In diesem Kapitel werden die Möglichkeiten der künstlichen Intelligenz (KI) in verschiedenen Bereichen aufgezeigt, in denen eine rasche Einführung dieser Technologien zu beobachten ist. Dazu gehören Verkehr, Landwirtschaft, Finanzwirtschaft, Marketing und Werbung, Wissenschaft, Gesundheitswesen, Strafverfolgung, Sicherheit, der öffentliche Sektor sowie Anwendungen der erweiterten und virtuellen Realität. In diesen Bereichen können KI-Systeme genutzt werden, um in riesigen Datenmengen Muster zu erkennen und komplexe, interdependente Systeme zu modellieren. Ziel ist es, die Effizienz der Entscheidungsfindung zu steigern, Kosten einzusparen und eine bessere Ressourcenallokation zu ermöglichen. Der Abschnitt über KI im Verkehrswesen stammt vom Internet Policy Research Institute des Massachusetts Institute of Technology. Mehrere andere Abschnitte basieren auf Arbeiten, die in verschiedenen OECD-Gremien durchgeführt wurden, z. B. im Ausschuss für digitale Wirtschaft und in seiner Arbeitsgruppe Sicherheit und Datenschutz, im Ausschuss für Wissenschafts- und Technologiepolitik, in der E-Leaders-Initiative des Ausschusses für öffentliche Governance sowie im Ausschuss für Verbraucherpolitik und in seiner Arbeitsgruppe Sicherheit von Verbraucherprodukten.
Künstliche Intelligenz in der Gesellschaft

3. KI-Anwendungen
Abstract
KI im Verkehr: autonome Fahrzeuge
In allen Wirtschaftsbereichen entwickeln sich Systeme der künstlichen Intelligenz (KI). Besonders tiefgreifend sind indessen die Veränderungen im Verkehrssektor, insbesondere mit dem Aufkommen selbstfahrender bzw. autonomer Fahrzeuge.
Wirtschaftliche und soziale Auswirkungen autonomer Fahrzeuge
Der Verkehr ist einer der wichtigsten Wirtschaftssektoren im OECD-Raum. 2016 machte er 5,6 % des Bruttoinlandsprodukts des OECD-Raums aus (OECD, 2018[1]).1 Dank Einsparungen aufgrund geringerer Unfallzahlen, weniger Verkehrsstauungen und anderer Vorteile könnte das autonome Fahren (AF) erhebliche wirtschaftliche Auswirkungen haben. Schätzungen zufolge könnten in den Vereinigten Staaten durch autonomes Fahren bei einer Adoptionsrate von 10 % jährlich 1 100 Leben gerettet und Einsparungen von 38 Mrd. USD erzielt werden. Bei einer Adoptionsrate von 90 % könnten jährlich sogar 21 700 Leben gerettet und 447 Mrd. USD gespart werden (Fagnant, D. und K. Kockelman, 2015[2]).
Neuere Untersuchungen für die Schweiz haben ergeben, dass die Kosten pro Kilometer für verschiedene Verkehrsmittel mit und ohne Fahrzeugautomatisierung erheblich voneinander abweichen (Bösch et al., 2018[3]). Die Ergebnisse dieser Untersuchungen deuten darauf hin, dass bei Taxis die größten Kosteneinsparungen erzielt würden. Bei Personen mit Privatfahrzeugen ist mit geringeren Kosteneinsparungen zu rechnen (Abbildung 3.1). Die Einsparungen bei Taxis sind erwartungsgemäß großenteils auf den Wegfall der Fahrervergütungen zurückzuführen.
Abbildung 3.1. Vergleich der Kosten verschiedener Verkehrsmittel mit und ohne AF-Technologie
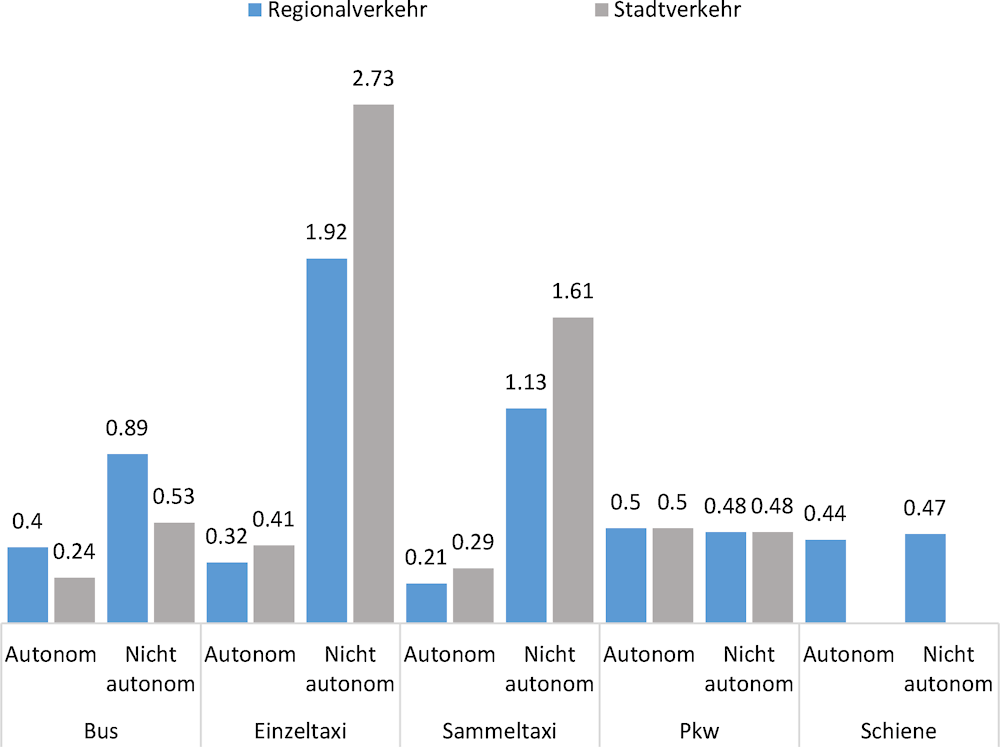
Quelle: Nach Bösch et al. (2018[3]), “Cost-based analysis of autonomous mobility services“, https://doi.org/10.1016/j.tranpol.2017.09.005.
Marktentwicklung
Der Verkehrssektor befindet sich aufgrund von drei bedeutenden aktuellen Marktveränderungen im Wandel: der Entwicklung von AF-Systemen, dem Aufkommen von Ridesharing-Diensten und der Einführung von Elektrofahrzeugen. Zwei Trends machen es traditionellen Automobilherstellern dabei schwer, eine klare Strategie festzulegen. Erstens erfreuen sich Ridesharing-Dienste zunehmender Beliebtheit, vor allem bei jüngeren Generationen. Zweitens bestehen Zweifel an der langfristigen Tragfähigkeit des traditionellen Konzepts des eigenen Autos. Premium-Hersteller experimentieren bereits mit neuen Geschäftsmodellen wie Abonnement-Services. Als Beispiele wären „Access by BMW“, „Mercedes Collection“ und „Porsche Passport“ zu nennen. Gegen eine monatliche Pauschalgebühr können die Kunden dieser Programme nach Belieben das Fahrzeug wechseln.
Technologieunternehmen, von großen multinationalen Unternehmen bis hin zu kleinen Start-ups, steigen zunehmend in AF-Systeme, Ridesharing-Dienste oder Elektrofahrzeuge ein oder kombinieren diese Elemente. Laut jüngsten Schätzungen von Morgan Stanley könnte die Alphabet-Tochtergesellschaft Waymo bis zu 175 Mrd. USD wert sein, größtenteils aufgrund ihres Potenzials im Bereich autonome Speditions- und Lieferdienste (Ohnsman, 2018[4]). Das junge Start-up-Unternehmen Zoox, das sich auf KI-Systeme für städtische Ballungsgebiete konzentriert, hat bereits 790 Mio. USD Kapital eingeworben. Damit hat es einen geschätzten Marktwert von 3,2 Mrd. USD2 erreicht, ohne jemals Umsätze erwirtschaftet zu haben (vgl. auch den Abschnitt „Private-Equity-Investitionen in KI-Start-ups“ in Kapitel 2). Neben Technologieunternehmen investieren auch traditionelle Automobilhersteller und Zulieferer in KI-basierte Fahrzeugtechnologien.
Angesichts der Komplexität von AF-Systemen konzentrieren sich die Unternehmen in der Regel auf ihre jeweilige Fachkompetenz und arbeiten dann mit Firmen zusammen, die sich auf andere Bereiche spezialisiert haben. Waymo ist eines der führenden Unternehmen im Bereich autonomes Fahren, da es sich auf große Datensätze und maschinelles Lernen (ML) spezialisiert hat. Es baut jedoch keine eigenen Fahrzeuge, sondern setzt auf Partner wie General Motors (GM) und Jaguar (Higgins, T. und C. Dawson, 2018[5]).
Auch große Automobilhersteller haben sich mit kleineren Start-ups zusammengeschlossen, um Zugang zu Spitzentechnologie zu erhalten. So kündigte Honda im Oktober 2018 an, 2,75 Mrd. USD in das zu GM gehörende Roboterwagen-Start-up Cruise Automation zu investieren (Carey, N. und P. Lienert, 2018[6]). Ridesharing-Unternehmen wie Uber haben ebenfalls erheblich in autonome Fahrzeuge investiert und sind Partnerschaften mit führenden technischen Universitäten eingegangen (CMU, 2015[7]). Dies hat jedoch Fragen der Haftung bei Unfällen aufgeworfen, insbesondere wenn mehrere Akteure für verschiedene Aspekte zuständig sind.
Die Vielfalt der Marktteilnehmer, die in AF-Kapazitäten investieren, zeigt sich in der Zahl der Patente, die von verschiedenen Unternehmensgruppen in diesem Bereich angemeldet wurden (Abbildung 3.2). Große Automobilhersteller investieren besonders stark in geistiges Eigentum, dicht gefolgt von Automobilzulieferern und Technologieunternehmen.
Abbildung 3.2. Patentanmeldungen im Bereich autonomes Fahren nach Unternehmen, 2011-2016
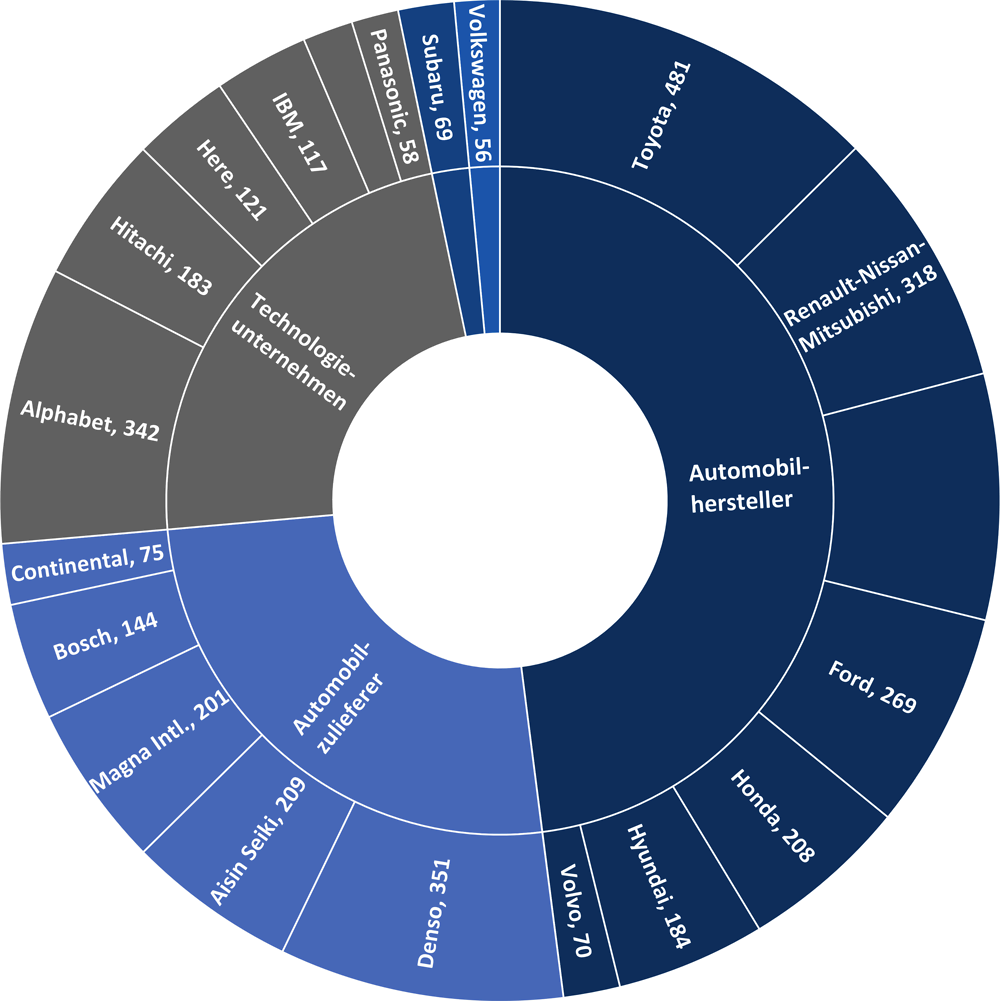
Quelle: Nach Lippert et al. (2018[8]), „Toyota’s vision of autonomous cars is not exactly driverless“, https://www.bloomberg.com/news/features/2018-09-19/toyota-s-vision-of-autonomous-cars-is-not-exactly-driverless.
Technologieentwicklung
Autonome Fahrzeuge verfügen über neue Sensorsysteme und Verarbeitungskapazitäten, die zu neuen Komplexitäten im Extraktions-, Transformations- und Ladeprozess ihrer Datensysteme führen. Da in allen Schlüsselbereichen des autonomen Fahrens viel investiert wird, floriert die Innovationstätigkeit. So können beispielsweise weniger kostspielige Lidar-Systeme (light detection and ranging) die Umgebung abbilden. Neue Technologien des maschinellen Sehens können zudem die Augenbewegungen und die Konzentration des Fahrers verfolgen und so feststellen, wenn er abgelenkt ist. Nach dem Einlesen der Daten und ihrer Verarbeitung kommt dank KI nun ein weiterer Schritt hinzu: In Sekundenschnelle werden operative Entscheidungen getroffen.
Fortschritte bei der Entwicklung autonomer Fahrzeuge werden in der Regel nach einem sechsstufigen Standard gemessen, der von der Society of Automotive Engineers (SAE) herausgegeben wurde (ORAD, 2016[9]). Die Stufen können folgendermaßen zusammengefasst werden:
Stufe 0 (keine Automatisierung): Der menschliche Fahrer kontrolliert alles. Es gibt keine automatische Lenkung, Beschleunigung, Bremsung usw.
Stufe 1 (Fahrerassistenz): Es gibt eine Grundautomatisierung, der Fahrer behält jedoch die Kontrolle über die meisten Funktionen. Der SAE zufolge können auf dieser Stufe Querführung (Lenkung) oder Längsführung (z. B. Beschleunigung) autonom erfolgen, nicht jedoch gleichzeitig.
Stufe 2 (Teilautomatisierung): Sowohl die Quer- als auch die Längsführung werden autonom übernommen, z. B. mit einem Abstandsregelautomaten und Funktionen, die das Fahrzeug in der Spur halten.
Stufe 3 (bedingte Automatisierung): Das Fahrzeug kann eigenständig fahren, bei Bedarf muss jedoch der menschliche Fahrer übernehmen. Der Fahrer ist die Rückfallebene des Systems und muss wachsam und einsatzbereit bleiben.
Stufe 4 (hohe Automatisierung): Das Fahrzeug kann selbst fahren und ist nicht auf einen Menschen angewiesen, der bei Problemen die Kontrolle übernehmen kann. Das System ist jedoch noch nicht in der Lage, in allen Situationen (besondere Anwendungsfälle, Geländemerkmale usw.) autonom zu fahren.
Stufe 5 (volle Automatisierung): Das Fahrzeug kann selbst fahren, ohne dass menschliches Eingreifen notwendig wäre, und in allen Fahrsituationen eingesetzt werden. In Fachkreisen wird lebhaft darüber diskutiert, wie weit der Weg zum vollautonomen Fahren noch ist. Uneinigkeit herrscht auch darüber, welches der richtige Ansatz ist, um autonome Fahrfunktionen zu integrieren.
Bei den Diskussionen geht es vor allem um zwei Punkte, die Rolle des Fahrers und den Einsatzbereich der Technologie:
a) Die Rolle des Fahrers
Verzicht auf einen menschlichen Fahrer: Einige Unternehmen, die autonome Fahrzeuge entwickeln, wie Waymo und Tesla, glauben, dass es bald möglich sein wird, auf einen menschlichen Fahrer (Fahrzeughalter oder Sicherheitsfahrer) zu verzichten. Tesla verkauft Fahrzeuge der Autonomiestufe 3. Waymo hatte Pläne, bis Ende 2018 einen vollautonomen Taxidienst ohne Fahrer in Arizona einzuführen (Lee, 2018[10]).
Unterstützung des Fahrers: Andere Systementwickler sind überzeugt, dass der beste Einsatz von AF-Systemen auf kurze Sicht nicht darin bestehen wird, den Fahrer zu ersetzen, sondern Unfälle zu vermeiden. Toyota, der weltgrößte Automobilhersteller gemessen an der Börsenkapitalisierung, setzt sich maßgeblich für die Entwicklung von Fahrzeugen ein, die keinen Unfall verursachen können (Lippert et al., 2018[8]).
b) Einsatzbereich der Technologie
Es gibt zwei Ansätze für die Einführung von Fahrautomatisierungssystemen, die von Walker-Smith (2013[11]) und vom Weltverkehrsforum (International Transport Forum – ITF) (2018[12]) beschrieben wurden.
Alles, aber örtlich begrenzt (everything somewhere): Bei diesem Ansatz ist eine sehr hohe Autonomie nur in bestimmten Gegenden oder auf bestimmten Straßen möglich, die im Detail kartografiert wurden. Das autonome Fahrassistenzsystem Super Cruise von Cadillac ist beispielsweise nur an bestimmten Orten verfügbar (z. B. funktioniert es nur auf Autobahnen, die kartografisch erfasst wurden).
Überall etwas (something everywhere): Bei diesem Ansatz werden Fahrzeuge nur dann mit autonomen Fahrfunktionen ausgestattet, wenn sie auf jeder Straße und in jeder Situation eingesetzt werden können. Dies hat zwar einen begrenzten Funktionsumfang zur Folge, dafür sollte es aber möglich sein, die Funktionen überall zu nutzen. Viele Automobilhersteller scheinen diesen Ansatz zu bevorzugen.
Einige Unternehmen sind indessen optimistischer. Sie scheinen sich zum Ziel gesetzt zu haben, bis 2020 oder 2021 autonome Fahrzeuge der Stufe 4 liefern zu können. Tesla und Zoox wollen dies z. B. bis 2020 schaffen, Audi/Volkswagen, Baidu und Ford bis 2021. Renault Nissan strebt 2022 an. Auch andere Hersteller investieren hohe Summen in autonomes Fahren. Sie konzentrieren sich jedoch auf die Vermeidung von Unfällen durch menschliche Fahrer. Sie halten die Technologie für nicht ausgereift genug, um in naher Zukunft autonomes Fahren der Stufe 4 zu ermöglichen. Dazu gehören BMW, Toyota, Volvo und Hyundai (Welsch, D. und E. Behrmann, 2018[13]).
Politikfragen
Die Einführung autonomer Fahrzeuge wirft eine Reihe wichtiger rechtlicher und regulatorischer Fragen auf (Inners, M. und A. Kun, 2017[14]). Dabei geht es insbesondere um Sicherheit und Datenschutz (Bose et al., 2016[15]), aber auch ganz allgemein um Auswirkungen auf Wirtschaft und Gesellschaft (Surakitbanharn et al., 2018[16]). Herausforderungen für die Politik bestehen im OECD-Raum vor allem in folgenden Bereichen:
Sicherheit und Regulierung
Die Politik muss nicht nur Sicherheit gewährleisten (vgl. Unterabschnitt „Robustheit und Sicherheit“ in Kapitel 4), sondern sich u. a. auch mit Haftungsfragen, Betriebsmittelvorschriften für Steuerungen und Signalisierungen sowie Fahrervorschriften auseinandersetzen und sicherstellen, dass Straßenverkehrsordnungen und Betriebsvorschriften eingehalten werden (Inners, M. und A. Kun, 2017[14]).
Daten
Wie bei allen KI-Systemen wird der Zugriff auf Daten zum Trainieren und Anpassen der Systeme für den Erfolg des autonomen Fahrens von entscheidender Bedeutung sein. Die Hersteller autonomer Fahrzeuge sammeln bei ihren Testläufen immense Datenmengen. Fridman (2018[17]) schätzt, dass Tesla über Daten aus mehr als 2,4 Milliarden Kilometern verfügt, die mit seinem Autopiloten zurückgelegt wurden. Die Echtzeit-Fahrdaten, die von Entwicklern autonomer Fahrzeuge gesammelt werden, sind eigentumsrechtlich geschützt und werden nicht an andere Unternehmen weitergegeben. Es gibt jedoch Initiativen, z. B. beim Massachusetts Institute of Technology (MIT) (Fridman et al., 2018[18]), um frei zugängliche Datensätze aufzubauen, die das Verständnis des Fahrerverhaltens verbessern sollen. Aufgrund ihrer freien Zugänglichkeit sind diese Datensätze sehr wichtig für Forscher und Entwickler autonomer Fahrzeuge, die die Systeme verbessern möchten. Der Zugang zu den von verschiedenen Systemen gesammelten Daten und die Rolle staatlicher Stellen bei der Finanzierung offener Datensammlungen ist daher ein Thema für Politikdiskussionen.
Sicherheit und Datenschutz
Damit AF-Systeme zuverlässig und sicher funktionieren, bedarf es großer Mengen an Daten über System, Fahrerverhalten und Umgebung. Außerdem werden diese Systeme mit verschiedenen Netzwerken verbunden, um Informationen weiterzugeben. Die von AF-Systemen gesammelten, abgerufenen und verwendeten Daten müssen daher ausreichend gegen unerwünschte Zugriffe gesichert sein. Teilweise handelt es sich um sensible Daten wie Informationen zum Standort und Nutzerverhalten, die verwaltet und geschützt werden müssen (Bose et al., 2016[15]). Aus diesem Grund fordert das Weltverkehrsforum umfassende Cybersicherheitsbestimmungen für das automatisierte Fahren (ITF, 2018[12]). Von neuen kryptografischen Protokollen und Systemen verspricht man sich außerdem einen besseren Schutz der Privatsphäre sowie Datenschutz. Unter Umständen verlangsamen diese Systeme jedoch die Verarbeitungszeit für erfolgs- und sicherheitskritische Aufgaben. Darüber hinaus befinden sie sich noch im Anfangsstadium und stehen noch nicht in dem Umfang und der Geschwindigkeit zur Verfügung, die für Echtzeitanwendungen im Bereich des autonomen Fahrens erforderlich sind.
Umwälzungen auf dem Arbeitsmarkt
Die Umstellung auf autonome Fahrzeuge könnte erhebliche Auswirkungen auf Fracht-, Taxi- und Lieferdienste sowie andere Dienstleistungstätigkeiten haben. In den Vereinigten Staaten gehen schätzungsweise 2,86 % der Erwerbsbevölkerung Fahrtätigkeiten nach (Surakitbanharn et al., 2018[16]). Bösch et al. (2018[3]) weisen auf die potenziell erheblichen Kosteneinsparungen hin, die in diesen Branchen durch eine Umstellung auf autonome Systeme erzielt werden könnten. Aus gewinnmaximierender Sicht wäre daher ein schneller Übergang zu autonomen Fahrzeugen zu erwarten, sobald die Technologie ausreichend ausgereift ist. Dazu müssen aber auch nichttechnische Hemmnisse, z. B. im Regulierungsbereich, überwunden werden. Der Technologiewandel wird Arbeitsplätze kosten. Die Politik muss ihr Augenmerk daher verstärkt auf die Sicherung von Kompetenzen und Beschäftigungschancen in einer sich wandelnden Arbeitswelt richten (OECD, 2014[19]).
Infrastruktur
Da es mit der Einführung des autonomen Fahrens zu einem Nebeneinander von menschlichen Fahrern und autonomen Fahrzeugen kommen wird, dürften Veränderungen der Infrastruktur erforderlich sein. Zwar dürften autonome Fahrzeuge über die notwendige Ausrüstung verfügen, um in Zukunft miteinander zu kommunizieren, herkömmliche Fahrzeuge mit menschlichen Fahrern würden jedoch ein bedeutender Unsicherheitsfaktor bleiben. Autonome Fahrzeuge müssten ihr Verhalten an Fahrzeuge anpassen, die noch von Menschen gesteuert werden. Derzeit wird über die Möglichkeit spezieller Fahrspuren für autonome Fahrzeuge oder andere Vorrichtungen diskutiert, durch die menschliche Fahrer in Zukunft von autonomen Fahrzeugen getrennt werden könnten (Surakitbanharn et al., 2018[16]). Autonome Fahrzeuge werden daher zunehmend bei der Infrastrukturplanung berücksichtigt werden müssen.
KI in der Landwirtschaft
Durch die wachsende Genauigkeit von Cognitive-Computing-Technologien, wie z. B. der Bilderkennung, erfährt die Landwirtschaft derzeit einen Wandel. Bislang mussten sich die Landwirtinnen und Landwirte auf ihren eigenen geschulten Blick verlassen, um zu entscheiden, wann welche Felder bewässert, gedüngt oder abgeerntet werden mussten. Heute können „Ernteroboter“, die mit KI-Technologien und Daten von Kameras und Sensoren ausgestattet sind, solche Entscheidungen in Echtzeit treffen. Diese Art von Roboter kann zunehmend Aufgaben übernehmen, die bisher menschliche Arbeitsleistung und Wissen erforderten.
Technologie-Start-ups entwickeln innovative Lösungen, um KI erfolgreich in der Landwirtschaft einzusetzen (FAO, 2017[20]). Diese Lösungen lassen sich in folgende Kategorien einteilen (Tabelle 3.1):
Agrarroboter übernehmen wichtige landwirtschaftliche Arbeiten wie z. B. die Ernte. Im Vergleich zu Menschen werden sie immer schneller und produktiver.
Bei der Pflanzen- und Bodenüberwachung werden Computer-Vision- und Deep-Learning-Algorithmen genutzt, um den Zustand von Pflanzen und Böden zu überwachen. In immer größerer Menge zur Verfügung stehende Satellitendaten erleichtern dies (Abbildung 3.3).
Im Bereich Predictive Analytics werden maschinelle Lernmodelle genutzt, um die Auswirkungen von Umweltfaktoren auf den Ernteertrag zu beobachten und vorherzusagen.
Abbildung 3.3. Beispiele für die Nutzung von Satellitendaten für ein besseres Monitoring
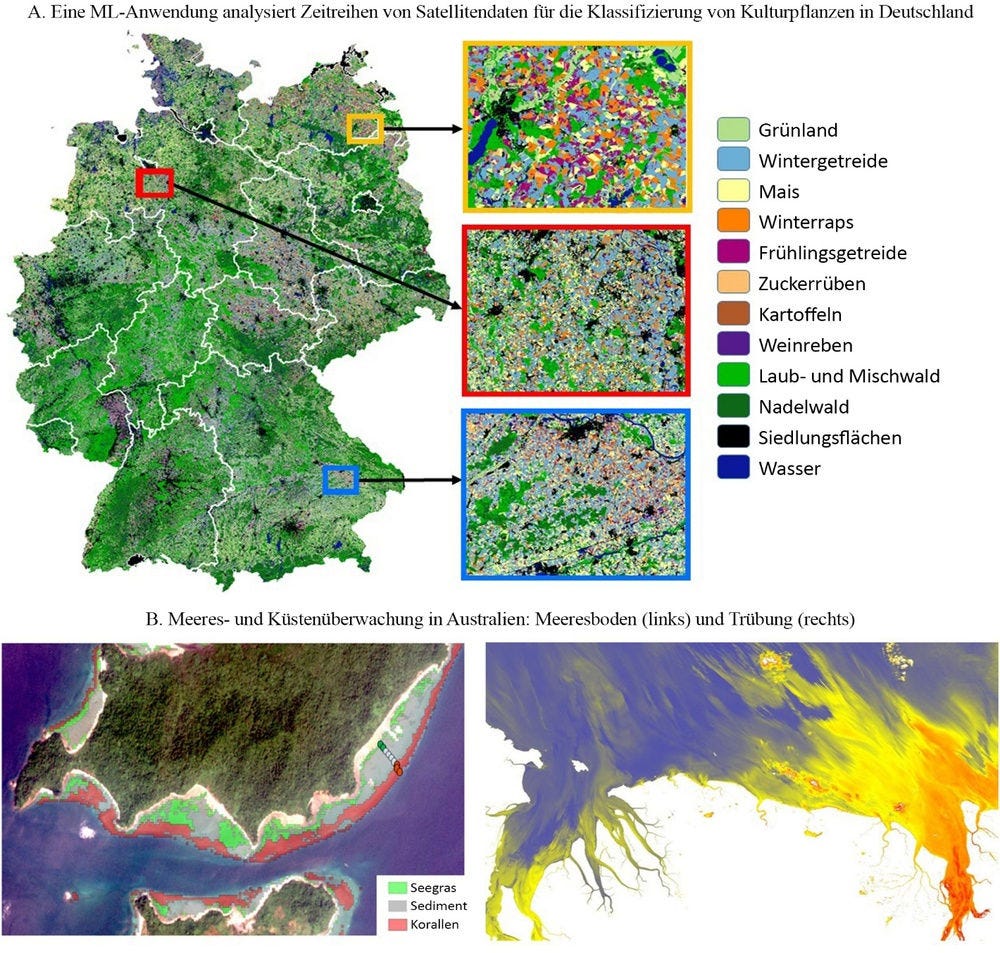
Quelle: Roeland (2017[21]), EC Perspectives on the Earth Observation, www.oecd.org/going-digital/ai-intelligent-machines-smart-policies/conference-agenda/ai-intelligent-machines-smart-policies-roeland.pdf; Cooke (2017[22]), Digital Earth Australia, www.oecd.org/going-digital/ai-intelligent-machines-smart-policies/conference-agenda/ai-intelligent-machines-smart-policies-cooke.pdf.
Tabelle 3.1. KI-Start-ups in der Landwirtschaft (Auswahl)
Quelle: Websites der Unternehmen.
Herausforderungen bei der Einführung von KI in der Landwirtschaft
Projektionen der Welternährungsorganisation FAO zufolge wird die Weltbevölkerung gegenüber dem heutigen Stand bis 2050 um fast 30 % wachsen – von 7 Milliarden auf 9 Milliarden Menschen. Allerdings wird nur 4 % mehr Land bewirtschaftet werden (FAO, 2009[23]). Die OECD hat Chancen und Herausforderungen des digitalen Wandels in der Landwirtschaft und im Nahrungsmittelsektor untersucht (Jouanjean, 2019[24]). Unter den digitalen Technologien versprechen insbesondere KI-Anwendungen eine Steigerung der landwirtschaftlichen Produktivität. Bevor solche Technologien allgemein eingeführt werden können, müssen jedoch noch eine Reihe von Herausforderungen bewältigt werden (Rakestraw, 2017[25]):
Mangel an Infrastruktur: In vielen ländlichen Gebieten ist der Netzzugang nach wie vor schlecht. Außerdem wären für robuste Anwendungen Data-Warehouse-Systeme erforderlich.
Produktion hochwertiger Daten: Für KI-Anwendungen in der Landwirtschaft werden hochwertige Daten zur Erkennung von Kulturpflanzen bzw. Blattformen benötigt. Die Erfassung dieser Daten kann kostspielig sein, da sie nur während der jährlichen Wachstumssaison möglich ist.
Unterschiedliche Denkmuster von Technologie-Start-ups und Landwirten: Produkte und Dienstleistungen werden von Technologie-Start-ups in der Regel schnell entwickelt und auf den Markt gebracht, Landwirte übernehmen neue Prozesse und Technologien hingegen eher zögerlich. Selbst große landwirtschaftliche Betriebe führen zunächst umfangreiche Feldstudien durch, um sicherzustellen, dass der Einsatz neuer Technologien mit einem klaren Nutzen verbunden ist und die Leistung gleichbleibt.
Kosten und insbesondere Transaktionskosten: Um Agrarbetriebe in Hightech-Betriebe zu verwandeln (die z. B. Agrarroboter einsetzen), sind hohe Investitionen in Sensoren und Automatisierungswerkzeuge erforderlich. In Frankreich z. B. wird derzeit an Maßnahmen zur Förderung von Investitionen in bestimmte landwirtschaftliche KI-Anwendungen gearbeitet. Dadurch könnte die Einführung neuer Technologien auch für Kleinbauern erleichtert werden (OECD, 2017[26]).
Möglichkeiten zur Förderung der Einführung von KI in der Landwirtschaft
Aktuell wird nach Lösungen für die verschiedenen Herausforderungen gesucht, mit denen die künstliche Intelligenz in der Landwirtschaft konfrontiert ist. Wie in anderen Bereichen wird auch hier Open-Source-Software entwickelt. Dies könnte helfen, Kostenprobleme zu lösen. So hat Connectra beispielsweise ausgehend von der Open-Source-Software-Suite TensorFlow von Google einen Bewegungsmelder entwickelt, der am Hals von Kühen befestigt wird und deren Gesundheit überwacht (Webb, 2017[27]). Transferlernen (vgl. Unterabschnitt „Datenzugang und -nutzung“ in Kapitel 4) kann Datenprobleme verringern, da es die Möglichkeit bietet, Algorithmen mit viel kleineren Datensätzen zu trainieren. Forscher haben beispielsweise ein System entwickelt, das Krankheiten von Maniokpflanzen erkennt. Dazu wurde bei einer anderen Pflanzenart erworbenes Wissen genutzt. Mit einem Input von nur 2 756 Bildern von Maniokblättern, die von Pflanzen in Tansania stammten, gelang es den Forschern, die braune Blattfleckenkrankheit an Maniokpflanzen mit einer Genauigkeit von 98 % richtig zu erkennen (Simon, 2017[28]).
KI im Finanzsektor
Im Finanzsektor wurde KI von großen Unternehmen wie JPMorgan, Citibank, State Farm und Liberty Mutual rasch eingeführt. Das Gleiche gilt für Start-ups wie Zest Finance, Insurify, WeCash, CreditVidya und Aire. Finanzdienstleistungsunternehmen kombinieren verschiedene Methoden des maschinellen Lernens. So analysiert das französische Start-up-Unternehmen QuantCube Technology mehrere Milliarden Datenpunkte, die in über 40 Ländern gesammelt wurden. Um KI-Lösungen für die Entscheidungsfindung in Finanzunternehmen zu entwickeln, nutzt es u. a. Sprachverarbeitung, Deep Learning und Graphentheorie.
Durch den Einsatz von KI im Finanzsektor lassen sich erhebliche Nutzeffekte erzielen. So dürfte es z. B. möglich sein, die Kundenzufriedenheit zu erhöhen und Investitionschancen schneller zu erkennen. Vielleicht könnten auch mehr Kredite zu besseren Konditionen vergeben werden. Eine solche Entwicklung wirft jedoch auch Grundsatzfragen auf, beispielsweise in Bezug darauf, wie die Richtigkeit der Entscheidungen sichergestellt und Diskriminierung vermieden werden kann und welche weitergehenden Auswirkungen die Automatisierung auf die Beschäftigung hat.
Dieser Abschnitt bietet einen Überblick über KI-Anwendungen im Finanzsektor. Er befasst sich mit den Themen Kredit-Scoring, Finanztechnologie (FinTech), Algorithmushandel, Kostensenkungen bei Finanzdienstleistungen, Kundenerlebnis und Compliance.
Kredit-Scoring
In der Finanzdienstleistungsbranche werden seit Langem statistische Ansätze für verschiedene Zwecke genutzt, u. a. zur Berechnung von Anzahlungsbeträgen und zur Abschätzung des Ausfallrisikos. Kredit-Scoring ist eine statistische Analyse, die von Finanzinstituten durchgeführt wird, um die Kreditwürdigkeit eines Kunden zu beurteilen. Anders ausgedrückt wird geprüft, mit welcher Wahrscheinlichkeit ein Kreditnehmer mit seinen Schuldendienstverpflichtungen in Verzug geraten dürfte. In traditionellen Kredit-Scoring-Modellen stellen Analysten Hypothesen über die Attribute auf, die sich auf den Kreditscore auswirken, und erstellen Kundensegmente.
Seit einiger Zeit ermöglichen neuronale Netzwerktechniken die Analyse großer Datenmengen aus Kreditauskünften. Maßgebliche Faktoren und die zwischen ihnen bestehenden Zusammenhänge können so im Detail analysiert werden. Die auf großen Datensätzen beruhenden Algorithmen der KI-Systeme bestimmen automatisch die bestmögliche Konfiguration der neuronalen Netze und davon ausgehend die verschiedenen Kundensegmente und ihre Gewichtung. Laut Kreditauskunfteien in den Vereinigten Staaten können Deep-Learning-Techniken, die Daten auf neue Art und Weise analysieren, die Genauigkeit von Prognosen um bis zu 15 % verbessern (Press, 2017[29]).
Wie in anderen Bereichen auch stellt die schwere Nachvollziehbarkeit der Ergebnisse von ML-basierten Kreditscoring-Algorithmen ein Problem dar. Die Rechtsnormen vieler Länder verlangen ein hohes Maß an Transparenz im Finanzdienstleistungssektor. Aus den Regeln des Fair Credit Reporting Act (1970) und des Equal Credit Opportunity Act (1974) in den Vereinigten Staaten ergibt sich z. B., dass die einzelnen Schritte eines Algorithmus und deren Ergebnisse nachvollziehbar sein müssen. Die Unternehmen versuchen diesen Anforderungen gerecht zu werden. So haben beispielsweise die Auskunftei Equifax und das Datenanalyse-Unternehmen SAS ein interpretierbares Kredit-Scoring-Tool entwickelt, das auf Deep Learning basiert.
Kreditvergabe von Finanztechnologie-Unternehmen
Seit einigen Jahren befinden sich Finanztechnologie-Unternehmen auf einem schnellen Wachstumskurs. FinTech-Kreditplattformen ermöglichen es Verbrauchern, in Sekundenschnelle online Kredite zu finden, zu beantragen und zu erhalten. Kreditgebern liefern sie die üblichen Kreditauskunftsdaten (etwa zum Zahlungsverhalten, zu den geschuldeten Beträgen, zur Länge der Kredithistorie und zur Anzahl der Konten). FinTech-Kreditgeber nutzen aber auch eine Vielzahl alternativer Datenquellen. Dazu gehören Versicherungsansprüche, Aktivitäten in den sozialen Medien, Informationen zu Online-Einkäufen bei Marktplätzen wie Amazon, Versanddaten von Postdiensten, Browsing-Muster und Information zum verwendeten Telefontyp oder Browser (Jagtiani, J. und C. Lemieux, 2019[30]). Untersuchungen zeigen, dass die alternativen Daten, die von FinTech-Unternehmen mit KI verarbeitet werden, den Zugang zu Krediten für Personen erleichtern können, die keine klassische Kredithistorie haben. Sie können auch die Kosten der Kreditvergabe senken, und zwar sowohl für die Verbraucher als auch für die Kreditgeber (FSB, 2017[31]).
In einer jüngeren Untersuchung wurde die Leistung von Algorithmen verglichen, die Kreditausfallwahrscheinlichkeiten auf der Basis des in den Vereinigten Staaten traditionell verwendeten FICO3-Scores und auf der Basis alternativer Daten vorhersagen (Berg et al., 2018[32]). Mit dem FICO-Score allein betrug die Genauigkeit 68,3 %. Die Genauigkeit eines auf alternativen Daten basierenden Algorithmus lag bei 69,6 %. Durch die Kombination beider Datentypen stieg die Genauigkeit auf 73,6 %. Diese Ergebnisse legen den Schluss nahe, dass alternative Daten die Informationen von Kreditauskunfteien zwar ergänzen, nicht aber ersetzen können. Kreditgeber können bessere Kreditentscheidungen treffen, wenn sie sowohl Informationen aus herkömmlichen Quellen (FICO) als auch alternative Daten verwenden.
In der Volksrepublik China (nachstehend „China“) hat Ant Financial gezeigt, wie KI das Kreditgeschäft beflügeln kann (Zeng, 2018[33]). Mit Hilfe von Algorithmen verarbeitet das Unternehmen riesige Mengen an Transaktionsdaten, die von kleinen Unternehmen auf seiner Plattform generiert werden. So konnte Ant bereits Kredite in Höhe von mehr als 13,4 Mrd. USD an nahezu 3 Millionen Kleinunternehmen vergeben. Die Algorithmen von Ant analysieren automatisch die Transaktions- und Verhaltensdaten aller Kreditnehmer in Echtzeit. Kleinkredite im Umfang von mehreren Hundert Yuan Renminbi (rd. 50 USD) können in wenigen Minuten bearbeitet werden. Jede auf der Plattform Alibaba ausgeführte Aktion – sei es eine Transaktion, eine Kommunikation zwischen Verkäufer und Käufer oder eine Verbindung zu anderen Diensten – wirkt sich auf den Kreditscore der Unternehmen aus. Die Algorithmen, die die Scores berechnen, entwickeln sich zudem mit der Zeit weiter, sodass die Qualität der Entscheidungsfindung mit jeder Iteration verbessert wird. Im Geschäftsbereich Mikrokredite hat Ant eine Ausfallquote von rd. 1 %. Weltweit lag die durchschnittliche Ausfallquote in diesem Bereich laut Schätzungen der Weltbank 2016 bei 4 %.
Das Kredit-Scoring-Unternehmen Alipay verwendet Verbraucherdatenpunkte, um Kreditscores zu bestimmen (O’Dwyer, 2018[34]). Dazu gehören Kaufhistorie, verwendeter Telefontyp, gespielte Spiele und Daten zu Freunden in den sozialen Medien. Zusätzlich zum herkömmlichen Scoring zur Kreditgewährung können die chinesischen „sozialen“ Kreditscores auch Einfluss auf bestimmte Entscheidungen haben, z. B. darauf, wie hoch die Kaution bei der Anmietung einer Wohnung angesetzt wird oder welche Kandidaten bei einer Online-Partnervermittlung vorgeschlagen werden. Jemand, der tagtäglich stundenlang Videospiele spielt, könnte beispielsweise einen niedrigeren sozialen Kreditscore haben als jemand, der Windeln kauft und von dem deshalb angenommen wird, dass er sich als Vater oder Mutter verantwortungsvoll verhält (Rollet, 2018[35]). 2020 soll in China ein umfassenderes soziales Kreditsystem eingeführt werden, um die „Vertrauenswürdigkeit“ von Einzelpersonen, Unternehmen und Regierungsvertretern zu bewerten.
Alternative Daten bieten die Möglichkeit, den Zugang zu Krediten zu erweitern. Die Verwendung alternativer Daten wirft aber auch Bedenken in Bezug auf Gleichbehandlung, Datenschutz, Sicherheit und Transparenz auf (Gordon, M. und V. Stewart, 2017[36]). Das Consumer Financial Protection Bureau in den Vereinigten Staaten hat daher eine Studie über die Verwendung alternativer Daten beim Kredit-Scoring angestrengt (CFPB, 2017[37]).
Einsatz von KI zur Kostensenkung bei Finanzdienstleistungen
Der Einsatz von KI kommt sowohl den Kunden als auch den Finanzinstituten zugute, im Front-Office (z. B. bei den Kontakten mit den Kunden), im Middle-Office (etwa bei der Unterstützung des Front-Office) und im Back-Office (z. B. bei der Zahlungsabwicklung, im Personalmanagement oder bei der Compliance). Es wird erwartet, dass Finanzinstitute in den USA durch die Einführung von KI im Front-, Middle- und Back-Office bis 2030 schätzungsweise 1 Bill. USD einsparen können, was Auswirkungen auf 2,5 Millionen Mitarbeiter im Finanzdienstleistungsbereich haben dürfte (Sokolin, L. und M. Low, 2018[38]). Durch zunehmend ausgereifte KI-Anwendungen sind menschliche Eingriffe immer seltener notwendig.
Im Front-Office werden Finanzdaten und Kontobewegungen in KI-gestützte Software-Agenten integriert. Diese Agenten können sich mit Kunden auf Plattformen wie Facebook Messenger oder Slack, die fortgeschrittene Sprachverarbeitung nutzen, unterhalten. KI verbessert nicht nur den traditionellen Kundenservice, sondern wird von vielen Finanzunternehmen auch für sog. Robo-Advisor eingesetzt. Diese algorithmenbasierten Systeme bieten automatisierte Finanzberatungs- und Geldanlageleistungen an (OECD, 2017[39]).
Eine weitere interessante Entwicklung ist der Einsatz der Sentiment-Analyse auf Social-Media-Finanzplattformen. Unternehmen wie Seeking Alpha und StockTwits, die sich auf den Aktienmarkt konzentrieren, ermöglichen es Nutzern, sich zu vernetzen und Fachleute zu konsultieren, um Anlageentscheidungen zu optimieren. Die auf diesen Plattformen produzierten Daten können dann in Entscheidungsprozesse eingebunden werden (Sohangir et al., 2018[40]). KI kommt auch beim Online- und Mobile-Banking zum Einsatz, wenn Nutzer per Fingerabdruck oder Gesichtserkennung über das Smartphone authentifiziert werden. Manche Banken nutzen anstelle von numerischen Zugangscodes auch Verfahren der Spracherkennung (Sokolin, L. und M. Low, 2018[38]).
Im Middle-Office kann KI das Risikomanagement und aufsichtsrechtliche Aufgaben erleichtern. Darüber hinaus hilft KI Portfoliomanagern, effizientere und genauere Investitionsentscheidungen zu treffen. Beim Produktdesign im Back-Office sorgt KI für ein breiteres Datenangebot zur Kreditrisikobewertung, zur Übernahme des versicherungstechnischen Risikos und zur Bewertung von Schadenfällen (z. B. Begutachtung einer gebrochenen Windschutzscheibe mittels maschinellem Sehen).
Compliance
Der Finanzsektor ist für die hohen Kosten bekannt, die mit der Einhaltung von Normen und Berichterstattungspflichten verbunden sind. Neue Vorschriften in den Vereinigten Staaten und der Europäischen Union haben in den letzten zehn Jahren zu einem weiteren Anstieg der Kosten geführt, die Banken durch regulatorische Auflagen entstehen. In den letzten Jahren gaben Banken jährlich schätzungsweise 70 Mrd. USD für Compliance- und Corporate-Governance-Software aus. Diese Ausgaben spiegeln die Kosten wider, die durch die Überprüfung der Rechtskonformität der Geschäftsvorfälle durch Bankanwälte, Juristen und Compliance Officers entstehen. Es wird erwartet, dass die Kosten für solche Tätigkeiten 2020 auf nahezu 120 Mrd. USD ansteigen werden (Chintamaneni, 2017[41]). Durch den Einsatz von KI-Technologien, insbesondere von Sprachverarbeitung, dürfte es möglich sein, die Compliance-Kosten der Banken um rd. 30 % zu verringern. Der Zeitaufwand für die Überprüfung der einzelnen Geschäftsvorfälle wird erheblich sinken. KI kann bei der Interpretation von Regulierungsdokumenten und der Kodifizierung von Compliance-Regeln helfen. So überprüft beispielsweise das von JPMorgan Chase entwickelte Programm Coin Unterlagen auf der Basis von Geschäftsregeln und Methoden der Datenvalidierung. In Sekundenschnelle kann das Programm Dokumente untersuchen, für deren Prüfung ein Mensch 360 000 Stunden benötigen würde (Song, 2017[42]).
Betrugserkennung
Auch bei der Betrugserkennung setzen Finanzunternehmen verstärkt auf KI. Banken haben immer schon Kontobewegungsmuster überwacht. Inzwischen ist es dank Fortschritten im Bereich des maschinellen Lernens zunehmend möglich, Kontobewegungen nahezu in Echtzeit zu verfolgen. Dadurch können Anomalien, die eine Überprüfung erforderlich machen, sofort erkannt werden. Dass KI kontinuierlich neue Verhaltensmuster analysieren und sich automatisch anpassen kann, ist für die Betrugserkennung von besonderer Bedeutung, da sich die Verhaltensmuster rasch ändern. 2016 gründete die Credit Suisse Group AG zusammen mit dem im Sillicon Valley ansässigen Überwachungs- und Sicherheitsunternehmen Palantir Technologies ein KI-Gemeinschaftsunternehmen. Um Banken zu helfen, unerlaubte Geschäfte aufzudecken, haben die beiden Unternehmen eine Lösung entwickelt, mit der unethisch handelnde Mitarbeiter aufgespürt werden sollen, bevor sie der Bank Schaden zufügen können (Voegeli, 2016[43]). Auch im Telekommunikationssektor gewinnt die Betrugserkennung auf Basis ML-gestützter biometrischer Sicherheitssysteme an Bedeutung.
Algorithmushandel
Unter Algorithmushandel ist der Einsatz von Computeralgorithmen zu verstehen, um automatisch Entscheidungen in Bezug auf Transaktionen zu treffen, Aufträge zu erteilen und diese Aufträge anschließend zu verwalten. In den letzten zehn Jahren hat der Algorithmushandel so stark an Beliebtheit gewonnen, dass er heute die Mehrzahl der weltweit an den Börsen getätigten Transaktionen ausmacht. 2017 schätzte JPMorgan, dass es sich nur noch bei 10 % des Aktienhandelsvolumens um auf herkömmliche Weise ausgewählte Aktien (stock picking) handelt (Cheng, 2017[44]). Erweiterte Rechenkapazitäten begünstigen zudem den sog. Hochfrequenzhandel, bei dem täglich Millionen von Aufträgen übermittelt und viele Märkte gleichzeitig „gescannt“ werden. Während menschliche Börsenhändler zumeist die gleiche Art von Prädiktoren verwenden, können durch den Einsatz von KI vielfältigere Faktoren berücksichtigt werden.
KI in Marketing und Werbung
KI beeinflusst Marketing und Werbung in vielerlei Hinsicht. Zentral ist dabei, dass KI eine Personalisierung des Online-Erlebnisses ermöglicht. So können Inhalte angezeigt werden, an denen die Verbraucher mit großer Wahrscheinlichkeit interessiert sind. Entwicklungen im Bereich des maschinellen Lernens sowie große Mengen an generierten Daten bieten Werbetreibenden immer mehr Möglichkeiten, ihre Werbekampagnen auf bestimmte Zielgruppen auszurichten. In bislang ungekanntem Umfang können sie personalisierte und dynamische Anzeigen schalten (Chow, 2017[45]). Personalisierte Werbung bietet Unternehmen und Verbrauchern erhebliche Vorteile. Unternehmen gestattet sie, ihre Umsätze zu steigern und Investitionen in Marketingkampagnen rentabler zu machen. Verbraucher können profitieren, da durch Werbeeinnahmen finanzierte Online-Dienste den Endnutzern häufig kostenlos zur Verfügung gestellt werden. Internetsuchen werden so deutlich billiger.
In der folgenden nicht erschöpfenden Liste werden einige Entwicklungen im Bereich der künstlichen Intelligenz beschrieben, die großen Einfluss auf Marketing- und Werbepraktiken auf der ganzen Welt haben könnten:
Sprachverarbeitung: Einer der wichtigsten Teilbereiche der KI, mit dem Werbung und Marketingbotschaften stärker personalisiert werden können, ist die maschinelle Verarbeitung natürlicher Sprache (natural language processing – NLP). Sie ermöglicht eine gezielte Anpassung von Marketingkampagnen ausgehend von sprachlichen Kontextinformationen, z. B. Beiträgen in den sozialen Medien, E-Mails, Kundendienstkontakten und Produktbewertungen. Durch NLP-Algorithmen lernen Maschinen Wörter und identifizieren Wortmuster in der natürlichen Sprache. Dabei verbessern sie ständig ihre Genauigkeit. So können sie Informationen über die Präferenzen und Kaufabsichten eines Kunden gewinnen (Hinds, 2018[46]). NLP kann die Qualität von Online-Suchergebnissen verbessern und dafür sorgen, dass die geschalteten Anzeigen den Interessen des Kunden stärker entsprechen, wodurch sich die Werbeeffizienz erhöht. Wenn Kunden beispielsweise online nach einer bestimmten Schuhmarke suchen, könnte ein KI-basierter Werbealgorithmus gezielt Anzeigen für diese Marke schalten, während die Kunden anderen Aktivitäten im Internet nachgehen. Mit einem solchen Algorithmus können sogar Benachrichtigungen auf das Mobiltelefon der Kunden geschickt werden, wenn sie an einem Schuhgeschäft vorbeikommen, das mit Preisnachlässen lockt.
Strukturierte Datenanalyse: Künstliche Intelligenz wird im Marketing jedoch nicht nur zur Analyse „unstrukturierter Daten“ mithilfe von NLP-Modellen genutzt. Dank KI können die heutigen Online-Empfehlungsalgorithmen deutlich mehr leisten als einfache Empfehlungen oder historische Benutzer-Bewertungen. Da sie auf eine sehr breite Datenbasis zugreifen, können sie individuelle Empfehlungen abgeben. So erstellt Netflix beispielsweise eine personalisierte „Watchlist“ mit Vorschlägen, bei der berücksichtigt wird, welche Filme der betreffende Kunde gesehen oder wie er sie bewertet hat. Zudem wird analysiert, welche Filme mehrfach angesehen und vor- und zurückgespult wurden (Plummer, 2017[47]).
Ermittlung der Erfolgswahrscheinlichkeit: In der Online-Werbung ist die Klickrate (auch Click-through-Rate – CTR) – d. h. die Anzahl der Personen, die auf eine Anzeige klicken, geteilt durch die Anzahl der Personen, die die Anzeige gesehen haben – eine wichtige Kennzahl zur Beurteilung der Anzeigenleistung. Daher wurden auf der Basis von ML-Algorithmen Systeme entwickelt, die die Anzahl der Klicks vorhersagen, um die Wirkung von gesponserten Anzeigen und Online-Marketingkampagnen zu maximieren. In den meisten Fällen wird mit Algorithmen des bestärkenden Lernens, sog. Reinforced-Learning-Algorithmen, eine Anzeige ausgewählt, deren Merkmale zu einer Maximierung der Klickrate in der Zielgruppe führen dürfte. Eine höhere Klickrate kann die Einnahmen von Unternehmen deutlich steigern: Bereits 1 % mehr Klicks können ausreichen, um den Umsatz und damit auch die Gewinne deutlich zu steigern (Hong, 2017[48]).
Personalisierte Preisgestaltung:4 KI-Technologien ermöglichen es Unternehmen, ihre Preise laufend an das Verhalten und die Präferenzen der Kunden anzupassen. Gleichzeitig können sie auf die Gesetze von Angebot und Nachfrage, Ertragsanforderungen und äußere Einflüsse reagieren. ML-Algorithmen können den Höchstpreis vorhersagen, den ein Kunde für ein Produkt zu zahlen bereit ist. Die Preise werden dann direkt an dem Ort, an dem der Kundenkontakt stattfindet (z. B. auf einer Online-Plattform), individuell auf die einzelnen Verbraucher zugeschnitten (Waid, 2018[49]). Dies kann zwar für den Kunden von Vorteil sein, wenn solche Praktiken aber der Erzielung überhöhter Preise oder der Wettbewerbsverzerrung bzw. -verdrängung dienen, können sie negative Auswirkungen auf die Verbraucher haben (Brodmerkel, 2017[50]).
KI-gesteuerte erweiterte Realität: Erweiterte Realität (Augmented Reality – AR) ermöglicht die Überlagerung der vom Kunden wahrgenommenen realen Umgebung mit der digitalen Darstellung eines Produkts. In Kombination mit KI kann AR Kunden eine Vorstellung davon vermitteln, wie das Produkt aussehen dürfte, wenn es hergestellt und in den vorgesehenen physischen Kontext gestellt würde. KI-gestützte AR-Systeme können aus den Kundenpräferenzen lernen. Sie können die computergenerierten Bilder der Produkte dann entsprechend anpassen und so das Kundenerlebnis verbessern und die Kaufwahrscheinlichkeit erhöhen (De Jesus, 2018[51]). AR könnte somit das Wachstum der Onlinemärkte und der Online-Werbeeinnahmen beflügeln.
KI in der Wissenschaft
Die Zahl der globalen Herausforderungen wächst, vom Klimawandel bis zur Antibiotikaresistenz von Bakterien. Viele dieser Herausforderungen lassen sich nur lösen, wenn der Kenntnisstand der Wissenschaft wächst. In einer Zeit, von der einige behaupten, dass es zunehmend schwer wird, neue Ideen zu entwickeln, könnte KI die Produktivität der Wissenschaft erhöhen (Bloom et al., 2017[52]). Eine solche Produktivitätssteigerung wäre auch angesichts knapper öffentlicher Forschungsbudgets zu begrüßen. Um neue Erkenntnisse zu gewinnen, müssen riesige Mengen wissenschaftlicher Daten, die mit neuen wissenschaftlichen Instrumenten generiert werden, analysiert werden. Der Einsatz von KI wird hier unverzichtbar. Da zudem die Menge an wissenschaftlichen Aufsätzen weiter wächst und die Grenze dessen, was die Wissenschaftlerinnen und Wissenschaftler lesen können, bereits erreicht sein dürfte, werden sie zur Auswertung von Forschungsergebnissen immer mehr auf die Unterstützung von KI angewiesen sein.5
KI kann in der Wissenschaft auch neue Formen wissenschaftlicher Entdeckung ermöglichen und die Reproduzierbarkeit wissenschaftlicher Forschung verbessern. Die Zahl wissenschaftlicher und industrieller Anwendungen von KI nimmt zu, ebenso wie ihre Bedeutung. Mit KI gelang es beispielsweise, das Verhalten chaotischer Systeme vorherzusagen, komplexe Rechenprobleme in der Genetik zu lösen, die Qualität der Astrofotografie zu verbessern und mehr über die Regeln der chemischen Synthese zu erfahren. Darüber hinaus wird KI u. a. auch zur Analyse großer Datensätze, zur Hypothesengenerierung, zur Analyse wissenschaftlicher Literatur und zur Erleichterung der Datenerfassung, des experimentellen Designs und der Versuchsdurchführung eingesetzt.
Treiber der KI in der Wissenschaft
Verschiedene Formen von KI werden bereits seit Längerem in der Wissenschaft eingesetzt, wenn auch zunächst nur sporadisch. Schon in den 1960er Jahren half das KI-Programm DENDRAL, chemische Strukturen zu erkennen. In den 1970er Jahren unterstützte eine als Automated Mathematician bekannte KI die mathematische Forschung. Seitdem wurden Computerhardware und -software erheblich verbessert, und die Datenverfügbarkeit hat deutlich zugenommen. Auch andere Faktoren begünstigen den Einsatz von KI in der Wissenschaft: KI ist zumindest im gewerblichen Bereich gut finanziert, wissenschaftliche Daten liegen in zunehmend großen Mengen vor, Hochleistungsrechner werden immer besser, und Wissenschaftler haben nun Zugang zu Open-Source-Code für künstliche Intelligenz.
Vielfältige KI-Anwendungen in der Wissenschaft
KI wird in vielen Forschungsbereichen eingesetzt. In der Teilchenphysik wird sie z. B. häufig genutzt, um komplexe räumliche Muster in riesigen Datenströmen zu finden, die von Teilchendetektoren erzeugt wurden. Durch die Verarbeitung von Daten aus den sozialen Medien gibt KI Auskunft über Zusammenhänge zwischen Sprachgebrauch, Psychologie und Gesundheit sowie sozialen und wirtschaftlichen Entwicklungen. KI hilft u. a. auch bei der Lösung komplexer Rechenprobleme in der Genetik, der Verbesserung der Qualität der Bildgebung in der Astronomie und bei der Entschlüsselung der Regeln der chemischen Synthese (OECD, 2018[53]). KI-Anwendungen dürften in Zukunft immer häufiger und in immer größerem Umfang eingesetzt werden. Je weiter der Prozess des automatisierten maschinellen Lernens fortschreitet, desto leichter kann KI von Wissenschaftlern, Unternehmen und anderen Anwendern eingesetzt werden.
Fortschritte hat es auch in der KI-gestützten Hypothesengenerierung gegeben. Beispielsweise hat IBM mit KnIT ein Prototypsystem entwickelt, mit dem durch Mining-Methoden Informationen aus der wissenschaftlichen Literatur gewonnen werden. Das System stellt diese Informationen explizit in einem abfragbaren Netzwerk dar und zieht aus diesen Daten Schlüsse, um neue, testbare Hypothesen zu generieren. KnIT hat durch Text-Mining veröffentlichte Literatur analysiert, um Informationen über neue Kinasen zu gewinnen –Enzyme, die den Transfer von Phosphatgruppen hochenergetischer, phosphatspendender Moleküle auf bestimmte Substrate katalysieren. Dabei ging es um Kinasen, die ein Tumorsuppressorprotein phosphorylieren (Spangler et al., 2014[54]).
KI erleichtert auch die Überprüfung, das Verständnis und die Analyse wissenschaftlicher Literatur. Durch maschinelle Sprachverarbeitung ist es inzwischen möglich, sowohl Bezüge als auch Kontexte automatisch aus wissenschaftlichen Aufsätzen zu extrahieren. Das System KnIT ermöglicht es z. B., durch Text-Mining der wissenschaftlichen Literatur automatisch Hypothesen zu generieren. Das Start-up-Unternehmen Iris.AI6 bietet ein kostenloses Tool an, um Schlüsselkonzepte aus Forschungsabstracts zu extrahieren. Dabei werden die Konzepte visuell dargestellt, damit der Benutzer interdisziplinäre Zusammenhänge erkennen kann. Außerdem stellt dieses Tool relevante Arbeiten aus einer Bibliothek mit über 66 Millionen frei zugänglichen Veröffentlichungen zusammen.
KI unterstützt die Erhebung großer Datenmengen. In der Bürgerwissenschaft (Citizen- Science) beispielsweise nutzen Anwendungen KI, um Nutzern bei der Identifizierung unbekannter Tier- und Pflanzenproben zu helfen (Matchar, 2017[55]).
KI kann auch in einem geschlossenen Forschungskreislauf mit Robotersystemen kombiniert werden
Die Konvergenz von KI und Robotertechnik birgt viele potenzielle Vorteile für die Wissenschaft. Laborautomationssysteme können Techniken aus dem KI-Bereich physikalisch nutzen, um wissenschaftliche Experimente durchzuführen. In einem Labor der Universität Aberystwyth in Wales z. B. verwendet der Roboter Adam KI-Techniken, um Zyklen wissenschaftlicher Experimente automatisch durchzuführen. Er gilt als die erste Maschine, die selbstständig neue wissenschaftliche Erkenntnisse gewinnen kann. So entdeckte er die Verbindung Triclosan, die gegen die wildtypischen, arzneimittelresistenten Parasiten Plasmodium falciparum und Plasmodium vivax wirkt (King et al., 2004[56]). Eine vollautomatisierte Forschung könnte verschiedene Vorteile haben (OECD, 2018[57]):
Schnellere Gewinnung wissenschaftlicher Erkenntnisse: Automatisierte Systeme können Tausende von Hypothesen parallel generieren und überprüfen. Die kognitiven Fähigkeiten des Menschen reichen hingegen nur aus, um ein paar Hypothesen gleichzeitig zu untersuchen (King et al., 2004[56]).
Kostengünstigeres Experimentieren: KI-Systeme können Experimente auswählen, deren Durchführung weniger kostenintensiv ist (Williams et al., 2015[58]). Dank ihrer Leistungsfähigkeit können sie unbekannte Versuchslandschaften effizient erforschen und nutzen. Dadurch könnte es z. B. möglich sein, neue Medikamente (Segler, M., M. Preuss und M. Waller, 2018[59]), Materialien (Butler et al., 2018[60]) und Geräte zu entwickeln (Kim et al., 2017[61]).
Einfachere Ausbildung: Die Ausbildung eines menschlichen Wissenschaftlers kann über zwanzig Jahre dauern und erfordert enorme Ressourcen. Menschen können sich Wissen nur langsam durch Unterricht und Erfahrung aneignen. Roboter hingegen können Wissen direkt voneinander übernehmen.
Verbesserter Wissens- und Datenaustausch und wissenschaftliche Reproduzierbarkeit: Eine der wichtigsten Fragen in der Biologie – und anderen wissenschaftlichen Bereichen – ist die Reproduzierbarkeit. Roboter besitzen die dem Menschen versagte Fähigkeit, experimentelle Handlungen und deren Ergebnisse einschließlich der entsprechenden Metadaten und Verfahren automatisch, vollständig und nach anerkannten Standards aufzuzeichnen, ohne dass dadurch zusätzliche Kosten entstehen. Von Menschen durchgeführte Experimente werden hingegen um bis zu 15 % teurer, wenn dabei Daten, Metadaten und Verfahren erfasst werden.
Für die meisten wissenschaftlichen und technischen Bereiche ist Laborautomation von entscheidender Bedeutung. Aufgrund der geringen Zahl verkaufter Geräte und der mangelnden Marktreife ist sie jedoch teuer und schwierig anzuwenden. Folglich ist der Einsatz von Laborautomation an großen zentralen Standorten am wirtschaftlichsten. Deshalb wird Laborautomation in Unternehmen und Universitäten zunehmend gebündelt. Das beste Beispiel für diesen Trend ist die Cloud-Automatisierung, bei der eine große Zahl an Geräten an einem einzigen Standort bereitgestellt wird. Biologen senden dann z. B. ihre Proben ein und nutzen eine Anwendung, die ihnen beim Aufbau ihrer Experimente hilft.
Politische Grundsatzfragen
Der zunehmende Einsatz von KI-Systemen in der Wissenschaft könnte sich auch auf soziologische, institutionelle und sonstige Aspekte auswirken, z. B. auf den Wissenstransfer, auf die Systeme für die Anerkennung wissenschaftlicher Entdeckungen, auf das Peer-Review-Prinzip und auf die Systeme zum Schutz von geistigem Eigentum. Je umfassender KI in der Welt der Wissenschaft genutzt wird, umso wichtiger werden Regelungen in Bezug auf Datenzugang und Hochleistungsrechnen. Überdies wirft die zunehmend wichtige Rolle, die KI bei Neuentdeckungen spielt, neue, noch unbeantwortete Fragen auf: Sollten Maschinen in akademischen Veröffentlichungen zitiert werden? Müssen die Systeme zum Schutz von geistigem Eigentum in einer Welt, in der Maschinen erfinden können, umgestaltet werden? Wie steht es um die grundsätzliche Frage der Aus- und Weiterbildung (OECD, 2018[57])?
KI im Gesundheitswesen
Hintergrund
KI-Anwendungen in der Pharma- und Gesundheitsbranche können helfen, Erkrankungen frühzeitig zu erkennen, Präventionsleistungen zu erbringen, die klinische Entscheidungsfindung zu optimieren und neue Behandlungsmethoden und Medikamente zu entdecken. Dank KI-gestützter Instrumente, Anwendungen und Trackern zur Beobachtung von Körperdaten können sie den Weg für eine personalisierte Gesundheitsversorgung und Präzisionsmedizin ebnen. Durch KI könnten sich Vorteile sowohl in Bezug auf die Qualität als auch auf die Kosten der Versorgung ergeben. Der Einsatz von KI wirft jedoch einige Grundsatzfragen auf, insbesondere im Hinblick auf den Zugang zu (Gesundheits-)Daten und den Datenschutz (vgl. Unterabschnitt „Schutz personenbezogener Daten“ in Kapitel 4). Dieser Abschnitt befasst sich hauptsächlich mit den speziellen Auswirkungen der KI auf das Gesundheitswesen.
In gewisser Weise ist der Gesundheitssektor eine ideale Plattform für KI-Systeme und ein hervorragendes Beispiel für ihre möglichen Auswirkungen. Als wissensintensiver Sektor ist er auf Daten und Analysen angewiesen, um Therapien und Praktiken zu verbessern. Die Bandbreite der gesammelten Informationen, darunter klinische, genetische, verhaltens- und umweltbezogene Daten, hat stark zugenommen. Täglich produzieren Gesundheitsfachkräfte, biomedizinische Forscher und Patienten mit einer Vielzahl von Geräten eine gewaltige Menge an Daten, z. B. durch elektronische Patientenakten (ePA), Genomsequenzierer, hochauflösende medizinische Bildgebung, Smartphone-Anwendungen und Sensoren sowie IoT-Geräte zur Überwachung des Gesundheitszustands der Patienten (OECD, 2015[62]).
Positive Effekte der KI auf die Gesundheitsversorgung
Die Auswertung der durch KI generierten Daten könnte für die medizinische Versorgung und Forschung von großem Nutzen sein. Durch die Nutzung der Chancen, die die Informations- und Kommunikationstechnologien bieten, erfährt der Gesundheitssektor derzeit länderübergreifend einen tiefgreifenden Wandel. Hauptziel ist dabei die Verbesserung der Effizienz, der Produktivität und der Qualität der Versorgung (OECD, 2017[26]).
Konkrete Beispiele
Verbesserung der Patientenversorgung: Durch die sekundäre Nutzung von Gesundheitsdaten kann die Qualität und Wirksamkeit der Patientenversorgung sowohl in der klinischen als auch in der häuslichen Pflege verbessert werden. So können KI-Systeme beispielsweise das administrative oder klinische Personal warnen, wenn Messgrößen für Qualität und Patientensicherheit außerhalb des Normbereichs liegen. Außerdem können sie auf Faktoren hinweisen, die möglicherweise für diese Abweichungen verantwortlich sind (Canadian Institute for Health Information, 2013[63]). Ein besonderer Aspekt der Verbesserung der Patientenversorgung ist die Präzisionsmedizin, die auf der schnellen Verarbeitung vieler komplexer Datensätze beruht, z. B. Patientenakten, physiologischer Reaktionen und genomischer Daten. Ein weiterer Aspekt ist die mobile Gesundheit: Mobile Technologien bieten hilfreiches Echtzeit-Feedback über das gesamte Versorgungsspektrum – von der Prävention über die Diagnose und Behandlung bis hin zur Überwachung von Körperdaten. In Verbindung mit anderen personenbezogenen Daten wie Standortinformationen und Präferenzen können KI-gestützte Technologien risikoreiche Verhaltensweisen erkennen oder vorteilhafte Verhaltensweisen fördern. So können sie personalisiert ein gesünderes Verhalten fördern (z. B. Treppen steigen statt mit dem Fahrstuhl fahren, Wasser trinken oder mehr zu Fuß gehen). Ebenso wie sensorbasierte Monitoringsysteme ermöglichen diese Technologien ein kontinuierliches und direktes Monitoring sowie auf individuelle Bedürfnisse zugeschnittene Maßnahmen. Sie können daher besonders nützlich sein, um die Qualität der Altenpflege und der Betreuung von Menschen mit Behinderungen zu verbessern (OECD, 2015[62]).
Management von Gesundheitssystemen: Gesundheitsdaten können in Entscheidungen über Programme, Maßnahmen und Finanzierungen einfließen. Auf diese Weise können sie das Management von Gesundheitssystemen erleichtern und zur Verbesserung ihrer Effektivität und Effizienz beitragen. Beispielsweise können KI-Systeme erkennen, wenn Behandlungsmaßnahmen ineffektiv sind, Chancen verpasst oder Leistungen doppelt erbracht werden und so Kosten senken. Sie können auf vier Arten den Zugang zur Gesundheitsversorgung verbessern und Wartezeiten verkürzen: 1. KI-Systeme sind in der Lage zu analysieren, welche Versorgungsetappen der Patient durchlaufen muss. 2. Sie sorgen dafür, dass die Patienten die für ihre Bedürfnisse am besten geeigneten Leistungen erhalten. 3. Sie können zukünftige Gesundheitsbedürfnisse der Bevölkerung vorhersagen. 4. Sie optimieren die Ressourcenallokation im gesamten System (Canadian Institute for Health Information, 2013[63]). Vor dem Hintergrund des zunehmenden Monitorings von Therapien und Ereignissen im Zusammenhang mit Arzneimitteln und Medizinprodukten (OECD, 2015[62]) können Länder KI nutzen, um Muster besser zu erkennen, z. B. systemische Erfolge oder Misserfolge. Darüber hinaus fördern datengesteuerte Innovationen die Vision eines „lernenden Gesundheitssystems“, das in der Lage ist, kontinuierlich neue Daten von Forschern, Leistungserbringern und Patienten einzubeziehen. Dadurch können umfangreiche klinische Algorithmen verbessert werden, die an bestimmten Entscheidungsknoten der klinischen Versorgung helfen zu bestimmen, welches die optimale Vorgehensweise ist (OECD, 2015[62]).
Analyse und Lösung von Fragen der öffentlichen Gesundheit: Daten können nicht nur für eine zeitnahe Überwachung von Gesundheitskrisen wie Grippe-Epidemien und anderen Viruserkrankungen verwendet werden, sondern auch, um unerwartete Nebenwirkungen und Kontraindikationen neuer Arzneimittel zu erkennen (Canadian Institute for Health Information, 2013[63]). KI-Technologien ermöglichen es, Krankheitsausbrüche frühzeitig zu erkennen und ihre Ausbreitung zu überwachen. Über die sozialen Medien ist es beispielsweise möglich, Informationen, die die öffentliche Gesundheit betreffen, zu erhalten und zu verbreiten. KI kann Instrumente der maschinellen Sprachverarbeitung (NLP) nutzen, um Beiträge in sozialen Medien zu analysieren und ihnen Informationen über potenzielle Nebenwirkungen zu entnehmen (Comfort et al., 2018[64]; Patton, 2018[65]).
Förderung der Gesundheitsforschung: Gesundheitsdaten können die klinische Forschung unterstützen und die Entdeckung neuer Therapien beschleunigen. Durch Big-Data-Analysen ergeben sich neue, leistungsfähigere Optionen zur Beobachtung von Krankheitsverlauf und Gesundheitszustand. Dies kann eine verbesserte Diagnose und Versorgung ermöglichen und auch die translationale und klinische Forschung unterstützen, z. B. zur Entwicklung neuer Arzneimittel. 2015 arbeitete das Pharmaunternehmen Atomwise beispielsweise mit Forschern der Universität Toronto und IBM zusammen, um KI-Technologie bei der Suche nach einem Mittel gegen das Ebola-Virus einzusetzen.7 Auch in der medizinischen Diagnostik wird zunehmend mit KI experimentiert. Ein Meilenstein war hier die Entscheidung der Food and Drug Administration der Vereinigten Staaten, die Vermarktung des ersten medizinischen Geräts zuzulassen, das KI einsetzt, um bei diabeteskranken Erwachsenen eine über die milde Form hinausgehende diabetische Retinopathie zu erkennen (FDA, 2018[66]). Techniken des maschinellen Lernens können zudem herangezogen werden, um Modelle zur Klassifizierung von Bildern des Auges zu trainieren. So könnten z. B. Kataraktdetektoren entwickelt werden, die in Smartphones integriert und damit auch in entlegenen Gebieten eingesetzt werden könnten (Lee, 2017[67]; Patton, 2018[65]). In einer neueren Studie wurden einem Deep-Learning-Algorithmus mehr als 100 000 Bilder von bösartigen Melanomen und gutartigen Muttermalen zugeführt. Am Ende war dieser Algorithmus erfolgreicher bei der Erkennung von Hautkrebs als eine Gruppe von 58 internationalen Dermatologen (Mar, 2018[68]).
KI im Gesundheitswesen – Erfolgs- und Risikofaktoren
Es bedarf einer ausreichenden Infrastruktur und Mechanismen der Risikominderung, um die Möglichkeiten der KI im Gesundheitssektor voll auszuschöpfen.
In den verschiedenen Ländern werden zunehmend Systeme für elektronische Patientenakten eingerichtet und mobile Gesundheitstechnologien (m-health) eingeführt (OECD, 2017[69]). Eine Studie lieferte stichhaltige Belege dafür, dass elektronische Patientenakten zur Reduzierung von Medikationsfehlern und zu einer besseren Koordination der Gesundheitsversorgung beitragen können (OECD, 2017[26]). Die gleiche Studie zeigte aber auch, dass es bislang nur wenigen Ländern gelungen ist, solche Technologien umfassend zu integrieren und die Möglichkeiten der Datenextraktion aus elektronischen Patientenakten für Forschung, Statistik und andere sekundäre Anwendungen zu nutzen. Silostrukturen mit getrennter Datenerfassung und -analyse sind im Gesundheitssystem immer noch die Regel. Deshalb sind Standards und Interoperabilität zentrale Herausforderungen, die angegangen werden müssen, um das Potenzial elektronischer Patientenakten voll auszuschöpfen (OECD, 2017[26]).
Ein weiterer kritischer Faktor für den Einsatz von KI im Gesundheitssektor ist die Minimierung der Datenschutzrisiken für die Betroffenen. Die Risiken, die bei einer verstärkten Erfassung und Verarbeitung personenbezogener Daten bestehen, werden ausführlich im Unterabschnitt „Schutz personenbezogener Daten“ in Kapitel 4 beschrieben. Dieser Unterabschnitt befasst sich mit der hohen Sensibilität gesundheitsbezogener Daten. Bias-bedingte Fehlleistungen eines Algorithmus, der eine bestimmte Behandlung empfiehlt, könnten in einigen Gruppen zu echten Gesundheitsrisiken führen. Andere Datenschutzrisiken sind Besonderheiten des Gesundheitssektors. Beispielsweise stellt sich die Frage, ob Daten aus implantierbaren Medizinprodukten wie Herzschrittmachern als Beweismittel vor Gericht verwendet werden können.8 Da solche Medizinprodukte zudem immer komplexer werden, können die an sie geknüpften Sicherheitsrisiken steigen, wie z. B. das Risiko eines böswilligen Eingriffs in das System, um einen schädlichen Vorgang auszuführen. Die Verwendung biologischer Proben (z. B. Gewebe) für maschinelles Lernen ist ein weiteres Beispiel, das komplexe Einwilligungs- und Eigentumsfragen aufwirft (OECD, 2015[62]; Ornstein, C. und K. Thomas, 2018[70]).9
Aufgrund solcher Bedenken verweisen viele OECD-Länder auf rechtliche Hindernisse bei der Verwendung personenbezogener Gesundheitsdaten. Zu diesen Hindernissen gehören die Deaktivierung von Datenverknüpfungen und Hemmnisse für die Entwicklung von Datenbanken aus elektronischen Patientenakten. Die OECD-Ratsempfehlung zur Governance von Gesundheitsdaten aus dem Jahr 2016 ist ein wichtiger Schritt auf dem Weg zu einem kohärenteren Ansatz für die Verwaltung und Nutzung von Gesundheitsdaten (OECD, 2016[71]). Sie zielt in erster Linie darauf ab, die Einrichtung und Umsetzung eines nationalen Governance-Rahmens für Gesundheitsdaten zu fördern. Ein solcher Rahmen würde die Verfügbarkeit und Verwendung personenbezogener Gesundheitsdaten im öffentlichen Interesse begünstigen und zugleich den Schutz von Persönlichkeitsrechten und personenbezogenen Gesundheitsdaten sowie die Datensicherheit stärken. Ein kohärenter Ansatz in der Datenverwaltung könnte dazu beitragen, den Zielkonflikt zwischen Datennutzung und Datensicherheit zu überwinden.
Die Einbeziehung aller relevanten Akteure trägt maßgeblich dazu bei, Vertrauen zu schaffen und die öffentliche Akzeptanz des Einsatzes von KI und der Erfassung von Daten für Gesundheitszwecke zu erhöhen. Die zuständigen staatlichen Stellen könnten Schulungsprogramme für speziell mit Gesundheitsdaten befasste Datenwissenschaftler konzipieren oder Datenwissenschaftler mit Gesundheitsfachkräften zusammenbringen. Auf diese Weise könnten sie zu einem besseren Verständnis der Chancen und Risiken in diesem neuen Bereich beitragen (OECD, 2015[62]). Die Einbeziehung medizinischer Fachkräfte in das Design und die Entwicklung von KI-Gesundheitssystemen könnte sich als unerlässlich erweisen, damit Patienten und Leistungserbringer KI-basierten Gesundheitsprodukten und -dienstleistungen Vertrauen schenken.
KI in der Strafverfolgung
KI und prädiktive Algorithmen für die Justiz
Künstliche Intelligenz kann den Zugang zur Justiz verbessern und eine effektive und unparteiische Rechtsprechung fördern. Bedenken bestehen jedoch wegen der Fragen, die KI-Systeme im Hinblick auf Bürgerbeteiligung, Transparenz, Würde, Persönlichkeitsrechte und Freiheit aufwerfen könnten. Dieser Abschnitt befasst sich hauptsächlich mit KI-Fortschritten im Bereich der Strafverfolgung, geht jedoch auch auf Entwicklungen in anderen Rechtsgebieten ein.
KI wird zunehmend in verschiedenen strafrechtlichen Abläufen eingesetzt, u. a. um vorherzusagen, wo Verbrechen begangen werden könnten oder wie ein bestimmtes Strafverfahren ausgehen wird, das von einem Angeklagten ausgehende Risiko zu bewerten oder zu einer effizienteren Prozessführung beizutragen. Viele KI-Anwendungen sind zwar noch in der Erprobung, einige ausgereifte Prognoseprodukte werden jedoch bereits in der Justizverwaltung und im Gesetzesvollzug eingesetzt. Mit KI lassen sich u. U. besser Verbindungen herstellen, Muster erkennen sowie Verbrechen verhindern und aufklären (Wyllie, 2013[72]). Der zunehmende Einsatz solcher Instrumente folgt dem generellen Trend, sich auf faktenbasierte Methoden zu stützen, die eine effizientere, rationellere und kostengünstigere Nutzung der knappen Ressourcen für den Gesetzesvollzug gewährleisten (Horgan, 2008[73]).
Die Strafjustiz ist ein kritischer Kontaktpunkt zwischen Staat und Bürgern, an dem Macht- und Informationsgefälle besonders deutlich zum Ausdruck kommen. Ohne hinreichende Sicherheitsmechanismen kann es hier zu überproportional negativen Effekten kommen, können systemische Benachteiligungen verstärkt werden oder möglicherweise sogar neue Benachteiligungen entstehen (Barocas, S. und A. Selbst, 2016[74]).
Vorausschauende Polizeiarbeit
Beim Predictive Policing („vorausschauende Polizeiarbeit“) wird KI zur Mustererkennung eingesetzt, um statistische Vorhersagen über potenzielle kriminelle Tätigkeiten zu treffen (Ferguson, 2014[75]). Bereits vor der Einführung von KI wurden in der Polizeiarbeit prädiktive Verfahren eingesetzt. So wurde beispielsweise gesammeltes Datenmaterial analysiert, um Städte in Viertel mit hohem und niedrigem Kriminalitätsrisiko einzuteilen (Brayne, S., A. Rosenblat und D. Boyd, 2015[76]). Dank KI können nun mehrere Datensätze miteinander verknüpft sowie komplexe und feinkörnigere Analysen durchgeführt werden, die präzisere Vorhersagen ermöglichen. Automatische Nummernschilderfassung, ein engmaschiges Kameranetz, eine zunehmend kostengünstige Datenspeicherung und erweiterte Rechenkapazitäten können es der Polizei gestatten, wesentliche Daten über eine große Zahl von Personen zu gewinnen. Anhand dieser Daten kann die Polizei dann Muster – d. h. auch kriminelle Verhaltensmuster – erkennen (Joh, 2017[77]).
Im Predictive Policing werden zwei Herangehensweisen unterschieden. Bei der ortsbezogenen Vorhersage werden retrospektive Kriminalitätsdaten genutzt, um vorherzusagen, wann und wo Verbrechen verübt werden könnten. Zu den berücksichtigten Orten können Spirituosengeschäfte, Bars und Parks gehören, in denen in der Vergangenheit bestimmte Verbrechen begangen wurden. Die Polizei kann dann einen Beamten entsenden, der an einem bestimmten Wochentag bzw. zu einer bestimmten Uhrzeit in diesen Bereichen auf Streife geht, um Verbrechen vorzubeugen. Bei der personenbezogenen Vorhersage ziehen die Strafverfolgungsbehörden Kriminalstatistiken heran, um vorherzusagen, welche Personen oder Gruppen mit besonders großer Wahrscheinlichkeit mit Verbrechen in Berührung kommen, sei es als Opfer oder als Täter.
KI-gestützte Initiativen für die vorausschauende Polizeiarbeit werden in Städten auf der ganzen Welt erprobt, so z. B. in Manchester, Durham, Bogota, London, Madrid, Kopenhagen und Singapur. Im Vereinigten Königreich hat die Greater Manchester Police 2012 ein prädiktives System zur Verbrechenskartierung entwickelt. In der Grafschaft Kent setzt die Polizei seit 2013 das System PredPol ein. Diese beiden Systeme schätzen die Wahrscheinlichkeit von an bestimmten Orten während eines bestimmten Zeitfensters verübten Verbrechen. Sie beruhen auf einem Algorithmus, der ursprünglich zur Vorhersage von Erdbeben entwickelt wurde.
In Bogota (Kolumbien) nutzt die Data-Pop Alliance Kriminalitäts- und Verkehrsdaten, um Kriminalitätsbrennpunkte zu ermitteln. Die Polizeikräfte werden dann gezielt an den Orten und zu den Uhrzeiten eingesetzt, an denen das Kriminalitätsrisiko besonders hoch ist.
Viele Polizeibehörden stützen sich zudem zu unterschiedlichen Zwecken auf die sozialen Medien, beispielsweise zur Aufdeckung krimineller Tätigkeiten, zur Erlangung von Durchsuchungsbefehlen auf der Basis eines konkretisierten Anfangsverdachts oder zur Sammlung von Beweismitteln für Gerichtsverhandlungen. Sie nutzen die sozialen Medien auch zur Ermittlung der Aufenthaltsorte von Straftätern, für den Umgang mit unberechenbaren Situationen, zur Identifizierung von Zeugen, zur Verbreitung von Informationen und für Bitten um Hinweise aus der Öffentlichkeit (Mateescu et al., 2015[78]).
Allerdings wirft der Einsatz künstlicher Intelligenz auch Fragen in Bezug auf die Verwendung personenbezogener Daten (vgl. Unterabschnitt „Schutz personenbezogener Daten“ in Kapitel 4) und Bias-Risiken (vgl. Unterabschnitt „Fairness und Ethik“ in Kapitel 4) auf. Insbesondere ihre z. T. mangelnde Transparenz und ihre nicht immer nachvollziehbare Funktionsweise ist ein heikler Punkt, der Anlass zu Besorgnis gibt. Ein Ansatz zur Erhöhung der Transparenz von Algorithmen ist das im Vereinigten Königreich angewandte Tool ALGO-CARE. Mit ihm soll sichergestellt werden, dass die Polizei bei der Nutzung algorithmischer Instrumente zur Risikobewertung rechtliche und praxisrelevante Grundregeln berücksichtigt (Burgess, 2018[79]). Grundsätze des öffentlichen Rechts und der Menschenrechte werden dabei in praktische Begriffe und Leitlinien für Polizeibehörden umgesetzt.
Nutzung von KI durch die Justiz
In vielen Staaten wird KI von der Justiz hauptsächlich zur Risikobewertung eingesetzt. Risikobewertungen fließen in eine Reihe von strafrechtlichen Entscheidungen ein, z. B. bei der Festlegung der Kautionshöhe oder anderer Bedingungen für Haftentlassungen und Strafaussetzungen zur Bewährung (Kehl, D., P. Guo und S. Kessler, 2017[80]). Richter nutzen seit Langem mathematisch-statistische Instrumente zur Risikobewertung, der Übergang zur KI war daher eine logische Entwicklung (Christin, A., A. Rosenblat und D. Boyd, 2015[81]). Forscher des Berkman Klein Center an der Harvard-Universität arbeiten gegenwärtig an einer Datenbank, in der alle Instrumente zur Risikobewertung erfasst werden sollen, die in den Strafjustizsystemen der Vereinigten Staaten zur Unterstützung des Entscheidungsprozesses eingesetzt werden (Bavitz, C. und K. Hessekiel, 2018[82]).
Algorithmen zur Risikobewertung prognostizieren das Risikoniveau auf der Basis einer kleinen Anzahl von Faktoren, die in der Regel in zwei Gruppen unterteilt sind. Dies sind zum einen Strafregistereinträge (z. B. frühere Verhaftungen und Verurteilungen oder Vorladungen vor Gericht, denen nicht Folge geleistet wurde) und zum anderen soziodemografische Merkmale (z. B. Alter, Geschlecht, Beschäftigung und Aufenthaltsstatus). Prädiktive Algorithmen fassen die relevanten Informationen zusammen, um ausgehend davon Entscheidungen zu treffen. Dabei sollen sie effizienter sein als das menschliche Gehirn, da sie größere Datenmengen rascher verarbeiten können und weniger durch Vorurteile beeinflusst sein dürften (Christin, A., A. Rosenblat und D. Boyd, 2015[81]).
KI-basierte Instrumente zur Risikobewertung, die von Privatunternehmen entwickelt werden, wecken jedoch Bedenken im Hinblick auf ihre Transparenz und Nachvollziehbarkeit. Dies liegt daran, dass Geheimhaltungsvereinbarungen häufig den Zugang zu proprietärem Code verhindern, um geistiges Eigentum zu schützen oder böswilligen Handlungen vorzubeugen (Joh, 2017[77]). Ohne Zugriff auf den Code ist es nur begrenzt möglich, die Gültigkeit und Zuverlässigkeit der Instrumente zu überprüfen.
Ein interessantes Beispiel hierfür ist das in einigen US-Bundesstaaten eingesetzte proprietäre Instrument COMPAS, das von der gemeinnützigen Nachrichtenredaktion ProPublica einem Test unterzogen wurde. ProPublica fand heraus, dass die Vorhersagen von COMPAS für alle Formen der Kriminalität zusammengenommen eine Genauigkeit von durchschnittlich 60 % aufwiesen. Die Vorhersagegenauigkeit für Gewaltverbrechen betrug jedoch nur 20 %. Darüber hinaus traten bei der Studie Unterschiede je nach Hautfarbe der Betroffenen zutage: Schwarze wurden von dem Algorithmus doppelt so häufig fälschlicherweise als zukünftige Straftäter eingestuft wie Weiße (Angwin et al., 2016[83]). Die Studie erregte die Aufmerksamkeit der Medien, und ihre Ergebnisse wurden auf der Basis statistischer Fehler infrage gestellt (Flores, A., K. Bechtel und C. Lowenkamp, 2016[84]). COMPAS ist ein sog. „Black-Box“-Algorithmus. Das bedeutet, dass niemand Zugriff auf den Quellcode hat – auch nicht seine Anwender.
Die Nutzung von COMPAS wurde gerichtlich angefochten. Seinen Gegnern zufolge verletze sein proprietärer Charakter das Recht des Angeklagten auf ein faires Gerichtsverfahren. Der Oberste Gerichtshof von Wisconsin hat den Einsatz von COMPAS bei der Strafzumessung gebilligt. Es muss jedoch ein unterstützendes Instrument bleiben, und der Richter muss nach wie vor nach eigenem Ermessen bestimmen können, welche weiteren Faktoren zu berücksichtigen sind und welches Gewicht ihnen beizumessen ist.10 Der Oberste Gerichtshof der Vereinigten Staaten lehnte einen Antrag auf Anhörung des Falls ab.11
Kleinberg et al. (2017[85]) entwickelten im Rahmen einer anderen Studie, die sich mit den Auswirkungen von KI auf die Strafjustiz befasst, einen ML-Algorithmus. Dieser Algorithmus sollte vorhersagen, welche Angeklagten im Zeitraum bis zum Gerichtsprozess eine weitere Straftat begehen würden oder versuchen würden, sich der Justiz zu entziehen. Die Eingangsvariablen waren bekannt. Der Algorithmus sollte die relevanten Unterkategorien und ihr jeweiliges Gewicht bestimmen. Für die Altersvariable beispielsweise bestimmte der Algorithmus die Altersstufen mit der größten statistischen Signifikanz, nämlich 18-25 und 25-30 Jahre. Die Autoren stellten fest, dass dieser Algorithmus die Inhaftierungsquoten und die Risiken einer Ungleichbehandlung von Personen unterschiedlicher Hautfarbe erheblich reduzieren könnte. Der Algorithmus verringerte nach Ansicht der Autoren auch die Verzerrungen durch menschliche Vorurteile. Sie kamen zu dem Schluss, dass alle Informationen, die über die für die Vorhersage notwendigen Elemente hinausgehen, die Richter ablenken und das Risiko verzerrter Urteile erhöhen könnten.
Moderne KI-gestützte Instrumente zur Risikobewertung werden auch im Vereinigten Königreich eingesetzt. Bei der Polizei von Durham wurde das sog. Harm Assessment Risk Tool entwickelt, um das Rückfallrisiko von verurteilten Straftätern zu bewerten. Das Instrument basiert auf den vergangenen Gesetzesverstößen der betreffenden Personen, ihrem Alter, ihrer Postleitzahl und anderen Hintergrundmerkmalen. Anhand dieser Indikatoren wird das mit ihnen verbundene Risiko vom Algorithmus als gering, mittel oder hoch eingestuft.
KI zur Vorhersage des Ausgangs gerichtlicher Verfahren
Unter Verwendung fortschrittlicher Sprachverarbeitungstechniken und Datenanalysefunktionen haben mehrere Forscher Algorithmen entwickelt, um den Ausgang gerichtlicher Verfahren mit hoher Genauigkeit vorherzusagen. Forscher des University College London und der Universitäten Sheffield und Pennsylvania haben beispielsweise einen ML-Algorithmus entwickelt, der das Ergebnis von vor dem Europäischen Gerichtshof für Menschenrechte verhandelten Verfahren mit einer Genauigkeit von 79 % vorhersagen kann (Aletras et al., 2016[86]). In einer weiteren Studie wurde von Forschern des Illinois Institute of Technology in Chicago ein Algorithmus entwickelt, der das Ergebnis von Rechtssachen, die vor dem Obersten Gerichtshof der Vereinigten Staaten entschieden werden, mit einer Genauigkeit von 79 % vorhersagen kann (Hutson, 2017[87]). Solche Algorithmen könnten den Parteien helfen, die Wahrscheinlichkeit eines Erfolgs im Straf- oder Rechtsmittelverfahren (auf der Basis ähnlicher früherer Fälle) zu beurteilen. Anwälte könnten mit ihnen eventuell auch leichter herausfinden, welche Punkte sie hervorheben müssen, um ihre Gewinnchancen zu erhöhen.
Andere Einsatzmöglichkeiten künstlicher Intelligenz in Rechtsverfahren
In zivilrechtlichen Verfahren wird KI vielfältig genutzt. Anwälte setzen künstliche Intelligenz für die Vertragsgestaltung, die Analyse von Dokumenten und die Extraktion von darin enthaltenen Informationen bei der Sachverhaltserforschung und bei Due-Diligence-Prüfungen ein (Marr, 2018[88]). Der Einsatz von KI könnte auf ähnliche Bereiche des Strafjustizsystems ausgedehnt werden, z. B. auf Verständigungen im Strafverfahren und Ermittlungen. Da sich die Gestaltung und Nutzung der Algorithmen auf die Ergebnisse auswirken könnte, müssen die Konsequenzen des Einsatzes der künstlichen Intelligenz allerdings sorgfältig geprüft werden.
KI im Sicherheitsbereich
Künstliche Intelligenz verspricht, zur Bewältigung komplexer digitaler und physischer Herausforderungen im Sicherheitsbereich beizutragen. Für 2018 wurde ein Anstieg der weltweiten Verteidigungsausgaben auf 1,67 Bill. USD erwartet, was im Vorjahresvergleich einer Zunahme um 3,3 % entspricht (IHS, 2017[89]). Die Sicherheit ist jedoch nicht nur eine Domäne des öffentlichen Sektors. Im privaten Sektor wurden 2018 Schätzungen zufolge Ausgaben in Höhe von 96 Mrd. USD getätigt, um Sicherheitsrisiken zu begegnen. Das entspricht einem Anstieg um 8 % gegenüber 2017 (Gartner, 2017[90]). Einige große Cyberangriffe haben in jüngster Zeit das Bewusstsein der Öffentlichkeit für digitale Sicherheit geschärft. Sie haben gezeigt, dass Datenschutzverletzungen weitreichende Folgen für Wirtschaft, Gesellschaft und nationale Sicherheit haben können. Vor diesem Hintergrund nutzen öffentliche und private Akteure zunehmend KI-Technologien, um sich an die sich weltweit verändernde Sicherheitslandschaft anzupassen. In diesem Abschnitt werden zwei sicherheitsrelevante Bereiche beschrieben, die ein besonders rasches Wachstum verzeichnen: digitale Sicherheit und Überwachung.12,13
KI und digitale Sicherheit
KI wird bereits umfassend in digitalen Sicherheitsanwendungen eingesetzt, z. B. in den Bereichen Netzwerksicherheit, Anomalieerkennung, Automatisierung von Sicherheitsoperationen und Gefahrenerkennung (OECD, 2017[26]). Gleichzeitig dürfte der Missbrauch von KI jedoch zunehmen, beispielsweise wenn Software-Schwachstellen aufgespürt und ausgenutzt werden, um die Verfügbarkeit, Integrität oder Vertraulichkeit von Systemen, Netzwerken und Daten zu verletzen. Dies wird sich auf Art und Gesamtumfang des digitalen Sicherheitsrisikos auswirken.
Zwei Trends bewirken, dass die Sicherheitsrelevanz von KI-Systemen steigt: die wachsende Zahl von Cyberangriffen und der Fachkräftemangel im Bereich digitale Sicherheit (ISACA, 2016[91]). Infolge dieser Trends werden ML-Anwendungen und KI-Systeme immer wichtiger, um die Erkennung und Abwehr von Bedrohungen zu automatisieren (MIT, 2018[92]). Da sich Malware ständig weiterentwickelt, ist maschinelles Lernen (ML) unerlässlich geworden, um Angriffe wie polymorphe Viren, Denial-of-Service-Attacken und Phishing zu bekämpfen.14 Tatsächlich wird maschinelles Lernen von führenden E-Mail-Anbietern wie Gmail und Outlook seit mehr als einem Jahrzehnt mit unterschiedlichem Erfolg eingesetzt, um unerwünschte oder schädliche E-Mail-Nachrichten zu filtern. Kasten 3.1 verdeutlicht, wie KI zum Schutz von Unternehmen vor böswilligen Bedrohungen eingesetzt werden kann.
Kasten 3.1. KI zur Steuerung digitaler Sicherheitsrisiken in Geschäftsumgebungen
Unternehmen wie Darktrace, Vectra und viele andere setzen maschinelles Lernen und künstliche Intelligenz ein, um Cyberangriffe in Echtzeit zu erkennen und abzuwehren. Darktrace setzt auf die Technologie Enterprise Immune System, die potenzielle Gefahren auch erkennen kann, ohne zuvor schon einmal eine ähnliche Bedrohung erlebt zu haben. KI-Algorithmen machen sich durch iteratives Lernen mit dem einzigartigen „Lebensmuster“ eines Netzwerks vertraut, um Bedrohungen zu erkennen, die andernfalls unbemerkt bleiben würden. Die Funktionsweise von Darktrace ist dem menschlichen Immunsystem nachempfunden, das lernt, was für den Körper normal ist, und das dieser Normalität nicht entsprechende Situationen automatisch erkennen und beseitigen kann.
Vectra macht mit seiner rund um die Uhr laufenden, automatisierten und ständig lernenden „Cognito-Plattform“ Jagd auf Angreifer in Cloud-Umgebungen. Diese Plattform macht das Verhalten von Angreifern vollkommen transparent, auf Cloud- und Rechenzentren-Workloads ebenso wie Benutzer- und IoT-Geräten. Auf diese Weise wird es für Angreifer immer schwieriger, unsichtbar zu agieren.
Quelle: www.darktrace.com/; https://vectra.ai/.
Computercode ist anfällig für menschliche Fehler. Schätzungen zufolge sind neun von zehn Cyberangriffen auf Fehler im Softwarecode zurückzuführen. Solche Fehler entstehen trotz der enorm hohen Entwicklungszeit, die für Tests aufgewendet wird – zwischen 50 % und 75 % (Oliver, 2018[93]). Angesichts der Milliarden von Zeilen Code, die jedes Jahr geschrieben werden, und der dafür genutzten proprietären Bibliotheken von Drittanbietern ist das Erkennen und Korrigieren von Fehlern im Softwarecode eine für den Menschen kaum noch zu bewältigende Aufgabe. Länder wie die Vereinigten Staaten und China finanzieren Forschungsprojekte, um KI-Systeme zu entwickeln, die Sicherheitslücken in Software erkennen können. Unternehmen wie der Videospielehersteller Ubisoft haben begonnen KI einzusetzen, die Fehler im Code kennzeichnen soll, bevor er implementiert wird. Dadurch lässt sich die Testzeit um 20 % reduzieren (Oliver, 2018[93]). In der Praxis funktionieren KI-Technologien zur Prüfung von Software wie die Rechtschreibprüfung in Textverarbeitungsprogrammen, die Tipp- und Syntaxfehler finden soll. KI-Technologien lernen jedoch dazu und werden mit der Zeit immer effizienter (Oliver, 2018[93]).
KI in der Überwachung
In vielen Städten wird die digitale Infrastruktur ausgebaut. Dies gilt insbesondere für den Überwachungsbereich, wo verschiedene KI-gestützte Instrumente und Geräte zur Erhöhung der öffentlichen Sicherheit eingesetzt werden. So können Smart-Kameras beispielsweise Schlägereien erkennen. Schussdetektoren können Schüsse automatisch melden und dabei genau angeben, wo sie gefallen sind. In diesem Abschnitt wird untersucht, wie künstliche Intelligenz die Welt der Sicherheit und Überwachung revolutioniert. Videoüberwachung wird mittlerweile immer häufiger eingesetzt, um die Sicherheit im öffentlichen Raum zu erhöhen. Laut Schätzungen einer im Vereinigten Königreich durchgeführten jüngeren Studie lieferten Sicherheitsaufnahmen verwertbare Beweise für 65 % der Verbrechen, die zwischen 2011 und 2015 im britischen Eisenbahnnetz begangen wurden und für die Bildmaterial zur Verfügung stand (Ashby, 2017[94]). Die hohe Zahl von Überwachungskameras – 2014 waren es weltweit 245 Millionen – hat zur Folge, dass immer mehr Daten erzeugt werden. Die an einem einzigen Tag produzierte Datenmenge erhöhte sich zwischen 2013 und 2017 von 413 Petabyte (PB) auf geschätzte 860 PB (Jenkins, 2015[95]), (Civardi, 2017[96]). Menschen sind nur bedingt in der Lage, so große Datenmengen zu verarbeiten. Die Nutzung von KI-Technologien zur Verarbeitung großer Datenmengen und Automatisierung mechanischer Erkennungs- und Kontrollprozesse bietet sich daher an. Sicherheitssysteme können zudem dank KI Verbrechen in Echtzeit erkennen und darauf reagieren (Kasten 3.2).
Kasten 3.2. Überwachung mit „intelligenten“ Kameras
In Zusammenarbeit mit Thales setzt die französische Kernenergiebehörde (Commissariat à l’énergie atomique et aux énergies alternatives – CEA) Deep Learning ein, um Videos für Sicherheitsanwendungen automatisch zu analysieren und auszuwerten. Ein Modul zur Erkennung von Gewaltakten erkennt z. B. automatisch Schlägereien oder tätliche Angriffe, die von Überwachungskameras aufgenommen wurden, und alarmiert die Betreiber in Echtzeit. Ein weiteres Modul hilft, die Täter im Kameranetzwerk zu lokalisieren. Diese Anwendungen werden derzeit von den französischen öffentlichen Verkehrsbetrieben RATP und SNCF in den Stationen Châtelet-Les-Halles und Gare du Nord getestet, zwei der verkehrsreichsten Bahn- und Metro-Stationen in Paris. Die französische Stadt Toulouse setzt ebenfalls Smart-Kameras ein, um verdächtiges Verhalten und herrenlose Gepäckstücke zu melden. Ähnliche Projekte laufen in Berlin, Rotterdam und Shanghai.
Quelle: Der OECD von CEA Tech und Thales 2018 zur Verfügung gestellte Informationen. Weitere Informationen (auf Französisch) unter: www.gouvernement.fr/sites/default/files/ contenu/piece-jointe/2015/11/projet_voie_videoprotection_ouverte_et_integree_appel_a_ projets.pdf.
Kasten 3.3. Gesichtserkennung als Instrument der Überwachung
Gesichtserkennungstechnologien werden zunehmend von privaten oder öffentlichen Akteuren zur wirksamen Überwachung eingesetzt (Abbildung 3.4). KI verbessert traditionelle Gesichtserkennungssysteme, da sie eine schnellere und genauere Identifizierung ermöglicht, wo herkömmliche Systeme versagen, z. B. bei schlechten Lichtverhältnissen oder wenn die Zielperson durch etwas verdeckt ist. Unternehmen wie FaceFirst kombinieren Gesichtserkennungstools mit KI, um Lösungen zur Diebstahls-, Betrugs- und Gewaltprävention anzubieten. In ihrem Design wurden besondere Überlegungen berücksichtigt, damit sie höchsten Datenschutz- und Sicherheitsstandards gerecht werden, z. B. durch Anti-Profiling-Funktionen zum Schutz vor Diskriminierung, Verschlüsselung von Bilddaten und strikte Zeitvorgaben für die Löschung der Daten. Diese Überwachungsinstrumente werden in verschiedensten Bereichen eingesetzt, vom Einzelhandel (z. B. zur Bekämpfung von Ladendiebstahl) über den Bankensektor (beispielsweise zur Verhinderung von Identitätsbetrug) und den Gesetzesvollzug (z. B. zur Grenzsicherung) bis hin zum Eventmanagement (etwa zur Erkennung von gesperrten Fans) und Casinos (z. B. zur Erkennung wichtiger Personen).
Abbildung 3.4. Veranschaulichung einer Gesichtserkennungssoftware
Quelle: www.facefirst.com.
Aufgrund der Dualität, die KI eigen ist, könnten KI-gestützte Überwachungsinstrumente entgegen den in Kapitel 4 beschriebenen Grundsätzen zu illegalen Zwecken genutzt werden. Legitim ist der Einsatz von KI u. a. im Gesetzesvollzug zur Vereinfachung strafrechtlicher Ermittlungen, zur frühestmöglichen Aufdeckung und Bekämpfung von Straftaten und zur Terrorismusbekämpfung. Gesichtserkennungstechnologien haben sich hier als zielführend erwiesen (Kasten 3.3). Die Auswirkungen von KI gehen in der Überwachung allerdings über die Gesichtserkennung hinaus. Auch bei der Verbesserung von Technologien der gesichtslosen Erkennung spielt KI eine zunehmend wichtige Rolle. Dies sind Technologien, die zur Identifikation alternative Informationen wie Größe, Kleidung, Körperbau, Körperhaltung usw. verwenden. Darüber hinaus hat sich KI in Kombination mit Bildschärfungstechnologien bewährt: Neuronale Netze werden mit großen Bilddatensätzen trainiert, damit sie typische Eigenschaften physischer Elemente wie Haut, Haare oder sogar Mauersteine erkennen. Sie können diese Merkmale dann in neuen Bildern wiedererkennen und das zuvor erworbene Wissen nutzen, um ihnen zusätzliche Details und Texturen hinzuzufügen. So lassen sich Unzulänglichkeiten von Bildern mit schlechter Auflösung beheben und kann die Wirksamkeit von Überwachungssystemen verbessert werden (Medhi, S. M., B. Scholkopf und M. Hirsch, 2017[97]).
KI im öffentlichen Sektor
Künstliche Intelligenz eröffnet in der öffentlichen Verwaltung vielfältige Möglichkeiten. Die Entwicklung von KI-Technologien hat bereits Auswirkungen auf die Arbeit des öffentlichen Sektors und die Ausgestaltung von Politikmaßnahmen für Bürger und Unternehmen. Dies gilt besonders für Bereiche wie Gesundheitsversorgung, Verkehr sowie Sicherheit.15
Verschiedene staatliche Stellen im OECD-Raum experimentieren mit KI, um dem Bedarf der Nutzer öffentlicher Dienstleistungen besser gerecht zu werden. Außerdem möchten sie eine bessere Ressourcennutzung gewährleisten (z. B. um den Zeitaufwand öffentlich Bediensteter für Kundenbetreuung und Verwaltungsaufgaben zu verringern). KI-Instrumente könnten die Effizienz und Qualität vieler Verfahren des öffentlichen Sektors verbessern. Zum Beispiel könnten sie den Bürgern die Möglichkeit bieten, sich bereits im Vorfeld in die Dienstleistungsgestaltung einzubringen und flexibler, effektiver und persönlicher mit dem Staat zu interagieren. Bei richtiger Planung und Implementierung könnten KI-Technologien in den gesamten politischen Entscheidungsprozess eingebunden werden, Reformen im öffentlichen Sektor unterstützen und die Produktivität des öffentlichen Sektors steigern.
Einige Staaten haben bereits KI-Systeme eingesetzt, um Sozialprogramme zu stärken. KI könnte beispielsweise dazu beitragen, die Lagerhaltung in Gesundheits- und Sozialeinrichtungen zu optimieren. Dies würde über Technologien des maschinellen Lernens erfolgen, die Transaktionsdaten analysieren und zunehmend genaue Vorhersagen für die Bedarfs- und Nachschubplanung treffen. Dies wiederum würde die Erstellung von Prognosen und die Politikgestaltung erleichtern. Im Vereinigten Königreich setzen staatliche Stellen KI-Algorithmen auch ein, um Sozialleistungsbetrug aufzudecken (Marr, 2018[98]).
KI-Anwendungen in Verbindung mit erweiterter und virtueller Realität
Unternehmen nutzen KI-Technologie und visuelle Erkennungsfunktionen wie Bildklassifizierung und Objekterkennung, um Hardware und Software für erweiterte und virtuelle Realität (AR und VR) zu entwickeln. Diese neuen Lösungen können u. a. für immersive Erlebnisse, Aus- und Weiterbildung, zur Unterstützung von Menschen mit Behinderungen und für Unterhaltungsangebote genutzt werden. VR und AR haben sich seit dem ersten VR-Headset-Prototyp, den Ivan Sutherland 1968 zur Darstellung von 3D-Bildern entwickelte, in bemerkenswerter Weise weiterentwickelt. Das Headset von Sutherland war noch zu schwer zum Tragen und musste deshalb an der Decke montiert werden (Günger, C. und K. Zengin, 2017[99]). Heute bieten VR-Unternehmen 360-Grad-Video-Streaming-Erlebnisse mit viel leichteren Headsets an. Durch Pokemon Go entdeckte 2016 auch die breite Öffentlichkeit die AR, und die Erwartungen sind nach wie vor hoch. Anwendungen mit integrierter künstlicher Intelligenz sind bereits im Handel erhältlich. IKEA bietet eine mobile App, mit der Kunden mit einer Genauigkeit von bis zu 1 Millimeter sehen können, wie ein Möbelstück aussehen und in einen bestimmten Raum passen würde (Jesus, 2018[100]). Einige Technologieunternehmen entwickeln auch Anwendungen für Menschen mit Sehbehinderung.16
KI für interaktive AR/VR-Anwendungen
Die Weiterentwicklung von AR/VR geht mit dem Einsatz von KI einher, die mehr Interaktivität sowie attraktivere und intuitivere Inhalte ermöglicht. Dank KI-Technologien können AR/VR-Anwendungen Bewegungen der Nutzer, z. B. Augen- und Handbewegungen, erkennen und mit hoher Genauigkeit interpretieren. Dies ermöglicht es, Inhalte entsprechend der Reaktion des Nutzers in Echtzeit anzupassen (Lindell, 2017[101]). Durch die Kombination von KI und VR kann man beispielsweise erkennen, wann ein Nutzer einen bestimmten Bereich betrachtet, und nur dann Inhalte in hoher Auflösung anzeigen. So lässt sich der Bedarf an Systemressourcen reduzieren, Verzögerungen können verkürzt und Bildverluste vermieden werden (Hall, 2017[102]). In Bereichen wie Marktforschung, Trainingssimulationen und Bildung wird eine symbiotische Entwicklung von AR/VR- und KI-Technologien erwartet (Kilpatrick, 2018[103]); (Stanford, 2016[104]).
VR zum Trainieren von KI-Systemen
Einige KI-Systeme benötigen große Mengen an Trainingsdaten. Der Mangel an Daten ist daher noch ein Problem. So müssen beispielsweise KI-Systeme in selbstfahrenden Fahrzeugen für den Umgang mit kritischen Situationen trainiert werden. Allerdings gibt es z. B. kaum reale Daten über Kinder, die auf die Straße laufen. Eine Alternative wäre die Entwicklung einer digitalen Realität. In diesem Fall würde das KI-System in einer von Computern simulierten Umgebung trainiert, die relevante Merkmale der realen Welt wirklichkeitsgetreu nachbildet. Eine solche simulierte Umgebung kann auch verwendet werden, um die Leistung von KI-Systemen zu prüfen (z. B. als „Führerscheinprüfung“ für selbstfahrende Fahrzeuge) (Slusallek, 2018[105]).
Selbstfahrende Fahrzeuge sind jedoch nicht der einzige Anwendungsbereich. Mit dem Household Multimodal Environment (HoME) wurde eine Plattform entwickelt, die eine simulierte Umgebung zum Trainieren von Haushaltsrobotern bietet. HoME verfügt über eine Datenbank mit über 45 000 verschiedenen Grundrissen von Häusern in 3D. Dank dieser Datenbank kann sie eine realistische Umgebung schaffen, in der künstliche Agenten durch Sehen, Hören, Semantik, Physik und Interaktion mit Objekten und anderen Agenten lernen können (Brodeur et al., 2017[106]).
Cloud-basierte VR-Simulationen, in denen KI-Systeme durch Ausprobieren (d. h. durch Versuch und Irrtum) lernen können, wären für das Training ideal, insbesondere für den Umgang mit kritischen Situationen. Durch die kontinuierliche Weiterentwicklung der Cloud-Technologie dürfte es möglich sein, solche Umgebungen zu verwirklichen. So kündigte NVIDIA im Oktober 2017 einen cloud-basierten VR-Simulator an, der physikalische Gesetzmäßigkeiten in realen Umgebungen präzise nachbilden kann. Für die nächsten Jahre wird mit der Entwicklung eines neuen Trainingsgebiets für KI-Systeme gerechnet (Solotko, 2017[107]).
Literaturverzeichnis
[86] Aletras, N. et al. (2016), “Predicting judicial decisions of the European Court of Human Rights: A natural language processing perspective”, PeerJ Computer Science, Vol. 2, S. e93, http://dx.doi.org/10.7717/peerj-cs.93.
[83] Angwin, J. et al. (2016), “Machine bias: There’s software used across the country to predict future criminals. And it’s biased against blacks”, ProPublica, 23. Mai, https://www.propublica.org/article/machine-bias-risk-assessments-in-criminal-sentencing.
[94] Ashby, M. (2017), “The value of CCTV surveillance cameras as an investigative tool: An empirical analysis”, European Journal on Criminal Policy and Research, Vol. 23/3, S. 441-459, http://dx.doi.org/10.1007/s10610-017-9341-6.
[74] Barocas, S. und A. Selbst (2016), “Big data’s disparate impact”, California Law Review, Vol. 104, S. 671-729, http://www.californialawreview.org/wp-content/uploads/2016/06/2Barocas-Selbst.pdf.
[82] Bavitz, C. und K. Hessekiel (2018), “Algorithms and Justice: Examining the Role of the State in the Development and Deployment of Algorithmic Technologies”, Berkman Klein Center for Internet and Society, https://cyber.harvard.edu/story/2018-07/algorithms-and-justice.
[32] Berg, T. et al. (2018), “On the rise of FinTechs – Credit scoring using digital footprints”, Michael J. Brennan Irish Finance Working Paper Series Research Paper, No. 18-12, https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3163781.
[52] Bloom, N. et al. (2017), “Are ideas getting harder to find?”, NBER Working Paper, No. 23782, http://dx.doi.org/10.3386/w23782.
[3] Bösch, P. et al. (2018), “Cost-based analysis of autonomous mobility services”, Transport Policy, Vol. 64, S. 76-91, https://doi.org/10.1016/j.tranpol.2017.09.005.
[15] Bose, A. et al. (2016), “The VEICL Act: Safety and security for modern vehicles”, Willamette Law Review, Vol. 53, S. 137.
[76] Brayne, S., A. Rosenblat und D. Boyd (2015), “Predictive policing, data & civil rights: A new era of policing and justice”, Pennsylvania Law Review, Vol. 163/327, http://www.datacivilrights.org/pubs/2015-1027/Predictive_Policing.pdf.
[106] Brodeur, S. et al. (2017), “HoME: A household multimodal environment”, arXiv:1711.11017, https://arxiv.org/abs/1711.11017.
[50] Brodmerkel, S. (2017), “Dynamic pricing: Retailers using artificial intelligence to predict top price you’ll pay”, ABC News, 27. Juni, http://www.abc.net.au/news/2017-06-27/dynamic-pricing-retailers-using-artificial-intelligence/8638340.
[108] Brundage, M. et al. (2018), The Malicious Use of Artificial Intelligence: Forecasting, Prevention, and Mitigation, Future of Humanity Institute, University of Oxford, Centre for the Study of Existential Risk, University of Cambridge, Centre for a New American Security, Electronic Frontier Foundation and Open AI, https://arxiv.org/ftp/arxiv/papers/1802/1802.07228.pdf.
[79] Burgess, M. (2018), “UK police are using AI to make custodial decisions but it could be discriminating against the poor”, WIRED, 1. März, http://www.wired.co.uk/article/police-ai-uk-durham-hart-checkpoint-algorithm-edit.
[60] Butler, K. et al. (2018), “Machine learning for molecular and materials science”, Nature, Vol. 559/7715, S. 547-555, http://dx.doi.org/10.1038/s41586-018-0337-2.
[63] Canadian Institute for Health Information (2013), “Better information for improved health: A vision for health system use of data in Canada”, in Zusammenarbeit mit Canada Health Infoway, http://www.cihi.ca/cihi-ext-portal/pdf/internet/hsu_vision_report_en.
[6] Carey, N. und P. Lienert (2018), “Honda to invest $2.75 billion in GM’s self-driving car unit” Reuters, 3. Oktober, https://www.reuters.com/article/us-gm-autonomous/honda-buys-in-to-gm-cruise-self-driving-unit-idUSKCN1MD1GW.
[37] CFPB (2017), “CFPB explores impact of alternative data on credit access for consumers who are credit invisible”, Consumer Financial Protection Bureau, https://www.consumerfinance.gov/about-us/newsroom/cfpb-explores-impact-alternative-data-credit-access-consumers-who-are-credit-invisible/.
[44] Cheng, E. (2017), “Just 10% of trading is regular stock picking, JPMorgan estimates”, CNBC, 13. Juni, https://www.cnbc.com/2017/06/13/death-of-the-human-investor-just-10-percent-of-trading-is-regular-stock-picking-jpmorgan-estimates.html.
[41] Chintamaneni, P. (2017), “How banks can use AI to reduce regulatory compliance burdens”, digitally.cognizant blog, 26. Juni, https://digitally.cognizant.com/how-banks-can-use-ai-to-reduce-regulatory-compliance-burdens-codex2710/.
[45] Chow, M. (2017), “AI and machine learning get us one step closer to relevance at scale”, Google, https://www.thinkwithgoogle.com/marketing-resources/ai-personalized-marketing/.
[81] Christin, A., A. Rosenblat und D. Boyd (2015), Courts and Predictive Algorithms, Beitrag zur Konferenz “Data & Civil Rights, A New Era of Policing and Justice” conference, Washington, 27. Oktober, http://www.law.nyu.edu/sites/default/files/upload_documents/Angele%20Christin.pdf.
[96] Civardi, C. (2017), Video Surveillance and Artificial Intelligence: Can A.I. Fill the Growing Gap Between Video Surveillance Usage and Human Resources Availability?, Balzano Informatik, http://dx.doi.org/10.13140/RG.2.2.13330.66248.
[7] CMU (2015), “Uber, Carnegie Mellon announce strategic partnership and creation of advanced technologies center in Pittsburgh”, Carnegie Mellon University News, 2. Februar, https://www.cmu.edu/news/stories/archives/2015/february/uber-partnership.html.
[64] Comfort, S. et al. (2018), “Sorting through the safety data haystack: Using machine learning to identify individual case safety reports in social-digital media”, Drug Safety, Vol. 41/6, S. 579-590, https://www.ncbi.nlm.nih.gov/pubmed/29446035.
[22] Cooke, A. (2017), Digital Earth Australia, Präsentation bei der OECD-Konferenz “AI: Intelligent Machines, Smart Policies” conference, Paris, 26.-27. Oktober, http://www.oecd.org/going-digital/ai-intelligent-machines-smart-policies/conference-agenda/ai-intelligent-machines-smart-policies-cooke.pdf.
[51] De Jesus, A. (2018), “Augmented reality shopping and artificial intelligence – Near-term applications”, Emerj, 18. Dezember, https://www.techemergence.com/augmented-reality-shopping-and-artificial-intelligence/.
[2] Fagnant, D. und K. Kockelman (2015), “Preparing a nation for autonomous vehicles: Opportunities, barriers and policy recommendations”, Transportation Research A: Policy and Practice, Vol. 77, S. 167-181, https://doi.org/10.1016/j.tra.2015.04.003.
[20] FAO (2017), “Can artificial intelligence help improve agricultural productivity?”, e-agriculture 19. Dezember, Ernährungs- und Landwirtschaftsorganisation der Vereinten Nationen, Rom, http://www.fao.org/e-agriculture/news/can-artificial-intelligence-help-improve-agricultural-productivity.
[23] FAO (2009), How to Feed the World in 2050, Ernährungs- und Landwirtschaftsorganisation der Vereinten Nationen, Rom, http://www.fao.org/fileadmin/templates/wsfs/docs/expert_paper/How_to_Feed_the_World_in_2050.pdf.
[66] FDA (2018), “FDA permits marketing of artificial intelligence-based device to detect certain diabetes-related eye problems”, FDA News Release, 11. April, Food and Drug Administration, https://www.fda.gov/NewsEvents/Newsroom/PressAnnouncements/ucm604357.htm.
[75] Ferguson, A. (2014), “Big Data and Predictive Reasonable Suspicion”, SSRN Electronic Journal, http://dx.doi.org/10.2139/ssrn.2394683.
[84] Flores, A., K. Bechtel und C. Lowenkamp (2016), “False positives, false negatives, and false analyses: A rejoinder to ‛Machine bias: There’s software used across the country to predict future criminals. And it’s biased against blacks’”, Federal Probation Journal, Vol. 80/2, https://www.uscourts.gov/sites/default/files/80_2_6_0.pdf.
[17] Fridman, L. (2018), “Tesla autopilot miles”, MIT Human-Centered AI blog, 8. Oktober, https://hcai.mit.edu/tesla-autopilot-miles/.
[18] Fridman, L. et al. (2018), “MIT autonomous vehicle technology study: Large-scale deep learning based analysis of driver behavior and interaction with automation”, arXiv:1711.06976, https://arxiv.org/pdf/1711.06976.pdf.
[31] FSB (2017), Artificial Intelligence and Machine Learning in Financial Services: Market Developments and Financial Stability Implications, Finanzstabilitätsrat, Basel, https://www.fsb.org/wp-content/uploads/P011117.pdf.
[90] Gartner (2017), “Gartner’s worldwide security spending forecast”, Pressemitteilung, 7. Dezember, Gartner, https://www.gartner.com/en/newsroom/press-releases/2017-12-07-gartner-forecasts-worldwide-security-spending-will-reach-96-billion-in-2018.
[36] Gordon, M. und V. Stewart (2017), “CFPB insights on alternative data use on credit scoring” Law 360, 3. Mai, https://www.law360.com/articles/919094/cfpb-insights-on-alternative-data-use-in-credit-scoring.
[99] Günger, C. und K. Zengin (2017), “A Survey on Augmented Reality Applications using Deep Learning”, GE-International Journal of Engineering Research, Associated Asia Research Foundation, https://www.researchgate.net/publication/322332639_A_Survey_On_Augmented_Reality_Applications_Using_Deep_Learning.
[102] Hall, N. (2017), “8 ways AI makes virtual & augmented reality even more real”, Topbots, 13. Mai, https://www.topbots.com/8-ways-ai-enables-realistic-virtual-augmented-reality-vr-ar/.
[5] Higgins, T. und C. Dawson (2018), “Waymo orders up to 20,000 Jaguar SUVs for driverless fleet”, The Wall Street Journal, 27. März, https://www.wsj.com/articles/waymo-orders-up-to-20-000-jaguar-suvs-for-driverless-fleet-1522159944.
[46] Hinds, R. (2018), “How Natural Language Processing is shaping the Future of Communication”, MarTechSeries – Marketing Technology Insights, 5. Februar, https://martechseries.com/mts-insights/guest-authors/how-natural-language-processing-is-shaping-the-future-of-communication/.
[48] Hong, P. (2017), “Using machine learning to boost click-through rate for your ads”, LinkedIn Blog, 27. August, https://www.linkedin.com/pulse/using-machine-learning-boost-click-through-rate-your-ads-tay/.
[73] Horgan, J. (2008), “Against prediction: Profiling, policing, and punishing in an actuarial age – by Bernard E. Harcourt”, Review of Policy Research, Vol. 25/3, S. 281-282, http://dx.doi.org/10.1111/j.1541-1338.2008.00328.x.
[87] Hutson, M. (2017), “Artificial intelligence prevails at predicting Supreme Court decisions”, Science Magazine 2. Mai, http://www.sciencemag.org/news/2017/05/artificial-intelligence-prevails-predicting-supreme-court-decisions.
[61] Hu, X. (ed.) (2017), “Human-in-the-loop Bayesian optimization of wearable device parameters”, PLOS ONE, Vol. 12/9, http://dx.doi.org/10.1371/journal.pone.0184054.
[89] IHS (2017), “Global defence spending to hit post-Cold War high in 2018”, IHS Markit, 18. Dezember, https://ihsmarkit.com/research-analysis/global-defence-spending-to-hit-post-cold-war-high-in-2018.html.
[14] Inners, M. und A. Kun (2017), “Beyond Liability: Legal Issues of Human-Machine Interaction for Automated Vehicles”, Proceedings of the 9th International Conference on Automotive User Interfaces and Interactive Vehicular Applications 24.-27. September, Oldenburg, S. 245‑253, http://dx.doi.org/10.1145/3122986.3123005.
[91] ISACA (2016), The State of Cybersecurity: Implications for 2016, An ISACA and RSA Conference Survey, Cybersecurity Nexus, https://www.isaca.org/cyber/Documents/state-of-cybersecurity_res_eng_0316.pdf.
[12] ITF (2018), “Safer Roads with Automated Vehicles?”, International Transport Forum Policy Papers No. 55, OECD Publishing, Paris, https://doi.org/10.1787/b2881ccb-en.
[30] Jagtiani, J. und C. Lemieux (2019), “The Roles of Alternative Data and Machine Learning in Fintech Lending: Evidence from the LendingClub Consumer Platform”, Working Paper, No. 18-15, Federal Reserve Bank of Philadelphia, http://dx.doi.org/10.21799/frbp.wp.2018.15.
[95] Jenkins, N. (2015), “245 million video surveillance cameras installed globally in 2014”, IHS Markit, Market Insight, 11. Juni, https://technology.ihs.com/532501/245-million-video-surveillance-cameras-installed-globally-in-2014.
[100] Jesus, A. (2018), “Augmented Reality Shopping and Artificial Intelligence – Near-Term Applications”, Emerj, 12. Dezember, https://www.techemergence.com/augmented-reality-shopping-and-artificial-intelligence/.
[77] Joh, E. (2017), “The Undue Influence of Surveillance Technology Companies on Policing”, New York University Law Review, Vol. 91/101, http://dx.doi.org/10.2139/ssrn.2924620.
[24] Jouanjean, M. (2019), “Digital opportunities for trade in the agriculture and food sectors”, OECD Food, Agriculture and Fisheries Papers, No. 122, OECD Publishing, Paris, https://doi.org/10.1787/91c40e07-en.
[80] Kehl, D., P. Guo und S. Kessler (2017), Algorithms in the Criminal Justice System: Assessing the Use of Risk Assessment in Sentencing, Responsive Communities Initiative, Berkman Klein Center for Internet & Society, Harvard Law School, http://nrs.harvard.edu/urn-3:HUL.InstRepos:33746041.
[103] Kilpatrick, S. (2018), “The rising force of deep learning in VR and AR” Logikk, 28. März, https://www.logikk.com/articles/deep-learning-in-vr-and-ar/.
[56] King, R. et al. (2004), “Functional genomic hypothesis generation and experimentation by a robot scientist”, Nature, Vol. 427/6971, S. 247-252, http://dx.doi.org/10.1038/nature02236.
[85] Kleinberg, J. et al. (2017), “Human decisions and machine predictions”, NBER Working Paper, No. 23180, https://www.nber.org/papers/w23180.pdf.
[67] Lee, C. (2017), “Deep learning is effective for classifying normal versus age-related macular degeneration OCT images”, Opthamology Retina, Vol. 1/4, S. 322-327, https://doi.org/10.1016/j.oret.2016.12.009.
[10] Lee, T. (2018), “Fully driverless Waymo taxis are due out this year, alarming critics”, Ars Technica, 1. Oktober, https://arstechnica.com/cars/2018/10/waymo-wont-have-to-prove-its-driverless-taxis-are-safe-before-2018-launch/.
[101] Lindell, T. (2017), “Augmented reality needs AI in order to be effective”, AI Business, 6. November, https://aibusiness.com/holographic-interfaces-augmented-reality/.
[8] Lippert, J. et al. (2018), “Toyota’s vision of autonomous cars is not exactly driverless”, Bloomberg Business Week, 19. September, https://www.bloomberg.com/news/features/2018-09-19/toyota-s-vision-of-autonomous-cars-is-not-exactly-driverless.
[88] Marr, B. (2018), “How AI and machine learning are transforming law firms and the legal sector”, Forbes, 23. Mai, https://www.forbes.com/sites/bernardmarr/2018/05/23/how-ai-and-machine-learning-are-transforming-law-firms-and-the-legal-sector/#7587475832c3.
[98] Marr, B. (2018), “How the UK government uses artificial intelligence to identify welfare and state benefits fraud”, Forbes, 29. Oktober, https://www.forbes.com/sites/bernardmarr/2018/10/29/how-the-uk-government-uses-artificial-intelligence-to-identify-welfare-and-state-benefits-fraud/#f5283c940cb9.
[68] Mar, V. (2018), “Artificial intelligence for melanoma diagnosis: How can we deliver on the promise?”, Annals of Oncology, Vol. 29/8, S. 1625-1628, http://dx.doi.org/10.1093/annonc/mdy193.
[55] Matchar, E. (2017), “AI plant and animal identification helps us all be citizen scientists”, Smithsonian.com, 7. Juni, https://www.smithsonianmag.com/innovation/ai-plant-and-animal-identification-helps-us-all-be-citizen-scientists-180963525/.
[78] Mateescu, A. et al. (2015), “Social Media Surveillance and Law Enforcement” Beitrag zur Konferenz “Data & Civil Rights: A New Era of Criminal Justice and Policing”, http://www.datacivilrights.org/pubs/2015-1027/Social_Media_Surveillance_and_Law_Enforcement.pdf.
[97] Medhi, S. M., B. Scholkopf und M. Hirsch (2017), “EnhanceNet: Single image super-resolution through automated texture synthesis”, arXiv arXiv:1612.07919, https://arxiv.org/abs/1612.07919.
[92] MIT (2018), “Cybersecurity’s insidious new threat: workforce stress”, MIT Technology Review, 7. August, https://www.technologyreview.com/s/611727/cybersecuritys-insidious-new-threat-workforce-stress/.
[34] O’Dwyer, R. (2018), Algorithms are making the same mistakes assessing credit scores that humans did a century ago, Quartz, 14. Mai, https://qz.com/1276781/algorithms-are-making-the-same-mistakes-assessing-credit-scores-that-humans-did-a-century-ago/.
[57] OECD (2018), “Artificial intelligence and machine learning in science”, in OECD Science, Technology and Innovation Outlook 2018: Adapting to Technological and Societal Disruption, OECD Publishing, Paris, http://dx.doi.org/10.1787/sti_in_outlook-2018-10-en.
[53] OECD (2018), OECD Science, Technology and Innovation Outlook 2018: Adapting to Technological and Societal Disruption, OECD Publishing, Paris, https://dx.doi.org/10.1787/sti_in_outlook-2018-en.
[109] OECD (2018), “Personalised Pricing in the Digital Era – Note by the United Kingdom”, Key Paper für das gemeinsame Treffen der OECD-Ausschüsse für Verbraucherschutz und Wettbewerb am 28. November, OECD, Paris, http://www.oecd.org/daf/competition/personalised-pricing-in-the-digital-era.htm.
[1] OECD (2018), Structural Analysis Database (STAN), Rev. 4, Abteilungen 49 bis 53, http://www.oecd.org/industry/ind/stanstructuralanalysisdatabase.htm (Abruf: 31. Januar 2018).
[69] OECD (2017), New Health Technologies: Managing Access, Value and Sustainability, OECD Publishing, Paris, http://dx.doi.org/10.1787/9789264266438-en.
[26] OECD (2017), OECD Digital Economy Outlook 2017, OECD Publishing, Paris, http://dx.doi.org/10.1787/9789264276284-en.
[39] OECD (2017), Technology and Innovation in the Insurance Sector, OECD, Paris, https://www.oecd.org/finance/Technology-and-innovation-in-the-insurance-sector.pdf.
[71] OECD (2016), “Recommendation of the Council on Health Data Governance” OECD, Paris, https://legalinstruments.oecd.org/en/instruments/OECD-LEGAL-0433.
[62] OECD (2015), Data-Driven Innovation: Big Data for Growth and Well-Being, OECD Publishing, Paris, http://dx.doi.org/10.1787/9789264229358-en.
[19] OECD (2014), “Skills and Jobs in the Internet Economy”, OECD Digital Economy Papers, No. 242, OECD Publishing, Paris, https://dx.doi.org/10.1787/5jxvbrjm9bns-en.
[4] Ohnsman, A. (2018), “Waymo Dramatically Expanding Autonomous Taxi fleet, Eyes Sales To Individuals”, Forbes, 31. Mai, https://www.forbes.com/sites/alanohnsman/2018/05/31/waymo-adding-up-to-62000-minivans-to-robot-fleet-may-supply-tech-for-fca-models.
[93] Oliver, J. (2018), “US and China back AI bug-detecting projects”, Financial Times, Cyber Security and Artificial Intelligence, 26. September, https://www.ft.com/content/64fef986-89d0-11e8-affd-da9960227309.
[9] ORAD (2016), “Taxonomy and Definitions for Terms Related to Driving Automation Systems for On-Road Motor Vehicles”, On-Road Automated Driving (ORAD) Committee, SAE International, http://dx.doi.org/10.4271/j3016_201609.
[70] Ornstein, C. und K. Thomas (2018), “Sloan Kettering’s Cozy Deal With Start-Up Ignites a New Uproar”, New York Times, 20. September, https://www.nytimes.com/2018/09/20/health/memorial-sloan-kettering-cancer-paige-ai.html.
[65] Patton, E. (2018), Integrating Artificial Intelligence for Scaling Internet of Things in Health Care, OECD-GCOA-Cornell-Tech Expert Consultation on Growing and Shaping the Internet of Things Wellness and Care Ecosystem, 4.-5. Oktober, New York.
[47] Plummer, L. (2017), “This is how Netflix’s top-secret recommendation system works”, WIRED, 22. August, https://www.wired.co.uk/article/how-do-netflixs-algorithms-work-machine-learning-helps-to-predict-what-viewers-will-like.
[29] Press, G. (2017), “Equifax And SAS Leverage AI And Deep Learning To Improve Consumer Access To Credit”, Forbes, 20. Februar, https://www.forbes.com/sites/gilpress/2017/02/20/equifax-and-sas-leverage-ai-and-deep-learning-to-improve-consumer-access-to-credit/2/#2ea15ddd7f69.
[25] Rakestraw, R. (2017), “Can Artificial Intelligence Help Feed The World?”, Forbes, 6. September, https://www.forbes.com/sites/themixingbowl/2017/09/05/can-artificial-intelligence-help-feed-the-world/#16bb973646db.
[21] Roeland, C. (2017), “EC Perspectives on the Earth Observation” Präsentation bei der OECD-Konferenz “AI: Intelligent Machines, Smart Policies”, Paris, 26.-27. Oktober, http://www.oecd.org/going-digital/ai-intelligent-machines-smart-policies/conference-agenda/ai-intelligent-machines-smart-policies-roeland.pdf.
[35] Rollet, C. (2018), “The odd reality of life under China’s all-seeing credit score system”, WIRED, 5. Juni, https://www.wired.co.uk/article/china-blacklist.
[59] Segler, M., M. Preuss und M. Waller (2018), “Planning chemical syntheses with deep neural networks and symbolic AI”, Nature, Vol. 555, S. 604-610, http://dx.doi.org/10.1038/nature25978.
[28] Simon, M. (2017), “Phone-powered AI spots sick plants with remarkable accuracy”, WIRED, 2. Februar, https://www.wired.com/story/plant-ai/.
[105] Slusallek, P. (2018), Artificial Intelligence and Digital Reality: Do We Need a CERN for AI?, The Forum Network, OECD, Paris, https://www.oecd-forum.org/channels/722-digitalisation/posts/28452-artificial-intelligence-and-digital-reality-do-we-need-a-cern-for-ai.
[11] Smith, B. (2013), “Automated Vehicles Are Probably Legal in the United States”, Texas A&M Law Review, Vol. 1/3, S. 411-521.
[40] Sohangir, S. et al. (2018), “Big data: Deep learning for financial sentiment analysis”, Journal of Big Data, Vol. 5/3, http://dx.doi.org/10.1186/s40537-017-0111-6.
[38] Sokolin, L. und M. Low (2018), Machine Intelligence and Augmented Finance: How Artificial Intelligence Creates $1 Trillion Dollar of Change in the Front, Middle and Back Office, Autonomous Research LLP, https://next.autonomous.com/augmented-finance-machine-intelligence.
[107] Solotko, S. (2017), “Virtual Reality is the Next Training Ground for Artificial Intelligence”, Forbes, 11. Oktober, https://www.forbes.com/sites/tiriasresearch/2017/10/11/virtual-reality-is-the-next-training-ground-for-artificial-intelligence/#6e0c59cc57a5.
[42] Song, H. (2017), “JPMorgan Software Does in Seconds What Took Lawyers 360,000 Hours” Bloomberg, 28. Februar, https://www.bloomberg.com/news/articles/2017-02-28/jpmorgan-marshals-an-army-of-developers-to-automate-high-finance.
[54] Spangler, S. et al. (2014), Automated Hypothesis Generation based on Mining Scientific Literature, ACM Press, New York, http://dx.doi.org/10.1145/2623330.2623667.
[104] Stanford (2016), Artificial Intelligence and Life in 2030, AI100 Standing Committee and Study Panel, Stanford University, https://ai100.stanford.edu/2016-report.
[16] Surakitbanharn, C. et al. (2018), Preliminary Ethical, Legal and Social Implications of Connected and Autonomous Transportation Vehicles (CATV), Purdue University, https://www.purdue.edu/discoverypark/ppri/docs/Literature%20Review_CATV.pdf.
[43] Voegeli, V. (2016), “Credit Suisse, CIA-Funded Palantir to Target Rogue Bankers” Bloomberg, 22. März, https://www.bloomberg.com/news/articles/2016-03-22/credit-suisse-cia-funded-palantir-build-joint-compliance-firm.
[49] Waid, B. (2018), “AI-Enabled Personalization: The New Frontier In Dynamic Pricing”, Forbes, 9. Juli, https://www.forbes.com/sites/forbestechcouncil/2018/07/09/ai-enabled-personalization-the-new-frontier-in-dynamic-pricing/#71e470b86c1b.
[27] Webb, L. (2017), “Machine learning in action” Präsentation bei der OECD-Konferenz “AI: Intelligent Machines, Smart Policies”, Paris, 26.-27. Oktober, http://www.oecd.org/going-digital/ai-intelligent-machines-smart-policies/conference-agenda/ai-intelligent-machines-smart-policies-webb.pdf.
[13] Welsch, D. und E. Behrmann (2018), “Who’s Winning the Self-Driving Car Race?”, Bloomberg, 7. Mai, https://www.bloomberg.com/news/features/2018-05-07/who-s-winning-the-self-driving-car-race.
[58] Williams, K. et al. (2015), “Cheaper faster drug development validated by the repositioning of drugs against neglected tropical diseases”, Journal of The Royal Society Interface, Vol. 12/104, http://dx.doi.org/10.1098/rsif.2014.1289.
[72] Wyllie, D. (2013), “How ‛Big Data’ is helping law enforcement”, PoliceOne.Com, 20. August, https://www.policeone.com/police-products/software/Data-Information-Sharing-Software/articles/6396543-How-Big-Data-is-helping-law-enforcement/.
[33] Zeng, M. (2018), “Alibaba and the future of business”, Harvard Business Review, September-Oktober, https://hbr.org/2018/09/alibaba-and-the-future-of-business.
Anmerkungen
← 1. STAN Industrial Analysis, 2018, Wertschöpfung der Wirtschaftszweige „Verkehr und Lagerei“, ISIC Rev. 4, Abteilungen 49 bis 53, als Anteil an der Gesamtwertschöpfung, ungewichteter OECD-Durchschnitt 2016. Der gewichtete OECD-Durchschnitt betrug 2016 4,3 %.
← 3. Der FICO-Kreditscore wurde 1989 von Fair, Isaac and Company (FICO) eingeführt. Er wird nach wie vor von der Mehrheit der Banken und Kreditgeber verwendet.
← 4. Der OECD-Ausschuss für Verbraucherschutz hat die Definition der personalisierten Preisgestaltung des Office of Fair Trading des Vereinigten Königreichs übernommen: Personalisierte Preisgestaltung kann als eine Form der Preisdiskriminierung definiert werden, bei der Unternehmen durch Beobachtungen gewonnene, freiwillig bereitgestellte, abgeleitete oder gesammelte Informationen über das Verhalten oder die Merkmale einzelner Personen verwenden, um für verschiedene Verbraucher (bzw. Verbrauchergruppen) unterschiedliche Preise festzulegen, und zwar auf der Basis dessen, was sie ihrer Ansicht nach zu zahlen bereit sind (OECD, 2018[109]). Wenn sie von Verkäufern genutzt wird, kann die personalisierte Preisgestaltung dazu führen, dass einige Verbraucher für eine bestimmte Ware oder Dienstleistung weniger, andere hingegen mehr bezahlen, als sie gezahlt hätten, wenn allen Kunden der gleiche Preis angeboten worden wäre.
← 5. Dieser Abschnitt stützt sich auf die Arbeit des OECD-Ausschusses für Wissenschafts- und Technologiepolitik und insbesondere auf Kapitel 3 „Artificial Intelligence and Machine Learning in Science“ in OECD (2018[53]). Die Hauptautoren dieses Kapitels waren Professor Stephen Roberts von der Universität Oxford und Professor Ross King von der Universität Manchester.
← 6. Vgl. https://iris.ai/.
← 10. State of Wisconsin v. Loomis, 881 N.W.2d 749 (Wis. 2016).
← 11. Loomis v. Wisconsin, 137 S.Ct. 2290 (2017).
← 12. Trotz der anerkannten Bedeutung öffentlicher Ausgaben für KI-Technologien zu Verteidigungszwecken wird dieser Bereich hier nicht behandelt.
← 13. Sofern nicht anders angegeben, bezieht sich „digitale Sicherheit“ in dieser Publikation auf das Management wirtschaftlicher und sozialer Risiken, die sich aus Verletzungen der Verfügbarkeit, Integrität und Vertraulichkeit von Informations- und Kommunikationstechnologien und Daten ergeben.
← 14. Ein Phishing-Angriff ist ein betrügerischer Versuch, durch elektronische Nachrichten sensible Informationen abzufangen. Die Empfänger der Nachrichten werden dabei durch eine scheinbar vertrauenswürdige Fassade getäuscht. Mehr Arbeit erfordert Spear-Phishing, das auf bestimmte Personen oder Organisationen als Zielgruppe zugeschnitten ist. Dabei werden sensible Informationen wie Name, Geschlecht, Zugehörigkeit usw. gesammelt und verwendet (Brundage et al., 2018[108]). Spear-Phishing ist der häufigste Infektionsvektor: 2017 begannen 71 % der Cyberangriffe mit Spear-Phishing-E-Mails.
← 15. Die E-Leaders-Initiative des OECD-Ausschusses für öffentliche Governance bestätigt dies. Ihre Arbeitsgruppe zu neuen Technologien, die aus Vertretern aus 16 Ländern besteht, befasst sich hauptsächlich mit den Themen KI und Blockchain.
← 16. BlindTool (https://play.google.com/store/apps/details?id=the.blindtool&hl=en) und Seeing AI (https://www.microsoft.com/en-us/seeing-ai) sind Beispiele für solche Anwendungen.