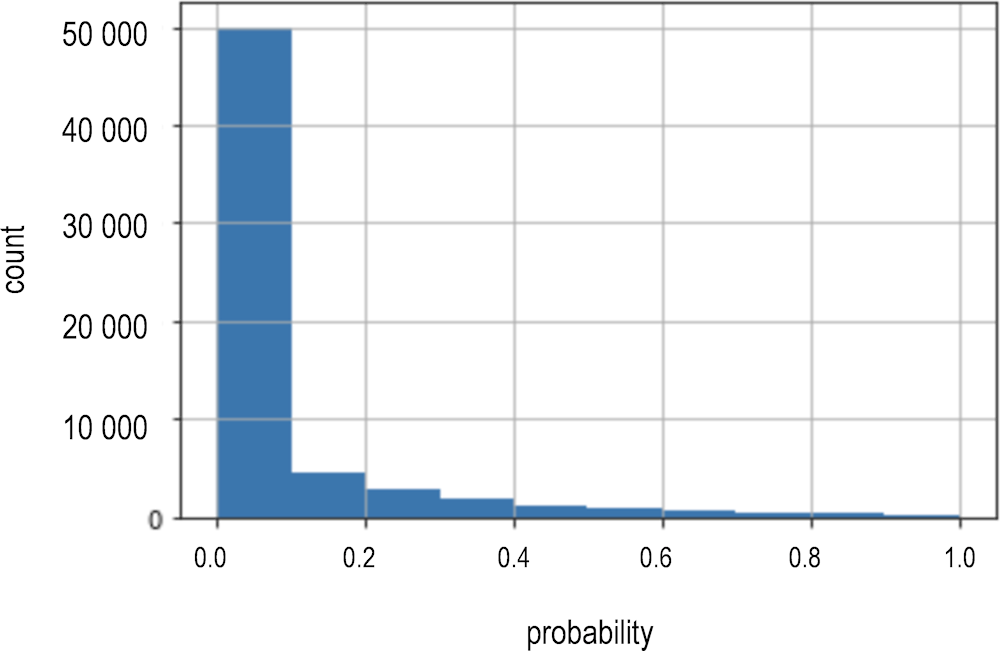
Source: Author
Identifying the most impactful variables
Once the dataset of positive and unlabelled awards is relabelled and only positive and negative cases remain in the dataset following the methods above, a new Random Forest model is run and tested for its accuracy. This means that the relabelled dataset of 91 031 awards was split into a training sample (70%) and a test sample (30%). The Random Forest algorithm will be trained on the former and test its accuracy on the latter sample which it has not ‘seen’. The best model consists of 1 000 trees and uses 106 variables at each run.
This best Random Forest model identified the most important variables for predicting the probability of sanctions. For the purposes of modelling, each categorical variable was transformed into a set of binary variables, so that they correspond to a single category of the categorical variable. Numeric variables were used as is, without transformation. The most impactful variables in the best Random Forest model are Public_purpose_CON540,Nawards_TER_110, Amount_awards_TER110, and Third_party_legal_Spain_TER280. Their distributions are presented in Figure 2.3.
Figure 2.3. Distributions of the most impactful variables
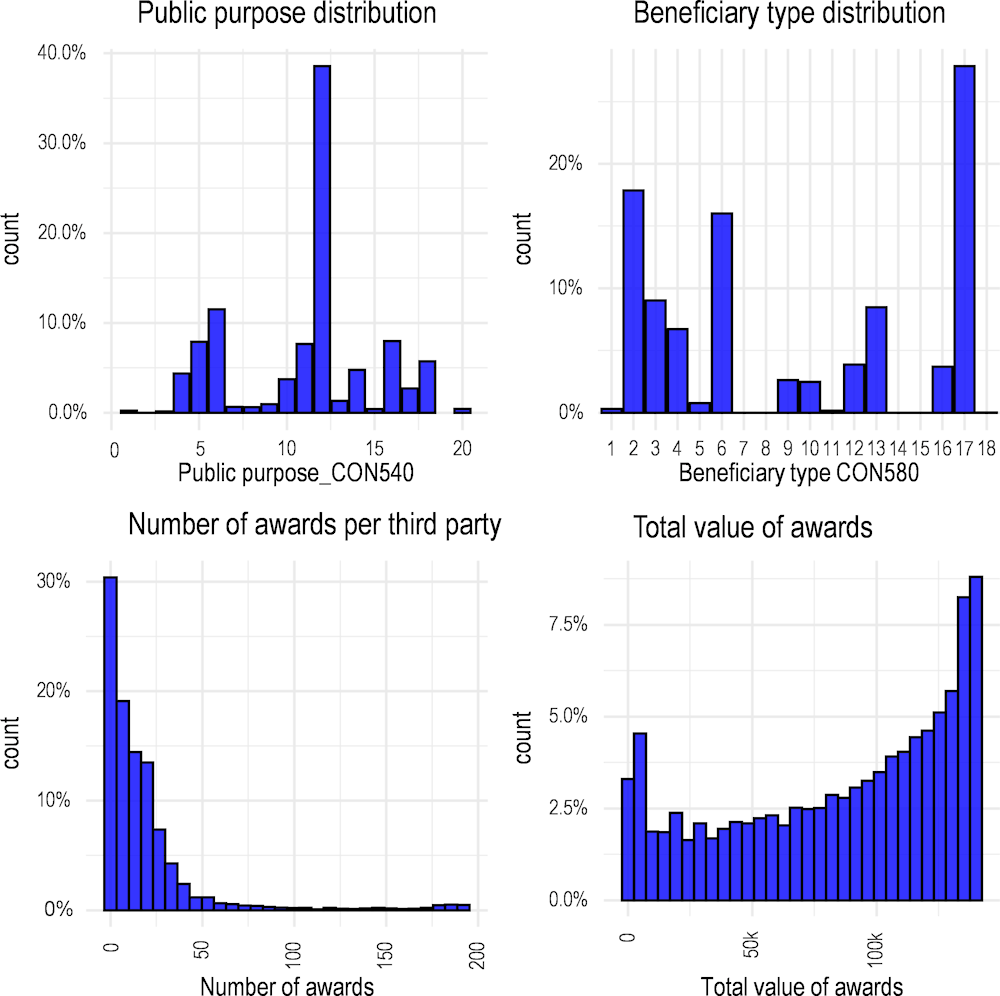
Source: Author
These distributions show that many of the most important variables have rather uneven distributions. For example, the number of awards falls overwhelmingly below 50 with very few beneficiaries having more than 50 grants awarded. Similarly, the public purpose variable has a small number of prevalent categories such as 12 (agriculture). Moreover, the number of awards received by the same beneficiary is not correlated with the total value of awards, meaning that the average amount of distributed awards is relatively low with some awards being of very high value. The next section goes one step further and discusses the impacts of these impactful variables on sanctioning (fraud) probability.
Testing the model on an unseen dataset
The best model trained on the training dataset was tested on unseen data, the test set (30% of the sample). On this test dataset, the best Random Forest model achieved:5
accuracy = 95% (accuracy is the number of correctly predicted labels out of all predictions made), and
recall = 93% (recall is the number of labels that the classifier identified correctly divided by the total number of observations with the same label).
Such results lead us to the conclusion that the model is of high quality. After establishing overall model quality, attention is turned to the impact of individual predictors on sanctioning (fraud) probability. Please note that Random Forest models capture a range of non-linear and interacted effects so interpreting relationships between predictors and the outcome is a multi-faceted and complicated matter. To show the impact of each impactful predictor on model output, the latest machine learning literature was followed and calculated Shapley Additive Explanations values (SHAP) (Lundberg and Lee, 2017[6]) and plotted them. SHAP values help to identify the individual contribution of each feature to the model and their importance for the prediction. The Shapley plot in Figure 2.4 displays the probability of sanctions (i.e. likely fraud) as a function of different values of each impactful predictor.
Figure 2.4. SHAP values: Variable importance and effect direction
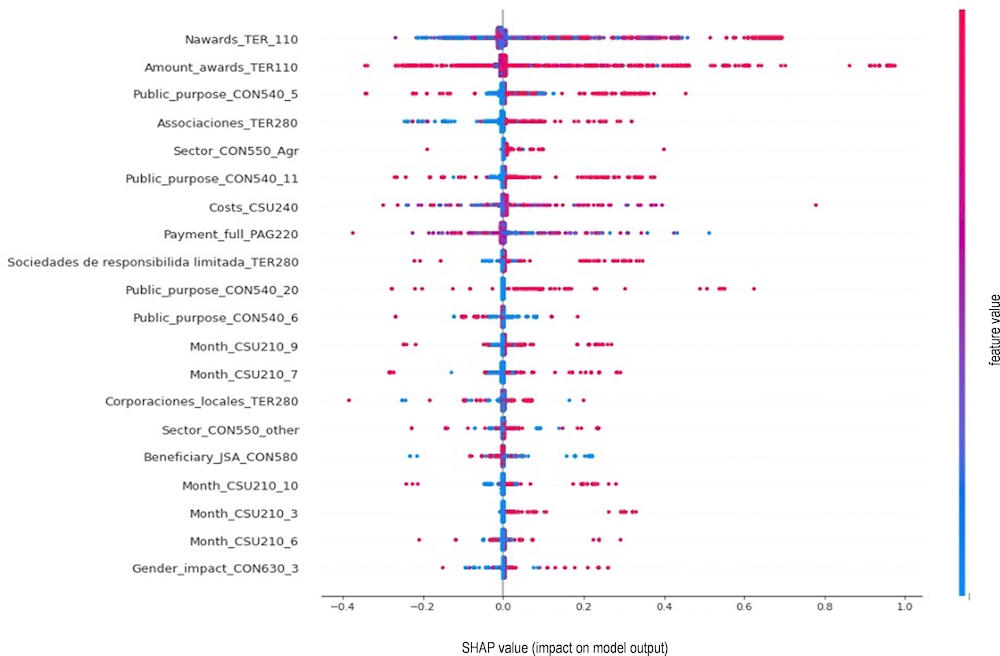
Source: Author
Figure 2.4 highlights that the most significant positive impact on the probability of sanctions is provided by the number of awards, as well as the overall award value received by the same third party. Regarding the rest of the predictors, the probability of sanctions positively correlated with association and limited liability companies among third parties, as well as with the agrarian sector of the economy. Costs of the grant are negatively associated with the probability of being sanctioned, which means that higher prices of the projects are not correlated with higher risks. On the contrary, public purposes of the award, such as culture (11), social services (5), international co‑operation for development and culture (20) and employment promotion (6), are related to higher probability of sanctions. Additionally, grants awarded in September and July are associated with higher chances of sanction, with a similar tendency in October, March and June. More detailed visualisations of important variables’ influence on probability of sanctions (fraud) is shown in Figure 2.5.
Figure 2.5. Using partial dependence plots to depict the impact of selected variables on the probability of fraud
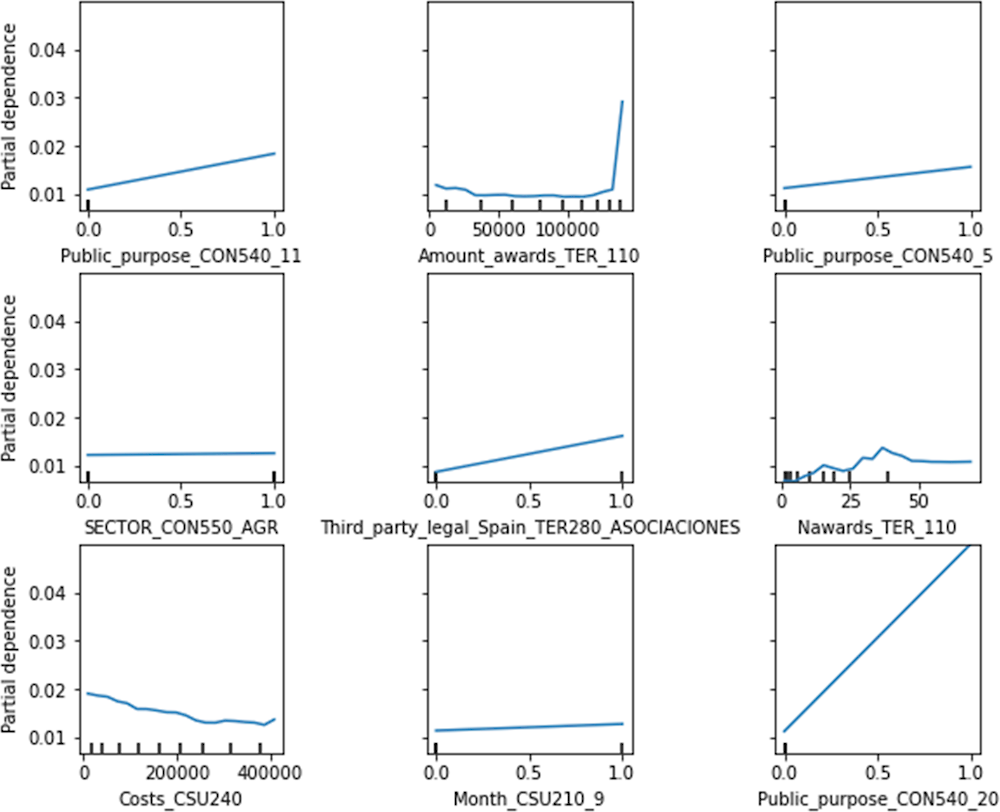
Source: Author
Finalising the list of indicators for the risk model
To complete the description of the risk assessment model, the final list of 29 valid indicators used by the model are described according to six groups (Table 2.3), referring to phases during which the potential fraud might occur, or the features of the participating organisations: competition, selection, execution and monitoring phase; grant giving body and recipient organisation (third party).
Table 2.3. Final list of indicators
Source: Author
Demonstrating results and considerations for further development
The power of the proposed risk assessment methodology is best shown by using the final best Random Forest model to assign a fraud risk score to all awards in 2018 to 2020 with sufficient data quality. Hence, the final distribution of predicted probability of sanctions is presented in Figure 2.6 for the observed 1 050 470 awards. In this broad sample, the model predicts no fraud (sanctions=0) for 1 008 318 awards, while it predicts fraud (sanctions=1) for 42 152 awards using the threshold of 50% sanctions probability for distinguishing between sanctions and non-sanctions.
Figure 2.6. Distribution of predicted probabilities for all awards, award level, 2018-2020
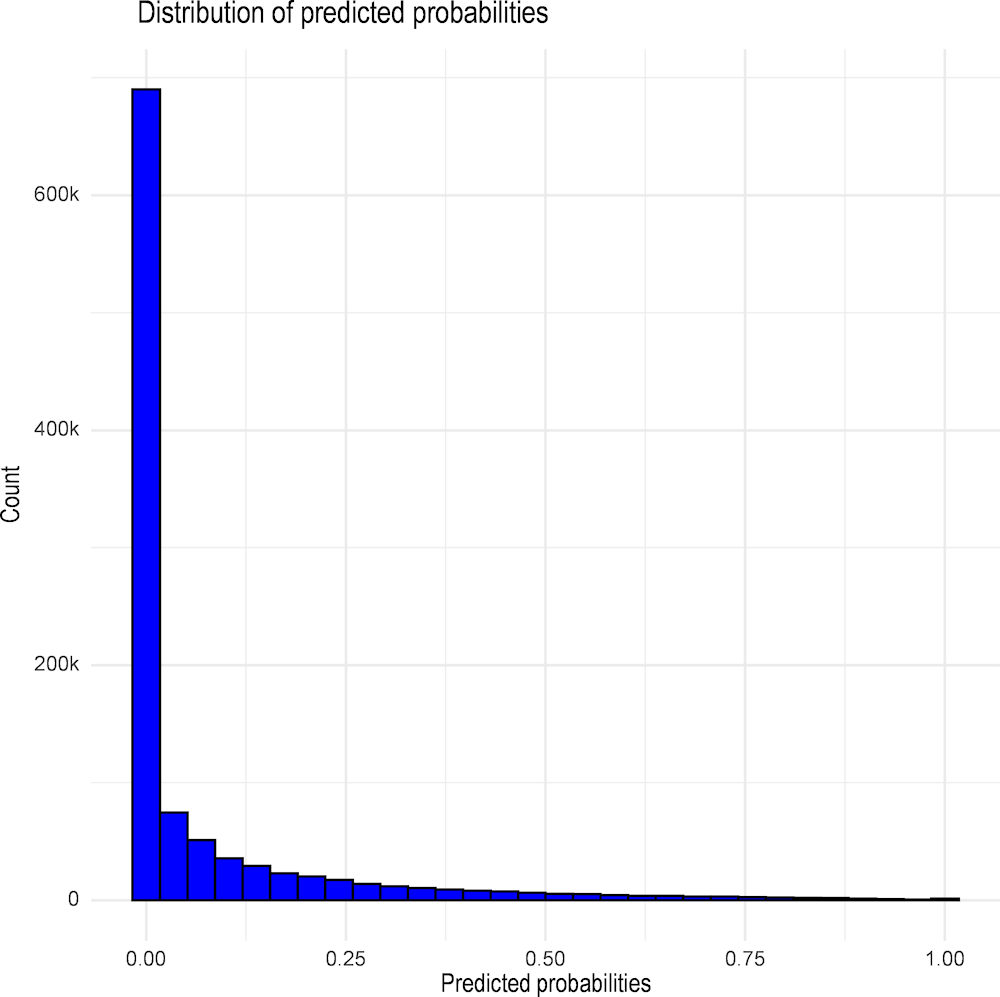
Source: Author
Given that risks tend to cluster on the level of organisations and that investigations often look at all the grants received by an organisation, exploring predicted fraud probabilities on the level of grantees adds further value to the model. In order to offer an overview of this level of aggregation, we show the distribution of predicted fraud risks by grantee with high-risk probabilities in Figure 2.7. It shows that among high-risk grantees, risk probabilities are unevenly distributed. The bulk of high-risk grant recipients have features that indicate a 60% to 70% probability of being fraudulent, and a very small group of organisations at the right tail of the distribution have nearly 100 % likelihood of being fraudulent based on the model. These organisations, the top 10 of which are shown in Table 2.4 below, pose the highest risk and are the most suitable candidates for further review and potential investigation based on the predictive model. In addition to these, the organisations the IGAE targets for further investigation would depend on where it sets its risk threshold, and potentially other factors, such as financial implications (see sub-section “Combine predicted risk scores with financial information”).
Figure 2.7. Distribution of average predicted probabilities for high-risk organizations, third-party level, 2018-2020
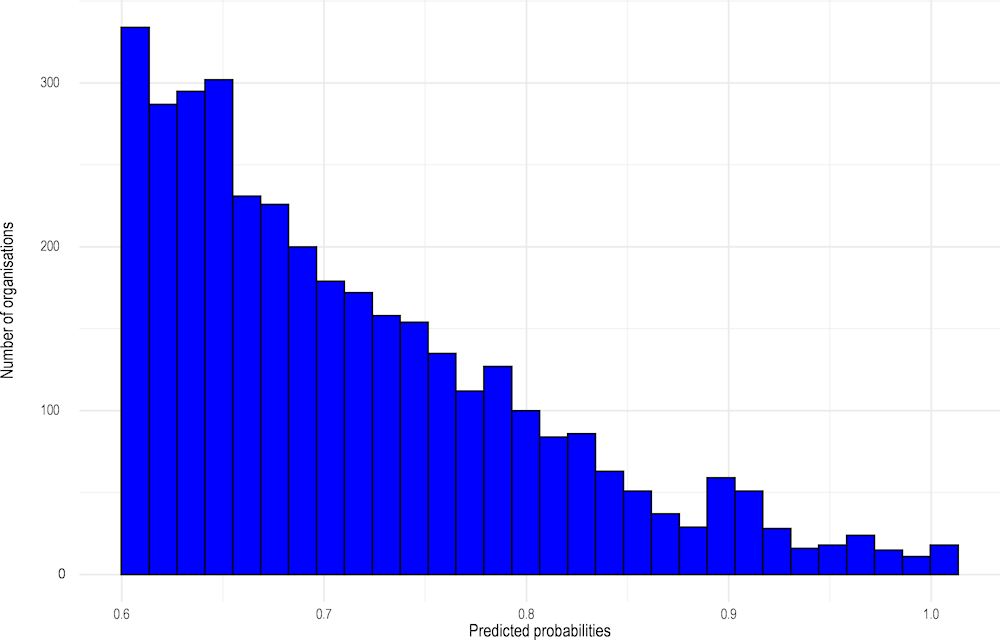
Source: Author
Table 2.4. Top 10 organisations by average value of awards
Source: Author
As expected, the overwhelming majority of awards are estimated by the model as non-risky, yet a few thousands of awards are flagged as risky in addition to the 1 031 observed sanctioned awards. Taking into consideration the most important variables in the model, a closer look is taken at the distribution of predicted fraud probabilities. First, Figure 2.8 shows the distribution of the number of awards received by the same third party in relation to their probabilities of sanction. Interestingly, the model predicts high sanctioning probability for both large and small entities. The majority of awards are located in the left side of the graph, with 0 to 50 awards per third party and relatively even probabilities of being sanctioned for this group of observations. Starting from 50 awards, the probability increases to almost 100%, with a decrease to around 50% when the number gets over 150 awards. This might be explained by the reliability of third parties—if these organisations are shown to be reliable for a long period of time, they receive more awards as trustworthy ones. Whereas for the first 50 awards the process of evaluation is taking place. It is also conceivable that after a certain threshold of 50 awards per third party, the investigations take place more frequently and therefore potentially sanctioned awards are more likely to appear.
Figure 2.8. Distribution of number of awards by probability of sanctions
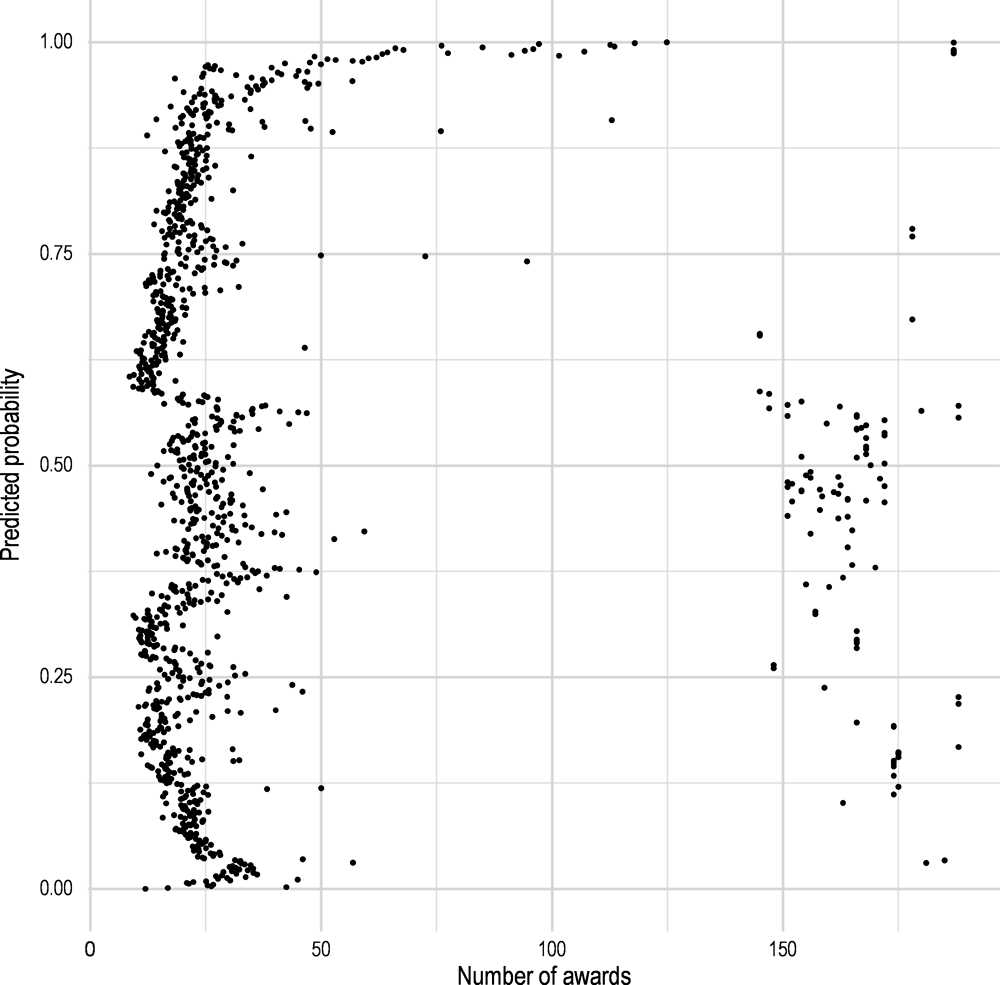
Source: Author
Second, coming to another important variable—public purpose of the call—the distribution of predicted probabilities is presented in Figure 2.9. Two categories show the most extended risk of sanctions: social services (5) and international co‑operation for development and culture (20). Importantly, these are not the most frequent categories among awards - the most frequent one is agriculture (12), which shows the lowest predicted risk.
Figure 2.9. Distribution of public purpose of the call over probability of sanctions
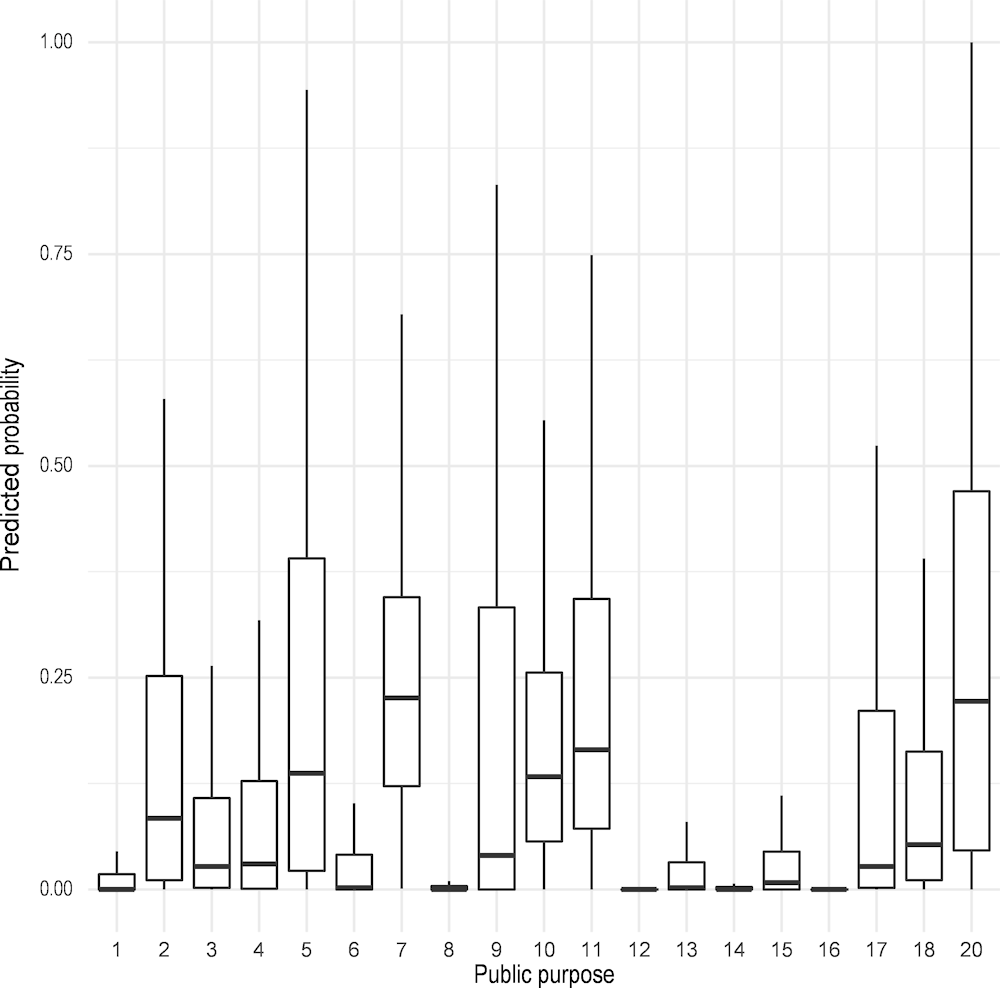
Note: 1 - Justice, 2- Defence, 3 -Citizen Security and Penitentiary Institutions, 4- Other economic benefits, 5-Social Services and Social Promotion, 6-Employment Promotion, 7-Unemployment, 8-Access to housing, 9 -Health, 10 -Education, 11- Culture, 12 - Agriculture, Fishing and Food, 13 - Industry and Energy, 14-Commerce, Tourism and SMEs, 15-Transportation subsidies, 16 - Infrastructure, 17- Research, development and innovation, 18 - Other economic actions, 20 - International co‑operation for development and culture
Source: Author
Third, the legal status of the third party is another important variable identified by the model (Figure 2.10). The second category - associations - showed significant positive impact on the probability of sanctions in the presented model. Two other types of third parties are prone to higher risks too: bodies of the state administration and autonomous communities (1) and public organisations (9). While association is also the most frequent category for this variable, category 1 and 9 are the least frequent ones yet showing the high probability of being sanctioned.
Figure 2.10. Distribution of third parties’ legal status over probability of sanctions
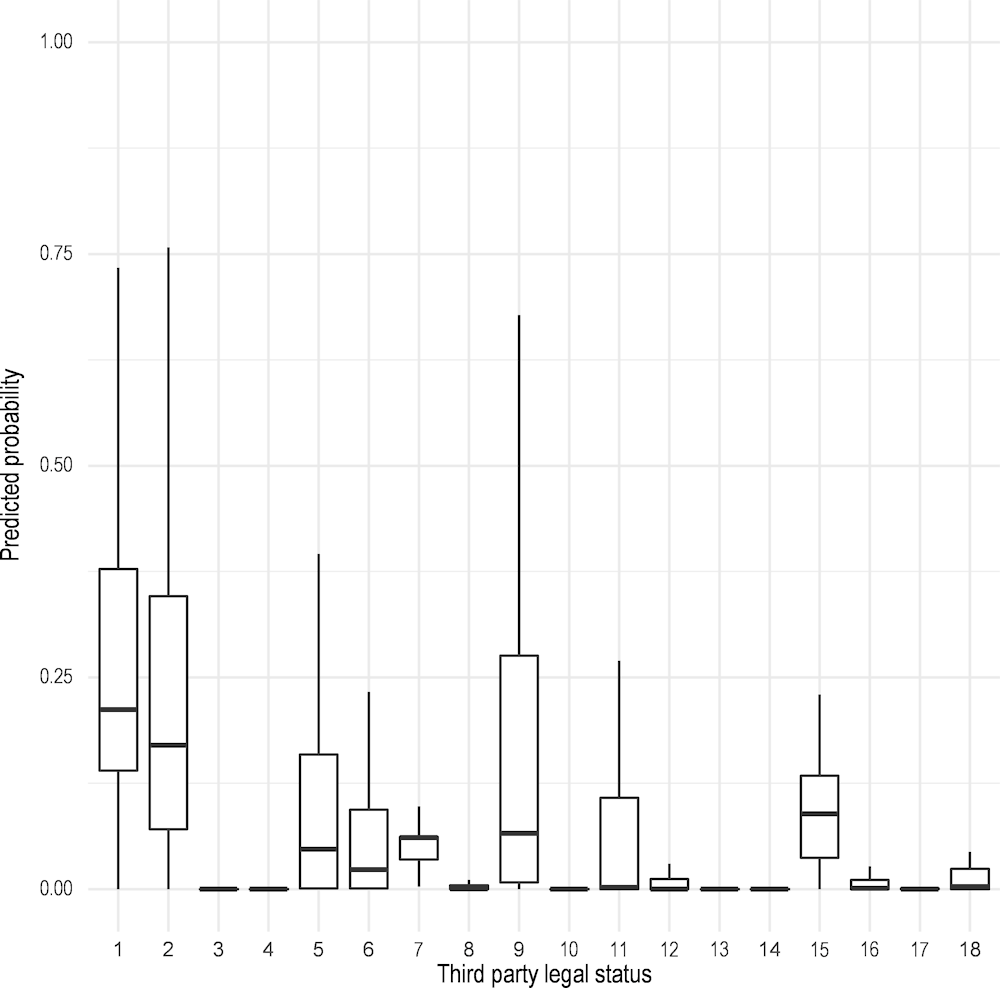
Note: 1 - Bodies of the state administration and autonomous communities, 2 - Associations, 3 - Communities of property, inheritances and other entities without legal personality, 4 - Communities of owners under horizontal property regime, 5 - Religious institutions, 6 - Local corporation, 7 - Foreign entity, 8 - Permanent establishment of non-resident entity in Spanish territory, 9 - Public Organisations, 10 - Other types, 11 - Legal person with identification not generated by Spanish authorities (AEAT or Police), 12 - Anonymous companies, 13 - Civil organisations, 14 - Collective organisations, 15 - Commanded companies, 16 – Co‑operative companies, 17 - Limited liability companies, 18 - Temporary unions of companies
Source: Author
Finally, the total value of the received awards by the third party has also been found to have a significant impact on the probability of sanctions (Figure 2.11). There is a sustained growth in probabilities of sanction starting from EUR 90 000. Additionally there is a divergence in predicted probabilities in between EUR 85 000 and EUR 110 000, which shows that until EUR 110 000 not all of the awards are risky. Finally, for the maximum total value of observed awards (EUR 140 000), the predicted probability of sanctions is distributed evenly between 0.05 and 0.76. This is very similar to what was observed in the distribution of the number of awards - the highest number was associated with even distribution of risks.
Figure 2.11. Distribution of the overall size of awards received by the same third party over probability of sanctions
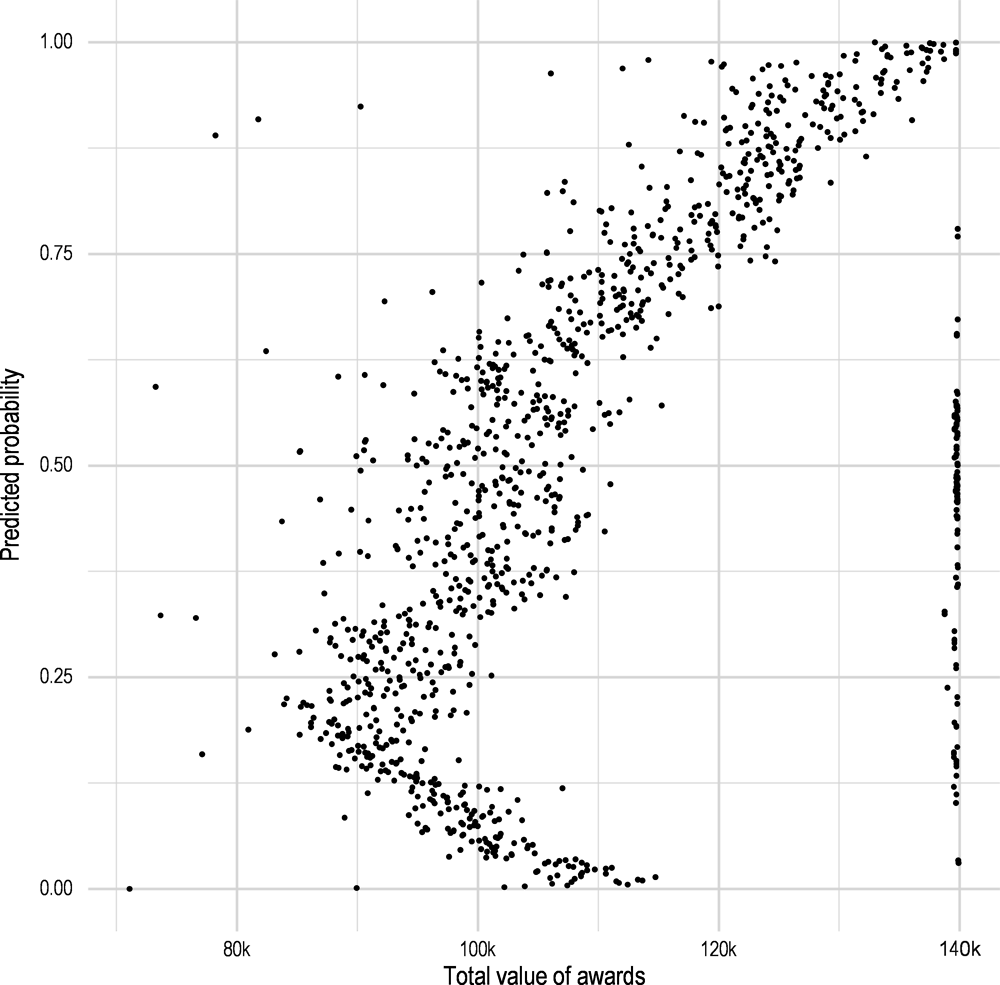
Source: Author
Combine predicted risk scores with financial information
Fraud risks represent the key variable of interest for the IGAE and hence serve as the main dependent variable for the model described so far. Nevertheless, they only represent one of the key dimensions according to which investigative targets can be selected. A second key dimension that could be considered is the total value of the grant as an indication of the potential financial impact of fraud for the Spanish government. Combining the estimated fraud risk scores with the total value of the award allows decision makers and investigators to simultaneously consider the prevalence of risks and their likely financial implications (Fazekas, M., Ugale, G, & Zhao, A., 2019[7]). The simplest approach to look at these 2 dimensions simultaneously is to draw a scatterplot with these 2 variables also highlighting their average values (Figure 2.12). The top right quadrant includes those awards which not only have high risk but also have high award values. This is the group of greatest interest for the IGAE’s future investigations as they are most likely to include fraudulent grants with large financial implications.
Figure 2.12. The distribution of awards by predicted risk score and total award value
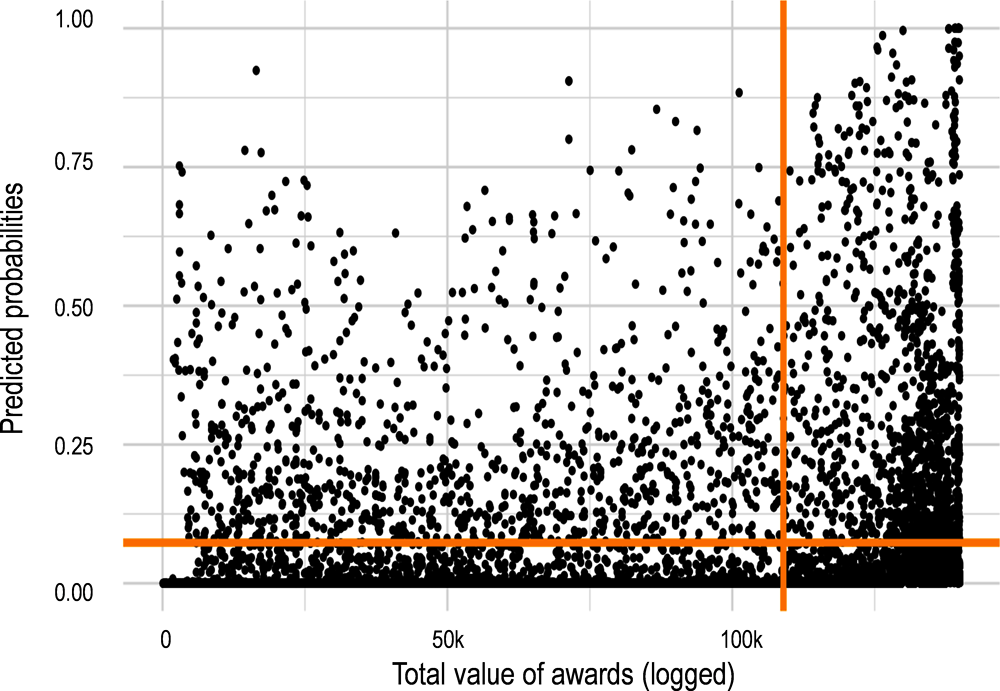
Source: Author
Establish a ready-made dataset for future fraud risk detection
In order to further improve the data-driven fraud risk assessment framework of IGAE, a number of short and medium term reforms could be implemented which would enhance the quality and scope of data underlying the risk models. The OECD’s development of a risk model has already helped the IGAE to advance in addressing some of these issues, and the resulting dataset from the OECD’s work can be a starting point for the IGAE. Nonetheless, datasets are not static and new data sources may become available. Therefore, these points are relevant outside of the context of this project.
First, existing data could be better and faster combined into a single dataset ready for fraud risk modelling. Currently, almost all the datasets cover different units of analysis such as awards, calls or organisations. In order for the IGAE to merge them, each dataset should be aligned to the same level with unique IDs to avoid redundant multiplication of observations in the merged dataset. During data processing for this report, the data was transformed from long to wide format whenever it was needed. Yet this approach suffers from a major drawback, that is a high missing rate for IDs without multiple observations per single ID. To solve this problem aggregation is needed, especially for factor variables which cannot be calculated as means or medians.
Second, lowering missing rates on all variables collected by IGAE is paramount. As discussed in Chapter 1, defining data quality standards and enforcing them, in collaboration with the relevant data owners, would assure that there are no variables with high missing rates such as 40-50%. Third, some datasets (for instance, on projects) consist of a very small number of observations, which prevents their analysis in conjunction with the main dataset (i.e. when matched they result in a very high missing rate). Similarly, data on third parties is very limited and needs further enhancement.
Expand the IGAE’s use of indicators across the grant cycle
As noted, the final list of indicators includes 29 variables. These variables are mostly categorical, although there are several numeric variables, such as costs and payments. Most of the variables analysed are descriptive due to the data available. There is limited data that can provide insights into the behaviours of organisations and people, such as conflicts of interests among actors who receive or benefit from the grants. This is one of the largest gaps in the current data available to the IGAE and is one of the most limiting factors on its risk analysis, regardless of the methodology taken. Table 2.5 shows additional behavioural indicators that could be used for fraud risk assessment that span the grant cycle and could help to refine the IGAE’s risk model.
Table 2.5. Behavioural indicators for assessing fraud risks for each phase of the grant cycle
Source: Author
There are a variety of sources and examples that can support the IGAE in refining its risk indicators. In the European Union, the European Anti-Fraud Office (OLAF) created a Compendium of Anonymised Cases in 2011 that still has relevance today. The Compendium lists the results of OLAF’s investigations and includes information about financial frauds. Two high-risk phases of potential fraudulent behaviour could be identified—the selection phase and execution phase. During the selection phase, OLAF encouraged a close inspection of supporting declarations and official documentations, as well as to make sure the final beneficiary was not set up or created immediately prior to publication of the subsidy. During the execution phase, OLAF suggested consideratoin of the financial difficulties of the contractor, single big transactions covering almost half of all project costs, as well as the use of subsidies for other purposes (European Anti-Fraud Office (OLAF), 2011[8]). The Compendium illustrates the reality that a lot of fraud is simply recycled versions of similar schemes. Indeed, in its 32nd Annual Report on the protection of the European Union’s financial interests — Fight against fraud-2020, the European Commission noted that among the fraudulent irregularities related to healthcare infrastructure and the COVID-19 pandemic, the most commonly detected issues concerned supporting documentation (European Commission, 2021[9]). Box 2.2 provides additional insights from the experience of the Grant Fraud Committee of the Financial Fraud Enforcement Task Force, which was set up to tackle fraud in the wake of the 2008 financial crisis.
Box 2.2. The Grant Fraud Committee of the U.S. Financial Fraud Enforcement Task Force
In the United States, the Grant Fraud Committee of the Financial Fraud Enforcement Task Force identified several key areas to monitor and identify fraudulent activities:
structure of recipient organisation and grant program
payment requests or drawdown of grunt funds
monitoring reports and activities
transaction-level activities
contracts and consultants.
Among the first category, the Grant Fraud Committee suggested monitoring the design of the project, as well as financial viability of the recipient, internal control, organisations’ personnel and potential conflicts of interest. In regards to payment requests, the attention should be paid towards timing of grant drawing, as well as justifying documentation, exceeding expenditures and rounding the numbers for grants drawing. While performing monitoring activities, the responsiveness and co‑operation of the recipient is a key indicator, as well as presence of internal controls and audit history of the company. When it comes to transaction-level activities, excessive, unusual and unmonitored transactions could be marked as potential risks, as well as double funding (more than one grant covering the same project). Finally, in regards to contracts and consultants, the Grant Fraud Committee suggests looking at related party transactions, spending on non-specific consultants and grants recipients with deficiencies in their procurement systems. In case of data monitoring, Grant Fraud Committee (2012) identifies the following frauds risks:
excessive number and value of payments to a single vendor
payments to unapproved vendors
transactions that bypass normal review procedures, or are otherwise unmonitored or reviewed by another person
purchases that appear illogical considering the nature of the grant programme
expenditures outside of the allowable project period
checks and transactions that occur several times per month
checks issued to multiple vendors at the same address.
Note: In 2018, the Task Force on Market Integrity and Consumer Fraud replaced the Financial Fraud Enforcement Task Force.
Invest in continuous improvement of the risk model
As the validity of data-driven models depends on the completed sanctioning activities, if sanctions missed out on relevant fraud schemes or resulted in a biased sample of investigations, any risk assessment model would also be biased. Hence, obtaining a truly random sample of investigations and sanctions is of central importance. To this end, the IGAE could select a percentage of the investigated cases each year using the IGAE’s traditional sampling techniques, or a data-driven selection method such as the one presented above. The remainder of the investigated cases could be picked by complete random selection. This approach would strike a balance between maximising the utility of investigative resources through better targeting, while also investing in future improvements of the risk assessment model by providing a better training sample. It would also give the IGAE a better sense of how the model is performing. As this effort was a proof-of-concept, additional technical steps could be considered:
Improve the quality of variables in the full dataset in order to be able to include more indicators in the model and hence improve model quality.
Take into consideration the unbalanced nature of classes in the dependent variable (positive/negative): use PU bagging techniques to avoid inaccuracy in modelling.
Repeat the modelling exercise regularly as new data, including sanctions as well as awards, become available in order to keep the risk assessment up-to-date.
Analytical models do not paint a complete picture and can have biases as they learn from past enforcement action (see Chapter 1). The IGAE could supplement the models with qualitative methods and expert judgement. This allows fraud specialists at IGAE to contribute with their expert understanding of fraud schemes, latest events, and the broader context.
While models may be vulnerable to biases themselves, they can also help to control for biases. Specifically, data-driven sample selection, including those that use machine learning, not only would help the IGAE to maximise the efficacy of control resources, but it would also help to correct for some biases in the learning dataset. For example, if fraud types which are not covered by investigations are known, their features can be manually entered into the database to provide sufficient input for the algorithm to learn from. Moreover, if the selection of investigations in the sanctions dataset emphasises certain variables, say the size of the grant, under-sampling large grants and oversampling small grants can counteract biased selection of investigated cases.
Consider network analyses and making use of a broader set of methodologies
Network and data science techniques have been increasingly used to study economic crime such as corruption, fraud, collusion, organised criminality, or tax evasion to mention a few major areas (Wachs, Fazekas and Kertész, 2020[11]). Exploring networks without advanced analytics already promises great advantages for fraud detection such as tracing potential conflicts of interest (see Box 2.3).
Box 2.3. Using data to investigate conflict of interest
When the individuals behind public and private organisations parties to the grant making and implementation process are known, a range of potential conflicts of interest relationships can be uncovered. While in-depth investigations can reveal such relationships, risk screening is greatly facilitated by matching large-scale datasets containing: 1) all public officials playing a significant role in preparing, assessing, awarding, and monitoring grants and subsidies; and 2) all private officials playing a significant role in the companies which submit grants applications, receive and implement grants.
Gathering, cleaning and linking such datasets and maintaining the underlying data pipelines involve can come with considerable costs. However, once such a dataset and a simple graphical interface is available, which is the case for the EU’s ARACHNE tool, it can greatly speed up the screening and investigation of risky relationships among grant makers and grant recipients. For example, it is possible to quickly and efficiently look at projects, the implementing contractors and the persons participating in the preparation of the call and assessment of applications.
Figure 2.13. Visualising conflicts of interest
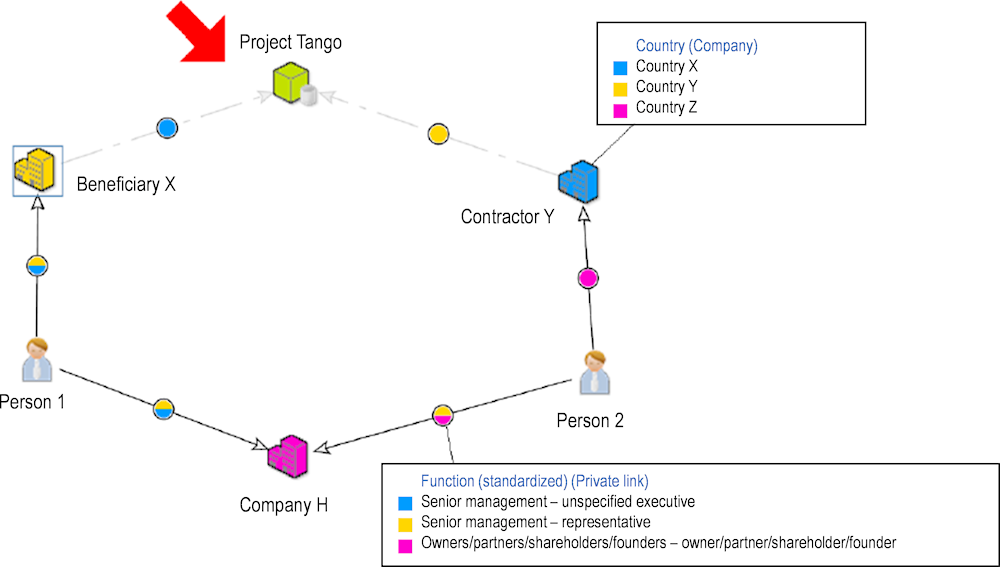
Source: (European Union, 2016[12])
Analysing large-scale networks of contractual or personal relations can reveal hidden patterns which serve as risk indicators on their own or complement other risk indicators (Fazekas and Tóth, 2016[13]); (Fazekas and Wachs, 2020[14]). For example, tendering risk indicators such as the incidence of single bidding in public procurement can be superposed over clusters of linked buyers and suppliers in public procurement to identify high risk cliques. Figure 2.14 below shows a visualisation of the public procurement contracting market of buyers and suppliers in Hungary. Such diagrams provide a visual snapshot of the data that signal potential high-risk relationships for further investigation. For instance, the red lines highlight a higher than average single bidding rate in that relationship. In addition, there is a cluster of high corruption risk actors in the top (i.e. dense organisational contracting relationships coinciding with high single bidding rates in those relationships).
Figure 2.14. Hungarian public procurement contracting market of buyers and suppliers in 2014

The IGAE could compile relevant datasets such as company ownership data and link them to its core grants and subsidies data in order to make use of such network analytic techniques. As individuals move across the private and public sectors and there are a range of other ways grantees can establish connections to grant making bodies, tracing overt or hidden networks offers a key tool for improving fraud risk assessment in Spain. As discussed, this is one area where the IGAE currently has gaps in its data, and so use of network analyses will also depend on the ability of the IGAE to address these gaps. Recent developments in Spain suggest that improvements are already underway. For instance, in May 2020, the IGAE and the General Treasury of Social Security (Tesorería General de la Seguridad Social, TGSS) signed an agreement on the transfer of information, establishing more collaborative conditions for financial control of subsidies and public aid. The agreement stipulates direct access to the TGSS databases to facilitate the IGAE’s work to detect fraud and irregularities (Ministry of the Presidency of Spain, 2021[15]). Advancing with similar agreements with other public and private entities, particularly to obtain company data and data that reflects behavioural indicators as discussed above, would be critical inputs for strengthening future risk models.
Conclusion
This chapter presents a proof-of concept for the IGAE to enhance its approach for assessing fraud risks in public grant data, drawing from leading practices in analytics. The process of developing the risk model led to a number of insights about the IGAE’s current capacity for analytics, as well as data management and ensuring the quality of data for purposes of assessing fraud risks, as noted in Chapter 1. The development of the risk model also demonstrated gaps in fraud risk indicators and databases that, if addressed, could help the IGAE to improve its fraud risk assessments regardless of the specific methodology it chooses. In particular, the IGAE could incorporate additional behavioural indicators for assessing fraud risks across each phase of the grant cycle, drawing from international experiences and academic literature. In addition, the IGAE could compile company data and adopt the methodologies described for conducting network analyses as a means for identifying conflicts of interest, drawing from the procurement examples in this chapter.
The chapter also covers a number of technical considerations for the IGAE if it decides to adopt a machine learning model. Much of the heavy lifting has been done as part of this pilot in terms of data processing and data cleaning. The IGAE now has a working dataset to use for fraud risk analysis that is already an improvement on what it had available prior to the projects. The features and limitations of the IGAE’s data drove much of the rationale for selecting the approach described. While it has limitations due to the quality of the learning datasets and features of the grant data, the methodology was designed to minimise false positives and false negatives, and overall, it has high predictive power for identifying potential fraud in Spain’s public grant data. While implementing this approach requires additional capacities, detailed in Chapter 1, the proof-of-concept successfully demonstrates what is possible with a modest investment and provides a basis for the IGAE to adopt a truly data-driven fraud risk assessment. Chapter 3 explores further how the IGAE can improve the accuracy of the model by integrating additional data that can be used for detecting possible fraud.
References
[1] Breiman, L. (2001), “Random Forests”, Machine Learning, Vol. 45/1, pp. 5-32, https://link.springer.com/article/10.1023/a:1010933404324.
[2] Elkan, C. and K. Noto (2008), “Learning classifiers from only positive and unlabeled data”, KDD ’08: Proceedings of the 14th ACM SIGKDD international conference on Knowledge discovery and data mining, pp. 213-220, https://dl.acm.org/doi/10.1145/1401890.1401920.
[8] European Anti-Fraud Office (OLAF) (2011), Compendium of Anonymised Cases, https://ec.europa.eu/sfc/sites/default/files/sfc-files/OLAF-Intern-2011.pdf (accessed on 13 August 2021).
[9] European Commission (2021), 32nd Annual Report on the protection of the European Union’s financial interests: Fight against fraud 2020, https://ec.europa.eu/anti-fraud/sites/default/files/pif_report_2020_en.pdf (accessed on 13 August 2021).
[12] European Union (2016), Arachne, Be Distinctive, http://www.ec.europa.eu/social/BlobServlet?docId=15317&langId=en (accessed on 13 August 2021).
[7] Fazekas, M., Ugale, G, & Zhao, A. (2019), Analytics or Integrity: Data-Driven Decisions for Enhancing Corruption and Fraud Risk Assessments, OECD Publishing, Paris, https://www.oecd.org/gov/ethics/analytics-for-integrity.pdf.
[13] Fazekas, M. and I. Tóth (2016), “From Corruption to State Capture: A New Analytical Framework with Empirical Applications from Hungary”, Political Research Quarterly, Vol. 69/2, pp. 320-334, https://scholar.google.com/citations?view_op=view_citation&hl=en&user=H1FpS2AAAAAJ&citation_for_view=H1FpS2AAAAAJ:SP6oXDckpogC.
[14] Fazekas, M. and J. Wachs (2020), “Corruption and the network structure of public contracting markets across government change”, Politics and Governance, Vol. 8/2, pp. 153-166, https://scholar.google.fr/citations?view_op=view_citation&hl=fr&user=PY3YH2kAAAAJ&citation_for_view=PY3YH2kAAAAJ:ZeXyd9-uunAC.
[10] Financial Fraud Enforcement Task Force (2012), Reducing Grant Fraud Risk: A Framework For Grant Training, https://www.oversight.gov/sites/default/files/oig-reports/Grant-Fraud-Training-Framework.pdf.
[5] James, G. et al. (2015), Chapter 8, https://link.springer.com/book/10.1007/978-1-4614-7138-7.
[3] Li, C. and X. Hua (2014), “Towards positive unlabeled learning”, International Conference on Advanced Data Mining and, pp. 573–587.
[6] Lundberg, S. and S. Lee (2017), A unified approach to interpreting model predictions, https://scholar.google.com/citations?view_op=view_citation&hl=en&user=ESRugcEAAAAJ&citation_for_view=ESRugcEAAAAJ:dfsIfKJdRG4C.
[15] Ministry of the Presidency of Spain (2021), Resolution of May 26, 2020, of the Undersecretariat, which publishes the Agreement between the General Treasury of Social Security and the General Intervention of the State Administration, on the transfer of information, https://www.boe.es/diario_boe/txt.php?id=BOE-A-2020-5748 (accessed on 4 July 2021).
[4] Mordelet, F. and J. Vert (2014), “A bagging SVM to learn from positive and unlabeled examples.”, Pattern Recognition Letters, Vol. 37, pp. 201-209, https://www.sciencedirect.com/science/article/pii/S0167865513002432.
[11] Wachs, J., M. Fazekas and J. Kertész (2020), “Corruption risk in contracting markets: a network science perspective”, International Journal of Data Science and Analytics, pp. 1-16, https://scholar.google.fr/citations?view_op=view_citation&hl=fr&user=PY3YH2kAAAAJ&citation_for_view=PY3YH2kAAAAJ:QIV2ME_5wuYC.
Notes
← 1. For cleaning and merging the data, R 3.6.3 was used with the following package: readxl, tidyverse (dplyr), flipTime, tibble, data.table. For modeling both R 3.6.3 and Python3 softwares were used for different stages of analysis. To build random forests in R, randomForest and xgboost packages were used. For positive unlabeled learning in Python3 libraries pandas, numpy, baggingPU (module BaggingClassifierPU), sklearn.tree (modules DecisionTreeClassifier, DecisionTreeRegressor, precision_score, recall_score, accuracy_score, train_test_split, RandomForestClassifier) were employed.
← 2. Names of these datasets include BDNS_CONV_ACTIVIDADES, BDNS_CONV_ANUNCIOS, DNS_CONV_FONDOS_CON690, BDNS_CONV_OBJETIVOS_CON503, BDNS_CONV_TIPOBEN_CON590, BDNS_CONV_REGIONES_CON570, BDNS_CONV_INTRUMENTOS_CON560.
← 3. Names of these datasets include BDNS_PROYECTOS, BDNS_PAGOS, BDNS_REINTEGRO, BDNS_DEVOLUCIONES.
← 4. Names of these datasets include BDNS_INHABILITACIONES, BDNS_SANCIONES and BDNS_TERCERO_ACTIVIDADES_TER320.
← 5. The very high accuracy rate of 95% is largely due to the fact that the sample is imbalanced, that is most cases are negative (non-sanctioned) and the model hence relatively easily can classify the bulk of the sample as non-sanctioned. However, it is harder for the model to predict sanctioned cases correctly given that they are so much more rare. For this case, recall score is more helpful to evaluate the model performance, as it calculates the number of members of a class that the classifier identified correctly divided by the total number of members in that class.