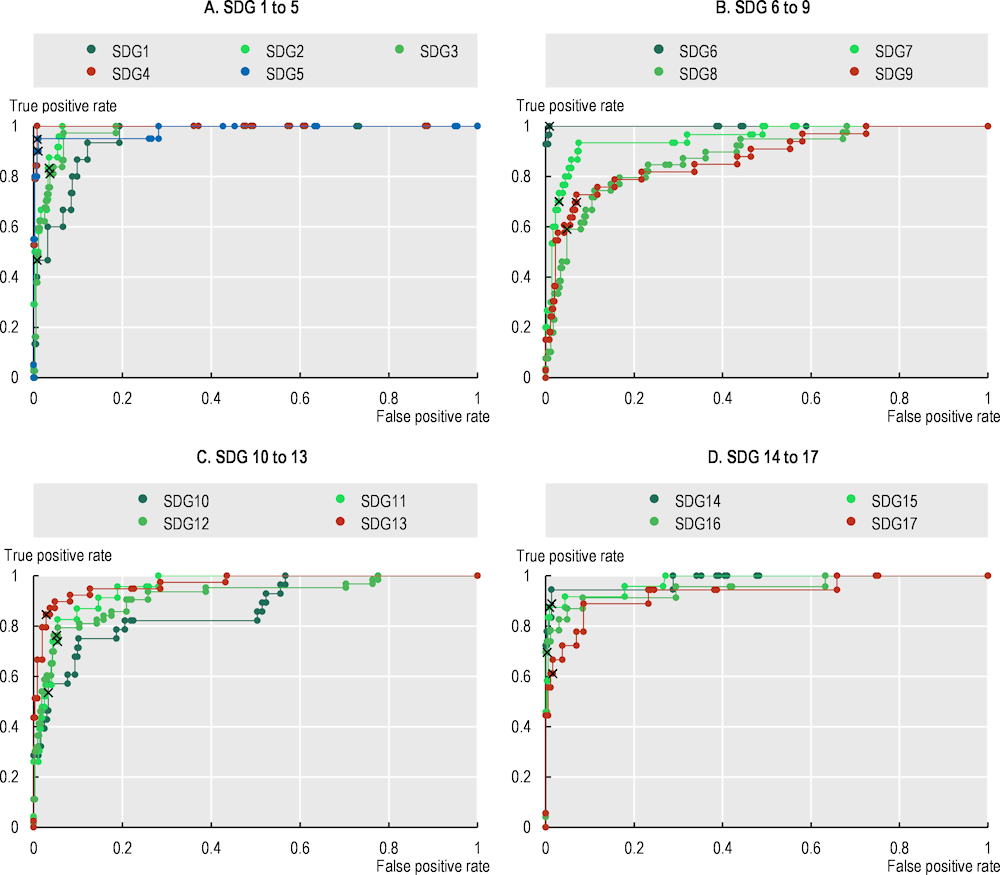
Several parameters govern the estimation of the boosted tree algorithm. The most important is beta, which parametrises the relative importance in the estimation process of type I errors (false negative) compared to type II errors (false positive).
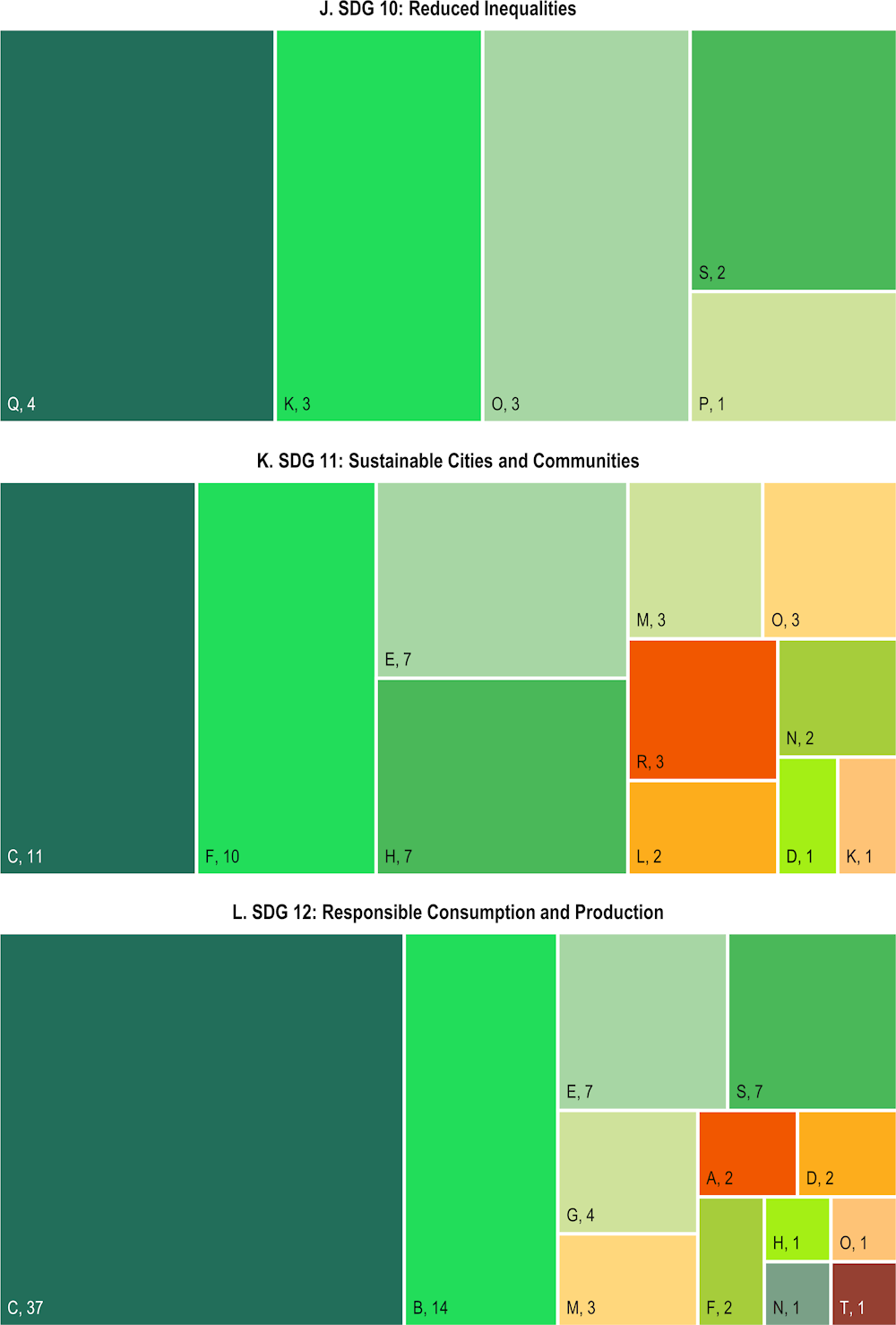
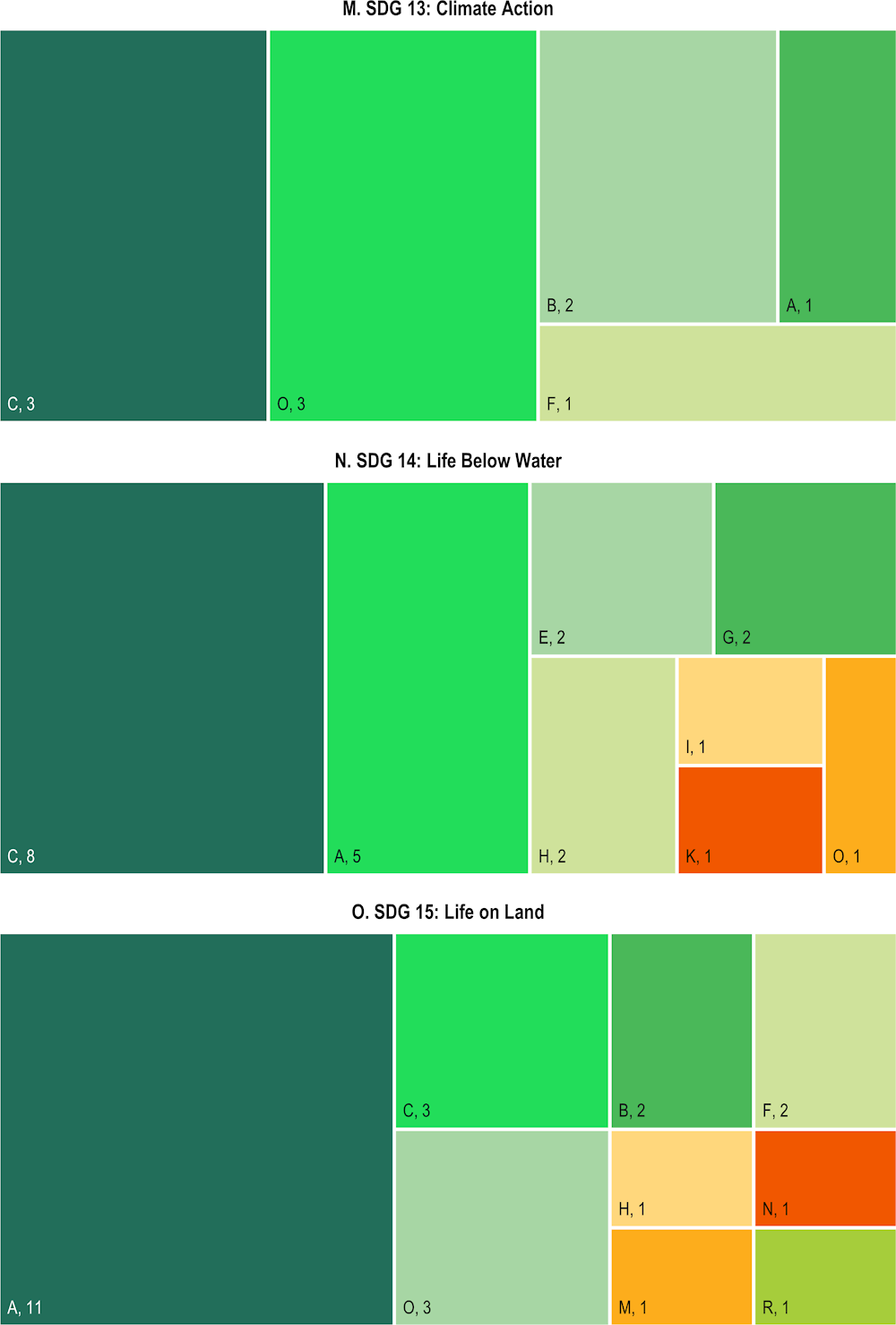
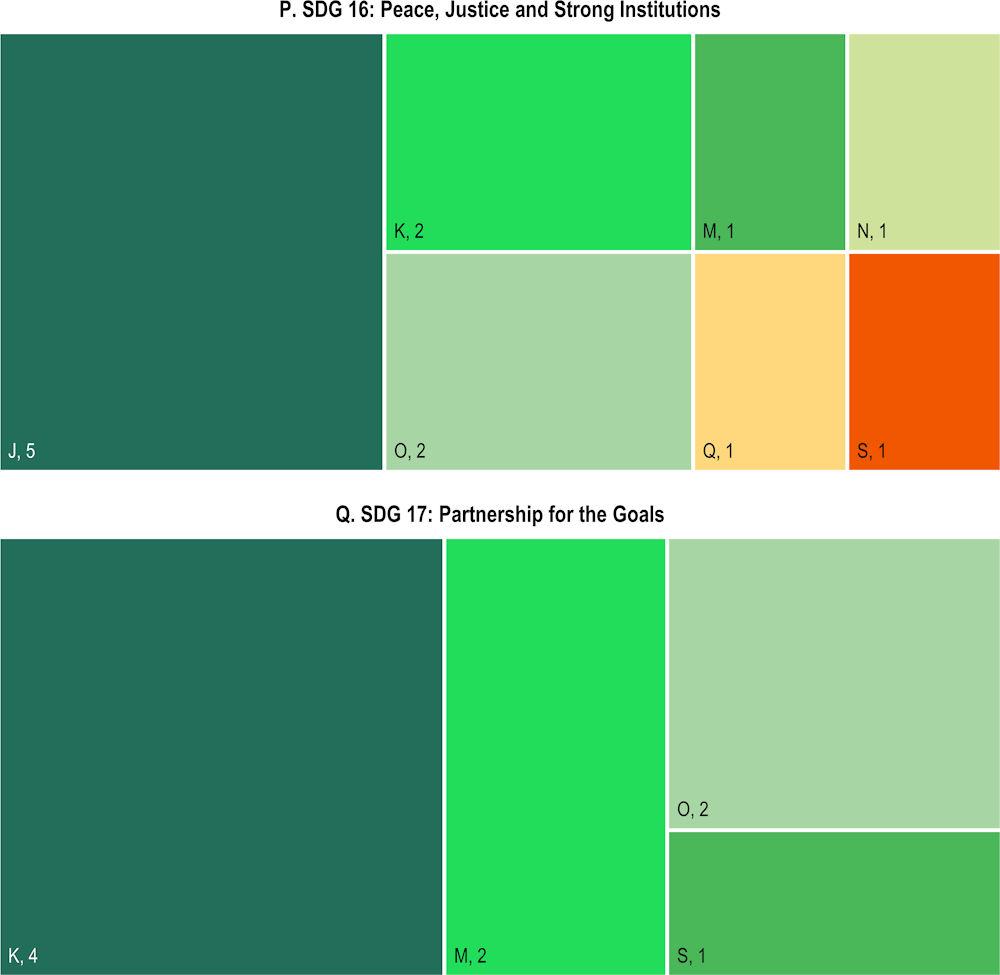
Almost 80% of the training set is built such that the descriptions of firms’ actions are considered as addressing only one Sustainable Development Goal (SDG), whereas in practice some of the SDGs are highly collinear (Pradhan et al., 2017[1]). As a result, the algorithm tends to be too conservative, and likely to generate too many zeros. To offset this bias, a higher weight is assigned to type I errors (i.e. the loss incurred with a false negative is considered a higher cost compared to the loss incurred with a false positive).
Choosing a value for beta boils down to picking a point on the receiver operating characteristic (ROC) curve. With a beta equal to 1, total accuracy is maximised, but moving slightly to the right of the ROC curve is more appropriate for the problem at hand – reducing false negative – while having a minimal impact on false positives. The final beta value corresponds to 1.2.1 With a higher beta, the result would shift to the right in the curve, and to the left for lower values of beta (Figure B.1).