Accurate policy assessment requires rigorous analytical techniques. Employment and Social Development Canada (ESDC) uses an observational study, relying on a rich set of administrative data to compare participants in active labour market policies and non-participants. ESDC extends this analysis further to conduct cost-benefit assessment which allows programmes with different underlying costs to be compared against one another and to look at value‑for-money. ESDC delivers all of this analysis using a well-resourced internal evaluation function, meaning it retains flexibility in its delivery and has continued expertise in the methodology and data used. This is supplemented with external expert peer reviews, which provides guidance on the methods used and the outputs produced.
Assessing Canada’s System of Impact Evaluation of Active Labour Market Policies

4. Assessing the impact: methodologies, evaluation and cost benefit analysis
Abstract
4.1. Introduction
The problem at the heart of any policy evaluation is to accurately calculate the impact of the policy on an individual’s outcomes. Attributing observed changes to the policy requires isolating the particular contribution of the intervention and ensuring that causality runs from the intervention to the outcome (Leeuw and Vaessen, 2009[1]). For an individual that participates in a programme, what would have happened to them had they not participated is never observed. The construction of this “counterfactual” is crucial to being able to estimate the programme’s effect. It relies on estimation of the programme impact, absent any differences that may occur from the comparison of individuals that would otherwise experience different outcomes. Employment and Social Development Canada (ESDC) approach these issues in a methodical and rigorous manner, employing robust analytical techniques to construct groups of non-participants to use as a counterfactual and identify the impact of active labour market policies (ALMPs). Crucially, they also extend this analysis to incorporate programme costs and analyse value for money, which is essential to properly compare policies to one another.
4.2. Types of evaluation design
There is a considerable literature on the various empirical techniques that can be employed to address “selection bias” (see DiNardo and Lee (2011[2]) for a discussion), that individuals participating in a particular programme might be materially different to those that do not. A simple taxonomy is utilised below that provides insight into the different strategies that an evaluator can employ to recover the causal effect of a programme (OECD, 2020[3]). This serves as a useful framework to contextualise how ESDC conducts its counterfactual impact CIE and what the alternatives to them are. It is split by (i) whether the evaluator can control participation in the intervention (experimental vs. observational studies) and (ii) within each of these two categories, the specific research design (or “methods”).
Observational studies can be classified into two types of research design – with the key difference between them being whether the respective method assumes selection only on observable characteristics or also on unobservable characteristics (Table 4.1). Observable characteristics are the known attributes of an individual (for example, age, gender, place of residence), whereas unobservable characteristics refer to everything else that may influence actions (for example, motivation or ability) but for which no data are available. The research designs differ in their approach to constructing a credible comparison group (DiNardo and Lee, 2011[2]; Heckman, Lalonde and Smith, 1999[4]; Kluve and Stöterau, 2014[5]; Wooldridge, 2009[6]). Data needs differ significantly on the type of analytical method chosen. Methods assuming selection on observables require rich contextual data to compare alike people. Observable characteristics in ESDC’s analysis include all of those listed in Chapter 3, Table 3.2. Methods assuming selection on unobservables as well do not require such rich data, but instead rely on a different construction of the counterfactual group using assumptions that mean comparisons can be made as if they were random.
Countries use a mix of identification strategies to evaluate policy. In the data included in the Card, Kluve and Weber (2018[7]) meta‑analysis, of the 174 studies included from OECD countries, 104 (60%) used selection on observables, 40 (23%) used exogenous variation (selection on unobservables and observables) and 30 (17%) used random assignment.1 The precise mixture used in a particular country will be the result of technical, practical, ethical and political decisions on the feasibility of the different methods used, but the significant minority of countries that undertook randomised studies comprise is notable.
Table 4.1. Types of impact evaluation designs
Source: OECD (2020[3]), “Impact Evaluations Framework for the Spanish Ministry of Labour and Social Economy and Ministry of Inclusion, Social Security and Migrations”, http://t4.oecd.org/els/emp/Impact_Evaluations_Framework.pdf, adapted based on Kluve and Stöterau (2014[5]), “A Systematic Framework for Measuring Employment Impacts of Development Co‑operation Interventions”, https://energypedia.info/images/5/54/A_Systematic_Framework_for_Measuring_Employment_Impacts_of_Development_Cooperation_Interventions.pdf.
Some countries (for example Canada and Finland) currently employ only observational studies to derive estimates of programme impacts. This allows them to deliver policy without having to devote extra resources to planning evaluation and trial design, but means that they have to make stronger assumptions about their analysis to have confidence in the estimates produced. Many countries (for example France, Germany, Korea and the United Kingdom) use some mix of randomised studies and observational studies to evaluate different policies. Countries such as Denmark and Switzerland, that have localised delivery of ALMPs similar to that in Canada, work with their localities to employ randomised studies and generate evidence on policy effectiveness. The extent to which a country uses one or the other depends on the factors mentioned above and the specific research questions to hand. The benefit of using observational studies of programmes that have already been implemented is that is it always possible, subject to the right data being available, to analyse a programme, including during its operation or after its completion.
4.2.1. ESDC uses rigorous methods based on observational studies to conduct impact assessment
ESDC uses an observational methodology to evaluate ALMPs – it looks at individuals who participated in ALMPs and evaluates the impact of the programme on their subsequent outcomes. A combination of statistical matching and difference‑in-difference (DID) analysis is used by ESDC to conduct impact evaluation of the LMDA. Both are examples of observational studies (Table 4.1), but they are used in conjunction with one another. In the third cycle of LMDA evaluation, the broad steps to ESDC’s analytical methodology are:
1. Preparatory matching (using Coarsened Exact Matching, CEM) – this step conducted in the data exploration stage to find a better comparison pool, so that it speeds up both computation times and analytical resource requirements
2. Matching (using Propensity Score Matching) – to construct comparison groups of participants and non-participants
3. Outcome assessment – using difference‑in-difference methodology to estimate final programme impacts
Both of the first two steps are examples of matching, utilising the methodology outlined in Box 4.1, but they are used in sequence by ESDC to expedite analysis. Step 1 was introduced as part of the third cycle of evaluation for two primary purposes; to improve computation times and reduce analytical re‑working in Step 2 (ESDC, 2019[8]).
The properties of CEM are such that it is easy to implement, tractable, and may result in better variable balance relative to matching techniques used in step two (Iacus, King and Porro, 2012[9]). Balance is the degree to which a variable in the participant group has the same distribution of values as that in the non-participant group (this is usually assessed looking at the mean values for the groups- for example, using age, whether they contain individuals with the same average age). The process involves the user specifying levels of “coarseness” of data. In an analysis of age, rather than taking an exact age, specifying categories – for instance 30 and under, and over 30. The “exact” nature of the matching means that any data point without a match is removed from the process. In an example dataset with two individuals, a participant aged 30 and a non-participant aged 31, no match would be possible using the previous thresholds. If the participant was aged 60 however, a match would be made (because both the participant and non-participant are aged 30 or over, the threshold chosen). This exemplifies two features of the process, firstly that the analyst has control over the definition of the categories into which the variables describing participants and non-participants are being classified (their level of “coarseness”), and secondly that the choice of categories has a critical impact on being able to find matches. In addition, as the number of observable variables used increases, it becomes harder to find matching samples with the same unique characteristics. This increases the number of participant cases dropped from the sample.
In step two, propensity score matching (PSM) is then applied to the participants and non-participants left in the sample. Using the observable characteristics for both sets of individuals, the likelihood of participating in the programme is estimated, with the observable characteristics influencing the likelihood of that participation. This score is a probability between 0 and 1, with probabilities closer to 1 meaning an individual is more likely to participate. This probability acts as an “index of similarity” between participants and non-participants. Participants are matched to programme-eligible non-participants on this score. For example, a non-participant with a propensity score of 0.8 is more likely to be matched a participant with a propensity score of 0.7 than they are with a participant with a score of 0.3. It matches non-participants that look like they should have participated but didn’t, to similar participants who look like they should have participated and did (and vice‑versa for the individuals that look like they should not participate). In the example using only age, if being young gave a higher likelihood of participation in a programme, it would match young participants to young non-participants. In this sense, it is intuitive to see how matching starts to “balance” the participant and non-participant group along the observable dimensions that determine participation. When the number of variables increases, this balancing can be difficult to achieve – an iteration of matching can increase the balance of one variable but at the expense of causing the deterioration of balance in another variable. This can leave the analyst in a situation of having to repeatedly “tweak” the analysis in an attempt to improve the balance. This is the situation that ESDC have tried to mitigate by implementing the step one CEM. After this process has been completed, the participant and non-participant groups that are matched to one another should be similar in all the observable characteristics used. Any differences remaining between the outcomes of the individuals should be as the result of the participants having completed the programme. Similar to CEM, it is possible to estimate programme effects using the groups defined by this analysis.
In step three, ESDC proceed to make their final estimation of programme impacts, using a DID methodology. There is no additional need to process on the characteristics of individuals, as this estimation explicitly assumes selection on unobservables (as well as observable characteristics) – all differences between individuals are accounted for. The participant and non-participants groups have already been chosen in the preceding steps. The important assumption made that DID makes is that the differences between participants and non-participants remain fixed over time. It does this by looking at how income changes before and after the programme for participants and non-participants (see Box 4.1). Because PSM can only control for characteristics that are observable, this step provides an extra layer of assurance. For example, if education determines participation in a programme and also influences earnings but is not directly observed, DID can control for its impact whereas PSM would not.
The question might be asked, if DID can control for all differences between individuals, whether observed or unobserved, then what is the rationale for using matching prior to it? Part of this is related to the DID assumption that differences between participants and non-participants are fixed over time. Going back to the example using age, if participants in a programme were younger and non-participants older and if young people tend to “catch up” to their older counterparts’ earnings as they become older, then we might expect to see the pre‑programme difference in earnings between the groups changing over time. This would introduce bias into the DID estimate. Using matching to control for these time‑varying trends can improve the accuracy of the DID estimate.
The combination of techniques helps to strengthen analysis
The use of both matching and DID serves as a strong foundation for impact assessment. The problem for analysis using observational studies is that they rely on the assumption that participants and non-participants are comparable after the analysis has been completed, which is often never fully testable. In the case of those techniques using selection on observables (including matching), it is the assumption that all the data you have information on explain the entire difference between individuals and there is nothing in addition. Whilst utilising pre‑programme outcomes (such as income and benefit receipt) in the propensity score, to ensure participants and non-participants are statistically equivalent, provides a strong argument that groups are comparable it cannot be proven. For DID then is an assumption that differences are stable over time. This stability is only testable in the pre‑participation period, not after participation. By combining matching and DID it helps to address some of the potential shortcomings that having observational data bring to inference, by combining their strong points. Both of these techniques are commonplace in the wider literature on ALMPs and so their use as a methodology for inference is well documented and understood. In this sense, ESDC has set a very good platform on which to base its evaluation.
The use of CEM in the first step is an interesting one that is worth considering further. A recent paper on Lithuania uses a similar methodology when evaluating training subsidies (OECD, 2022[10]). Because the programme is designed for individuals outside of “prime age”, meaning younger and older individuals are selected, programme participants have an unusual age distribution. This created problems when using PSM to compare participants and non-participants. It was not possible to match (or “balance”) the age distributions because of this. By first pre‑processing with CEM, using age as the matching variable, the problems of balancing in PSM were resolved. Canada implements CEM for similar but slightly different reasons – to reduce the pool of non-participants and speed up the computation times (which can be considerable given the large numbers of participants and variables for analysis) and to help expedite the balancing required when using PSM. It does not do the latter for explicit reasons to do with a particular policy rule that causes certain people to participate, but rather to mitigate general analytical complexity that uses a lot of analytical resource. These examples suggest that CEM can offer practical solutions to some of the issues encountered with counterfactual impact analysis using PSM.
Explicit comparison of the separate stages could provide greater insight
ESDC could consider further discussion on the combination of methodologies it employs to add further insight to the analysis. Because it conducts two types of assessment, PSM and DID, there is a possibility to separate the steps in this analysis to add additional explanatory power to it. They already include charts of pre‑programme earnings before and after matching (ESDC, 2019[8]). By further enriching the discussion around these and the implications for the DID analysis, they could provide greater context on how the estimates change between groups, using the methods chosen, and what the reasons underlying any change might be. Large changes between the PSM estimate and the estimate with DID layered on top would suggest the latter is controlling for unobservable characteristics that the former could not. This could then give rise to discussion of whether those unobservable characteristics might plausibly be time‑varying, and how much confidence could be placed on these estimates. There is no simple black-and-white best practice in these assessments, because of the degree of judgement and uncertainty involved, but even having this information for the different programmes that comprise the LMDA may allow for a more involved discussion on the relative effects, and confidence in the underlying estimates. Having more discussion around this, even if only contained with a technical annex, would provide more information on the performance of the estimators and further assurance of the process.
Box 4.1. An illustration of the techniques used by ESDC in their impact evaluation
Figure 4.1. A comparison of random assignment, matching and difference‑in-difference
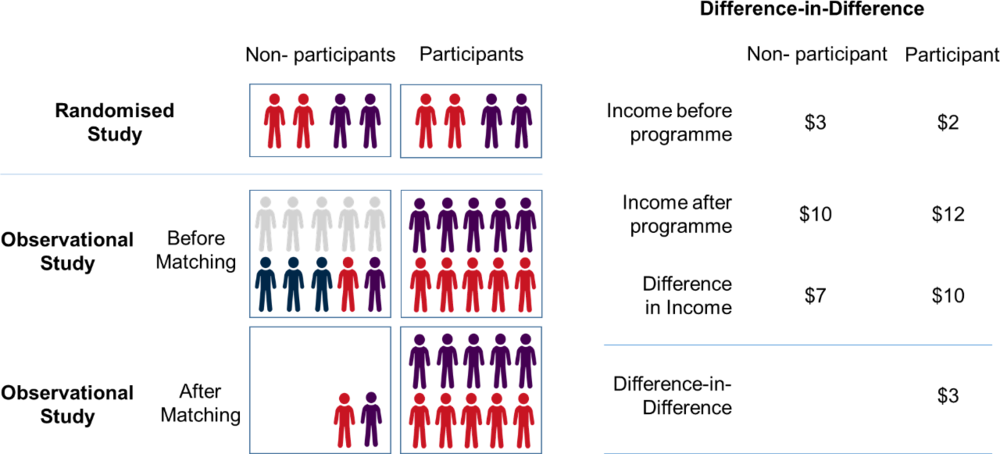
In a randomised study, the fact that the participants are randomly selected ensures that those who do and not do participate are alike (statistically equivalent). There are no underlying reasons driving differences between the two sets of individual. In this instance, programme effects can be estimated by comparing the outcomes of participants against non-participants. No other data are required.
Observational studies occur when a programme is already implemented and random selection is no longer possible. For these programmes, there is a possibility for participants and non-participants to be different because individuals that opt-in to the programme are different to those that do not. For example, a computer training course might attract younger people. If being young is also related to earnings after the programme, then a simple comparison of participants (young people) against non-participants (old people) would lead to an incorrect estimate of the programme’s effect. To see the effects of unobserved characteristics, consider “motivation”. Suppose having higher intrinsic “motivation” led to higher earnings but also increased the likelihood of participation in a training course. If this motivation was unobservable and it was not possible to discern which participants and non-participants were more/less motivated, programmes effect would be overestimated. A conclusion would lead to the training course having beneficial effects on earnings, when actually it just contained a group of participants who would have earnt more even in the absence of the programme. However, if this motivation was also linked to past earnings, and data were available on past earnings, these earnings data could remove some of this phenomenon indirectly (as motivation is highly likely to be reflected in the level of earnings). The degree to which they were able to do that, would depend on the strength of association between motivation and past earnings.
Matching aims to only compare non-participants that are similar to participants. Matching is achieved by comparing participants and programme-eligible non-participants on variables that affect decisions to enter the programme (e.g. age). There are various different methods of matching, but they utilise the same underlying principle and differ only in how they choose the match between people. This can include allowing one individual to match to many, if they are the closest match to all of their pairs, or by removing the individual once they have matched their closest partner. An efficient way to measure the similarity between individuals is to collapse all critical variables affecting programme selection into a single index, such as a propensity-score.
By contrast, difference‑in-difference, does not use observed characteristics of individuals at all, but looks at the change in outcome for participants after the programme, relative to before the programme, compared to the change in outcome over the same period for non-participants. The difference between these two amounts is the impact of the programme. In this way it automatically accounts for all differences for individuals, because it only looks at relative changes between the two groups. This is dependent on those differences between groups remaining stable over time.
Participants are split by their employment insurance eligibility
As discussed in Chapter 3, participants are partitioned according to their status for Employment Insurance. This is done because of concerns about constructing a valid non-participant comparison group for the former Employment Insurance claimants. This is primarily due to having insufficient administrative data to be able to fully identify the pool of eligible non-participants, because non-participants must also be full-time unemployed, anticipating job loss or have been forced to leave a job due to health reasons, which is not information held by ESDC (ESDC, 2019[8]). ESDC are also concerned that motivation plays a big part in their decision to participate in ALMPs. Motivation is not something “observed”, there are no administrative data on it. It may not also be stable over time‑ for example, a life event related to a death or a change in relationship status, could motivate someone to re‑enter the labour market and participate in an ALMP, but would not be observable unless information was obtained on those events. Therefore differences in participants and non-participants may change over time. For these reasons, ESDC decided to change their comparison group, so they compared participants to non-participants of the ALMP in question, but who did participate in Employment Assistance Services (Table 4.2), one of their less intensive ALMPs. Whilst this changes the interpretation of the estimate, compared to the estimate for the current employment insurance claimants, it serves to better mitigate any potential effects of motivation because it compares against people who have already come forward for other services.
A useful lesson to draw from this particular step in ESDC’s analysis, is that is important to think carefully about participant and non-participant groups prior to any impact analysis, to carefully dissect reasons on why they may be different and how these differences may manifest themselves over time. In this way careful consideration can be given to the assumptions underlying any impact assessment and how these may be addressed in the analysis.
Table 4.2. ESDC split the impact analysis into two groups based on how they define their comparison group
Source: ESDC (2019[8]), “Quantitative Methodology Report – Final”.
4.2.2. Experiments could be used to build additional knowledge in a robust and structured manner
In analytical terms, an experimental study is usually seen as “gold standard” because the process of randomisation ensures that no selection effects exist (see Box 4.1). Participation in a programme is statistically independent of outcomes. Participants and non-participants are alike in every observable and non-observable way, therefore estimated programme effects are unbiased by definition. Experiments also allow policy and delivery ideas to be tested on a smaller scale, to ensure they are effective and offer value‑for-money, before they are rolled out further.
This intuitive appeal of randomised studies can often be outweighed by practical issues to their implementation. They involve denial of service to some individuals, which can engender different issues. If there is a political or social imperative to roll policies out immediately, it may not be possible to restrict service in this manner. Localised trials may not also generalise well to the broader population. Furthermore, there can be ethical issues around denial of service to some individuals. These can be compounded in the legal framework of countries, which may explicitly preclude such matters. Due to these issues, relatively few countries, overwhelmingly use randomised studies to evaluate policy. However, they can be useful additions to policy analysis, particularly when they are designed proactively, so as to test areas of interest for policy makers, where existing evidence may be scant.
Denmark and Switzerland offer examples evidence building using randomised trials with locally delivered ALMPs
Denmark is notable for its strategy of employing randomised studies on a systematic and sustained basis to inform policies (see Box 4.2 for more details on Denmark’s approach). Its gradual and systematic building of evidence using RCTs contrasts to the Canadian approach, where incremental impacts are repeated regularly on a cyclical basis. This has meant that the same programmes are evaluated in the same manner, albeit for updated time periods. Relationships between officials at the Danish Agency for Labour Market and Recruitment (STAR) and in municipalities are important, because although the planning for the trials is done centrally, they are conducted at the municipal level and rest on agreement to participate from the municipalities themselves. Funding is attached to these experiments to incentivise participation and cover costs. The nature of volunteering by municipalities does introduce some challenges for STAR, who would ideally like to have a mixture of big and small municipalities, so that the individuals participating are representative of the characteristics of the broader population and of labour market opportunities of Denmark as a whole. This cannot be guaranteed and so the relationships between central and municipal colleagues becomes essential to foster collaboration and encourage participation. Similar good relationships have already been built by ESDC with PTs colleagues over the years of the joint evaluation work on the LMDA, which could provide a fruitful ground for any future work in this area.
Box 4.2. Denmark has an evidence strategy strongly grounded in experiments
The Ministry of Employment’s evidence strategy is based around the continuous development and implementation of policy and legislation. This can be viewed as a cyclical process comprising of policy proposals; agreement on legislation; implementation of legislation; and finally the evaluation of legislation. In every step evidence‑based knowledge plays a crucial role to aid decision-making.
Pursuing an analytical strategy using RCTs has allowed Denmark to systematically address different policy choices and target groups in its ALMPs in a sequential manner. It started by addressing the adequacy of interviews and early interventions on its core client groups, before proceeding to look at more marginalised groups and evaluating differences in delivery strategies. It has now focussed its analytical resources at the hardest to help groups and on using more nuanced methods of ALMP support based around conversation and psychological support.
Proceeding with a rigorous strategy, based on randomised studies where possible, has allowed Denmark to progressively build evidence and enrich its understanding of how ALMPs work in the Danish context. Utilisation of randomised trials means that programmes can be run at a smaller scale and can be focussed on specific policy or delivery objectives.
Table 4.3. RCTS have progressively built knowledge
Source: The Danish Agency for Labour Market and Recruitment (STAR) (2019[11]), https://www.star.dk/en/evidence-based-policy-making/, Rosholm and Svarer (2009[12]), “Kvantitativ evaluering af Hurtig i gang 2 Af”; Krogh Graversen, Damgaard and Rosdahl (2007[13]), “Hurtigt I Gang”; Rosholm and Svarer (2009[14]), “Kvantitativ evaluering af Alle i Gang”; Svarer et al. (2014[15]), “Evaluering af mentorindsats til unge uden uddannel- se og job”; Boll and Hertz (2009[16]), “Aktive Hurtigere tilbarge”; Boll et al. (2013[17]), “Evaluering På rette vej – i job”; Høeberg et al. (2011[18]), “Evaluering Unge‑Godt i gang”.
Switzerland also provides a useful example in the incorporation of RCTs to build evidence, in a largely decentralised structure. This evolution has perhaps proceeded in a more organic fashion, building from localised trials before coalescing at a federal level. Switzerland’s first RCT in the labour market conducted in the Canton of Aargau and looked at avoiding long-term unemployment of older jobseekers (Arni, 2011[19]). The successful delivery of this RCT, which demonstrated the feasibility and use of such experiments in the Swiss context, then paved the way for incorporation of two further trials. The Supervisory Committee for the Compensation Fund of Unemployment Insurance organises its evidence building research programmes into waves, including the possibility of collaboration with external researchers. As part of its third wave of evaluation of ALMPs for the Supervisory Committee two new trials were included, evaluating the role of social networks and expectations in job and counselling (Arni et al., 2013[20]; Arni and Schiprowski, 2015[21]). This work has culminated in a larger-scale programme of work, directly tendered for through the State Secretariat for Economic Affairs, with two trials to assess the quality and intensity of job counselling services provided in Switzerland (SECO, 2021[22]).
By taking an approach that is more localised in nature, using trials in some PTs, Canada can further proactively build its evidence base, focussing the evidence gathering on mutually agreed evidence gaps and enriching what is known about ALMP delivery, particularly trying to understand specific mechanisms of different programmes and how they deliver outcomes for participants.
4.3. Checks on analysis robustness and uncertainty
The discussion in the previous section highlighted some of the uncertainties that are present when using observational studies for policy evaluation. There are a number of procedures and best practices that should be employed in order to check that the data and methods conform to expectations and produce robust and reliable results. ESDC is comprehensive and methodical in its application of these checks to its analysis in order to determine that its results are reliable and it works through these systematically.
4.3.1. Specification checks are used to assess suitability of statistical models
In order to conduct the PSM that ESDC use to define their participant and non-participant groups, the likelihood of an individual participating in the programme has to be estimated (their “propensity score”). This technique relies upon using the individual’s characteristics to determine what impact they have on this likelihood. ESDC conducts specification checks, to evaluate whether the variables chosen to construct this estimate have stability (do not vary significantly when incorporating other variables) and can accurately predict this probability.
For example, if age was the only variable used to construct the propensity score and it gave a 30‑year‑old individual a propensity score of 0.3 of entering the programme, but when the fact that they had no secondary level education was added to the estimation it changed this score to 0.8, the model on age alone would be mis-specified. This is because another variable (education in this case) affected the likelihood of participation but was omitted from the first estimation. This can happen if variables that are important are left out, but it can also happen if too many variables are included in the estimation. In this case the model is said to be “over-fitted”. Instead of picking up true relationships in the data, the model specification too closely mimics the data it is built on. In this instance, estimates can become quite unstable, and adding or removing an additional variable can cause estimates to move dramatically. ESDC also conducts thorough checks of whether different algorithms used to match on the propensity score influence results, using four different algorithms to compare results.
Testing is done to ascertain what variables should be included and how much the results change with different combinations of variables
ESDC uses a statistical technique to determine which variables from their administrative data should be included into the estimation model.2 This step helps to ensure that the variables chosen are important to the estimation of the propensity score. In cycle three of their evaluation work, this step dropped three variables from their original dataset (ESDC, 2021[23]). However, additional testing was implemented by estimating a model including those three variables into the propensity score estimation, which did not change the results markedly. This gives additional reassurance on the model specification. Statistical tests rely in some way on a comparison to thresholds to determine whether or not a test is passed and these thresholds are often chosen by the researcher. Proceeding in this manner and re‑checking the full model, notwithstanding the original test results, is a useful additional practical step that ESDC takes to check analysis and the sensitivity of results.
ESDC compute an estimate for the LMDAs for Canada, but then they also derive separate estimates for each of the 12 PTs. By doing this, they are estimating separate models for each of the PTs. This means the models are specified differently. For example, whilst being younger may make an individual more likely to participate in an ALMP in Canada as a whole, when looking at an individual province or territory, this may no longer be the case. In this way, the individual’s characteristics have the potential to influence the propensity score differently in all the separate regional estimates.
An additional practical step that ESDC might like to consider on specification checking is comparing their results broken down into PTs to the estimate derived for the whole of Canada. By combining all of the separate estimates for PTs into an average, it is possible to recreate the results for Canada. It is not expected that this re‑created Canadian average would be identical to the separate estimate for the whole of Canada, due to previously mentioned point that the variables in the separate regional models can influence the propensity score differently in a regional model. However, there should be a broad concordance between the combination of the estimates for the PTs and the aggregate Canada estimate. Where this is not the case it may be evidence of some kind of mis-specification.
For example, when combining the regional estimates for impact on incidence of employment of Employment Assistance Services, it is difficult to reconcile them with the estimate for Canada. Separate estimates are produced by ESDC for nine of the thirteen PTs. Four PTs do not have separate estimates- Quebec does not take part in the joint evaluation and Northwest Territories, Nunavut and Yukon do not have separate figures reported in the evaluation results. Figure 4.2 shows the average that is needed for these, for the weighted average of all PTs to equal that of the separately estimated figure for Canada. It is negative in sign, in contrast to all of the other individual estimates. This suggests that, unless there is an unusual effect of the programme in those four PTs, there may be some kind of specification error in either the estimate for Canada, or some of the individual PTs. This may warrant further investigation of what is going on for these estimates. By conducting this type of assessment more routinely, ESDC could make a virtue of having the separate PTs estimates and perform a more in-depth assessment of model specification.
Specification checking could also be supplemented with a “test-train” procedure. Here the original dataset is split randomly into two, the first dataset is used to estimate the propensity scores. The model estimated from this is then applied to the second dataset. If the model is able to successfully balance the individual characteristics and produce participants and non-participants that are alike, then it is further evidence that the model is well specified and fits the population more generally, rather than being “over-fitted” to the specific individuals that happen to appear in the first dataset.
Figure 4.2. Individual PTs estimates for EAS incidence of employment impacts imply a significantly negative impact for those PTs without an individual assessment
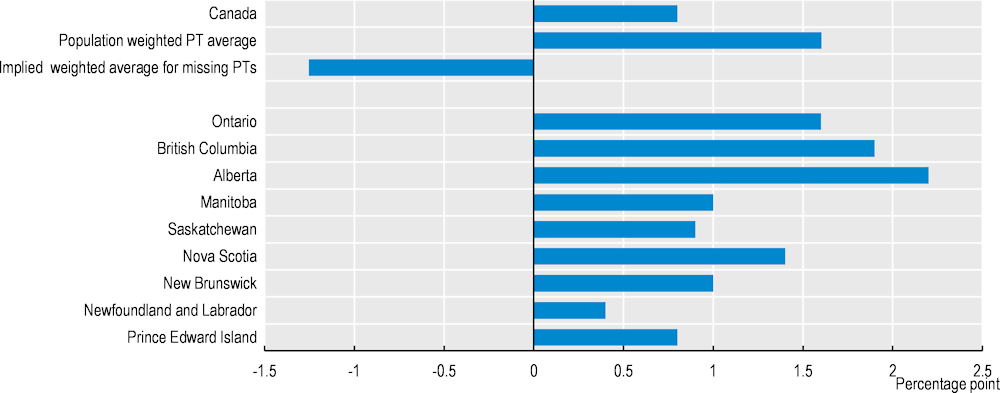
PTs: Provinces and Territories.
Note: Weighted average derived using sample sizes detailed in the individual reports. Random samples of data were used for Canada, Alberta, British Colombia, Manitoba and Ontario- these have been scaled up to population levels. Quebec sample size estimated as Canada minus sum of the individual PTs. “Missing PTs” is the combination of Quebec, Northwest Territories, Nunavut and Yukon.
Source: Individual Employment and Social Development Canada ESDC impact assessment reports on provinces and territories (2017‑2018), available at www.canada.ca.
Individuals without a similar comparator are removed from analysis
Matching also requires that the participants and non-participants have a potential individual that looks sufficiently like them in their propensity to participate in the programme. For example, if there is a participant in the programme with a very strong probability of participation and a propensity score of 0.9 and no similar individual exists in the non-participant group, then it is necessary to remove that individual from the matching process. This is because there is no individual sufficiently alike to them and therefore it is not possible to adequately match an individual that could reliably provide a comparison to what outcome the participant would enjoyed had they not participated. ESDC conduct this assessment via a graphical inspection of the distribution plots, which is a standard technique in the literature (Caliendo and Kopeinig, 2008[24]). This allows to ensure the matching begins with an appropriate set of participant and non-participants.
Different types of matching algorithm are assessed
Once a propensity score has been estimated, there are various different algorithms that may be used to match individuals to one another (and so create the participant and non-participant groups) with this score. Whilst an in-depth technical assessment of these algorithms is beyond the scope of this paper, the general principles of testing are interesting to discuss. ESDC use kernel density matching as the technique for their central impact assessments. However, estimates were also made using inverse probability weighting, nearest neighbour and cross-sectional matching (ESDC, 2021[23]). The results displayed demonstrate that outcome estimates are not sensitive to the choice of matching algorithm that is used. In this case it provides re‑assurance that results are not driven by the choice of the algorithm used to match the data. One point to bring out of these tests is that it may be preferable from a computational point of view to implement the matching by inverse probability weighting, rather than kernel density matching, given that the former is faster to implement because it requires less computation power. Indeed, this is a conclusion that was reached in an earlier assessment of the LMDA analysis (Handouyahia, Haddad and Eaton, 2013[25])
Checks are made on the stability of the relationships between participants and non-participants over time
ESDC also conducts checks to determine whether the DID estimates conform to the assumption that differences between participants and non-participants are stable over time. Analysis of these trends suggests that there is a good stability on the difference between them, after matching has taken place (ESDC, 2021[23]). Participant and non-participant earnings are charted over time, however it is difficult to gauge differences visually on the aggregate annual earnings measure displayed in the ESDC reports (ESDC, 2021[23]). Further charts, which display the difference between the earnings of the participants and non-participants rather than their absolute levels, would be beneficial in this respect. To formalise this further, statistical tests can be conducted, using an event study set-up. Rather than test whether a programme has a significant impact on earnings using the difference in pre‑ and post-programme periods of participants, differences between participants and non-participants are also tested statistically before the participation. The period before the programme is usually broken down into disaggregated periods (the annual data that ESDC use would suggest years for a breakdown in their work). If annual data are used, this would then test whether differences in earnings are significant in each year prior to the programme period. If no statistically significant differences are found on the earnings of participants and non-participants in the period before participation then it provides evidence that there is a stable relationship over time between them. Kauhanen and Virtanen (2021[26]) provide a recent example in a study on adult education policy in Finland (including charts where differences are charted rather than levels).
ESDC conducts methodical and extensive statistical data checks which cover all of the main areas that a robust check of statistical analysis should comprise. There are small improvement and tweaks that ESDC may consider. For example, further investigation into differences at the PTs level analysis may provide additional information, outside of formal statistical testing, on how well specified their models are and would make further use of work they have already conducted for other reasons. These tests are produced in a technical report for the LMDA evaluation (ESDC, 2021[23]), but also turning them into a non-technical passage and incorporating them in the executive summary of non-technical reports may assist a broader audience in understanding some of the strengths and inherent uncertainties of the existing approach.
4.4. Cost-benefit analysis
To assess the value for money of a policy, consideration also needs to be given to the costs of provision and to wider benefits, which may occur indirectly. An ALMP may be successful in helping a person into work, but if the cost of doing so outweighs the extra benefit from that person entering work then it will not be cost-effective to proceed with the policy. Despite the advances in analytical techniques and the number of ALMPs that are now evaluated, detailed cost-benefit analyses are still rare (Card, Kluve and Weber, 2018[7]). Canada is an exemplar in this respect and sets out a clear and comprehensive cost-benefit analysis of its ALMPs that facilitates informed discussion of their relative merits. Explicitly incorporating both the costs and the benefits of participation into an assessment of value means that it has a much better basis to evaluate programmes than viewing the benefits in isolation (as is more routine in impact assessment). It also brings in wider dimensions of government finance, such as tax and wider benefits, than a narrow focus on labour market outcomes.
4.4.1. Data on costs are important to properly contextualise benefits
A comprehensive estimate of all of the costs of provision of a programme, including those incurred indirectly, is required to feed into a thorough cost-benefit assessment. In some cases, savings elsewhere might offset costs of programme provision. For example, a training programme that gets people into work quickly may mean that public employment services also spend less money on a counsellor to help them find a job. Similarly, benefits may be wider than the income gain to the participant. The use of wider social services, such as health care, and the impact on crime might also be considered. There is a secondary link to government finances directly via taxation receipt, as this just represents a transfer from one individual to another, it does not impact upon primary cost-benefit calculations. However, it may be useful to consider for public finance discussions. Consideration of the impact of a programme on government spending, in light of the distortionary impact that ad valorem taxation has on behaviour, should also be taken account of. A programme that causes a net increase to government spending will increase negative distortions to behaviour (for example, government spending that necessitates a higher income tax to pay for it might mean that fewer individuals choose to work, or reduce their hours of work).
ESDC adds costs to its analysis and looks at value for money through a range of lenses
In order to evaluate the cost-benefit of the LMDAs, ESDC begins with its estimates from the counterfactual impact assessment and then adds a number of elements to complete the analysis (Table 4.4). All of the assessment is done at the individual level, comparing the costs of delivering the programme to the individual compared to the benefits that the individual receives as a result. There are three different accounting units that are considered in this framework:
Individual – this looks at all changes that are only relevant to the person participating. Programme costs and social costs of public funds are not relevant to the individual so are not included. The change to employment earnings is a large component of this calculation. Income and sales taxes paid by the individual enter as a negative figure. The receipt of social assistance and employment insurance may enter as a positive or negative depending on whether the individual receives more or less of them as a result.
Government – looks at how changes relate to government finances. For example, programme costs and social costs of public funds enter the calculation negatively. Income and sales taxes received by government are positive. The change to employment earnings does not enter the government calculation, except where it changes the income taxes paid, because that benefit accrues directly to the individual.
Social – accounts for impact of the changes on society. The important thing here is that changes to employment earnings enter the calculation, as they increase or decrease output in the economy. Changes to government taxation receipt and benefit receipt are not entered in the calculation because they represent a transfer from government to the individual, so there is no net gain to society.
Whilst the investment decision for a programme should be based upon the social impact, because this provides the answer on whether a dollar invested provides more or less than that to society, it is useful to consider the individual and government accounting units. Viewing the programme through the lens of an individual provides a better perspective on the decisions that an individual is making when deciding upon participation in a programme (and could be used by public employment services when advertising the benefits of a programme to potential participants). Consideration of the government perspective allows a focus to be given to public financing, that may be useful when considering the political economy on whether or not to invest into a programme (although a first-best decision by a finance ministry should take into account the social returns, there can often by constraints on financing, particularly where a programme might take some time to repay its investment).
In order to calculate the returns to those different groups, ESDC brings in a number of additional estimates to its impact analysis. On the benefit side, changes in employment income, social assistance and employment insurance receipt are taken directly from the counterfactual impact assessment. An estimate for how this affects payment of sales tax is then derived from looking at the changes in employment income and calculating how much of this will be spent, at the prevailing average provincial and federal sales tax rates.
On the cost side, estimates are constructed using administrative accounting data on aggregate delivery costs. These are split into operational and administrative costs. Operational costs take the total direct administrative expenditure of providing a programme divided by the number of those programmes delivered, to estimate the cost of delivering that programme to an individual. Administrative costs comprise the ancillary spending and overheads necessary to administer the programme (for example ESDC staff that co‑ordinate and manage the ALMPs). They are not available per programme and so the estimate is made by taking the total and splitting this into programme type based on that programme’s relative share of the operational costs (for example, if operational costs of Targeted Wage Subsidies were 30% of total spending on operational costs across all programmes, it would also constitute 30% of total administrative costs. An estimate of the social cost of public funds is then calculated (this enters Table 4.4 as a cost only because the ALMP involves net government spending. If a programme directly saved government money then it would be a benefit to the programme). Following expert advice, the amount of this cost is estimated as 20% of the net change to government spending (the cost of providing the programme and the net change to tax receipts). This is comparable to estimates made in other government assessments of its potential role in impact assessment (Fujiwara (2010[27]), Australian Department of Finance and Administration (2006[28]))
Table 4.4. ESDC consider a number of costs and benefits in addition to the counterfactual impact evaluation
Source: ESDC (2016[29]), “Cost-Benefit Analysis of Employment Benefits and Support Measures”.
Costs and benefits are then brought to a common base for comparison
Once costs and benefits have been estimated, the last stage is to account for the fact that some costs and benefits fall into different years. This is known as discounting and cost-benefit estimates that have been discounted are in a “net present value”. This means all the figures can be compared as if they occurred in the current time period. It reduces the weight of values in later years relative to earlier ones. Costs and benefits in the central estimate are added up over six years following the programme, and for two years during programme participation. The rate at which this is set for ESDC is 5% per annum. This means a USD 100 benefit (or cost) earned in one year’s time is only valued at USD 95.2 (100/1.05). If this USD 100 had been earned in two years’ time, it would be worth USD 90.7 (100/(1.05*10.5)). ESDC set this rate to account for two factors: inflation and interest foregone on government investment. Foregone government investment accounts for the fact that the government could have instead invested the money elsewhere and earnt money on this investment. Discounting is important to ensure that costs and benefits that occur over time are compared on the same basis.
4.4.2. Some known costs and benefits are not yet included in the assessment
There are wider costs and benefits that are not considered in the ESDC cost-benefit analysis but would be beneficial to consider. These are explicitly referenced in the ESDC report (ESDC, 2016[29]):
Intangible benefits to mental health and physical well-being
Effects on crime
Multiplier effects – where increased employment and spending in the economy generates further increases in employment and spending
Displacement effects – where participants take jobs away from non-participants
Incorporation of health data, to estimate what impact ALMPs have on the health-related expenditure of individuals, will help to better contextualise all of the gains from the LMDA. Empirical research has shown that higher income can lead to better health outcomes (Benzeval and Judge, 2001[30]). Raising employment therefore has the potential to reduce health care spending. Employment policies that specifically target lower-income individuals can therefore play a vital role in supporting health care systems. ESDC are currently working on the incorporation of estimates of the impact of ALMPs on health outcomes to the analysis. This will provide a better understanding of the additional secondary benefits that ALMPs can have and a richer understanding on the impacts of ALMPs on individuals.
Similarly, adding the effects of ALMPs on subsequent crime rates, with their associated costs to society, would complement the existing analysis. Grogger (1998[31]) provides an estimate from the United States that looks at changes to propensity to commit crime due to changes in income. Incorporating this into an estimate on the reductions to crime via the increased income from ALMPs would then be straightforward. In combination with estimates for the cost of crime, this could then be incorporating into the cost-benefit assessment.
Providing evidence on displacement effects is difficult to achieve using ESDC’s current evaluation strategy. It relies on estimating the impact on the employment that participants of a programme have on the employment prospects of non-participants. Indeed non-participants are the very individuals that are used to estimate the overall programme effects. If displacement was occurring, it would cause an overestimate of the beneficial effects of the programme, because the non-participant employment rate (or level of earnings) would be lower, directly causing the estimate of the programme to improve. This may be more likely to affect Employment Assistance Services because transitions into work are quicker and greater in volume than other programmes (relative to say a training programme, for which the participation period can be a number of months), meaning it has more potential to affect the job-finding of non-participants. A study in Sweden is an example of where a carefully planned randomised trial may help to provide evidence (Cheung et al., 2019[32]). The study took place across 72 randomly selected public employment service offices in Sweden. Of these 72, 36 were randomly selected to the treatment programme. Within each office, jobseekers were randomly assigned to the programme. This two stage randomisation of offices and jobseekers, was implemented so that displacement effects could be estimated. Estimates of displacement were made by comparing non-participants in offices with the programme to non-participants in offices without the programme. It showed that such displacement was present in job counselling services, suggesting it is an area that merits further attention.
Distributional weighting is an area which is not covered in ESDC’s existing cost-benefit analysis, but which might be worth considering as an addition to it. Distributional weighting increases or decreases the value of a programme to an individual based on how rich or poor that individual is. It is based on the idea that it is desirable to reflect the differences in marginal benefit of consumption between rich and poor individuals, particularly pertinent for the LMDA as they are delivered to individuals lower down the income distribution. This uses the concept of diminishing marginal returns to consumption, so that a dollar spent by a poor individual is “worth” more to them than a dollar spent by a rich person is to them. The United Kingdom advises that weighting is considered where redistribution is an explicit policy aim, such as in welfare payments (HM Treasury, 2020[33]). The Australian guidance is slightly more equivocal and only advocates any sort of weighting approach where an unambiguous policy objective is identified to assist a specific group, to avoid subjective biases in weighting (Department of Finance and Administration, 2006[28]). However, social policy would fall under the scope of such a requirement. By presenting distributional weighting alongside the standard CBA assessments, it would allow ESDC to better contextualise the policies and secure ALMPs budgets.
4.4.3. Sensitivity analysis is conducted to demonstrate the uncertainty of estimates
In addition to its core estimates, ESDC provides sensitivity analysis on three variables used in the construct of the cost-benefit analysis. It alters each of the following variables one by one (and in combination with one another) to analyse the impact they have on the cost-benefit estimate. The three variables it alters are:
Discount rate – varying it to 3% and 7%.
Marginal social cost of public funds – varying it to 0% and 50%.
Length of impacts considered – extrapolating impacts in year six out to 15 and 25 years
The inclusion of sensitivity analysis is welcome and should be commended, as it helps to display the uncertainty around the estimates, which depend on several different assumptions. It conducts combinations of these three adjustments (so that there are 27 cost-benefit estimates, including the original central estimate). These sensitivity variations have been conducted using expert judgements.
Some additions to the sensitivity analysis would aid discussion of its likely range and central estimate
An important addition to the sensitivity analysis would be to allow variation to the estimated impacts on earnings, social assistance and employment insurance (aside from extending the length for which they are accounted for). The estimates arising from the quantitative DID analysis will have been accompanied with “standard errors”, which provide information on how much uncertainty there is around each central estimates. This provides a natural candidate for which to use in sensitivity, to increase and decrease the central estimates by in the sensitivity analysis.
It is possible to extend the sensitivity testing of the cost-benefit analysis further using statistical Monte Carlo simulations. This helps to give more insight into how combinations of variable variations may group together and gives more information on where sensitivity estimates are grouped (for example, whether they are spread equally over a range, whether more of them are under the central estimate or above it). In this work possible values for variables (“distributions”) have to be chosen for each of the variable that is being varied (New Zealand Treasury, 2015[34]). At their simplest, they could take the form of a triangular distribution (where a variable can take three values, a low, medium and high), not dissimilar to the variations already conducted by ESDC. For variables for which there are more empirical data available, more complex distributions could be chosen (for example, on the discount rate by looking at previous inflation and government bond time series to estimate an appropriate distribution). Monte Carlo works by then repeatedly picking a value for each of the variables, based on their underlying distributions, and then computing the resulting cost-benefit. By repeating this action thousands of time, the process itself produces a distribution of cost-benefit estimates.
Overall, the work that Canada conducts on cost-benefit analysis is comprehensive and rigorous. It permits a much more detailed evaluation of the relative pros and cons of its ALMPs. It also demonstrates that with a clear framework and rationale for cost-benefit analysis, a relatively comprehensive assessment can be achieved without too many additional steps over and above a more narrow impact assessment. At a minimum, incorporating the costs of programme provision and calculating the extra taxes and benefits paid by individuals, all in their net present value, allows a good basic cost-benefit analysis to be conducted, which permits a much more rounded discussion of programme merits than in their absence. The additional in-direct impacts on health, crime and distortions relating to government financing can then supplement this further.
4.5. Analytical delivery: In-house or out-sourced
The choice over whether to deliver ALMP evaluations in-house or via external contractors is a multi-faceted one and countries have different approaches, many opting for some combination of both. ESDC has invested in an analytical capability, housed within its Evaluation Directorate, to conduct all of the required ALMP evaluations internally, transforming a delivery system that previously relied upon external contractors to deliver. This section discusses some of the choices that are relevant to these strategies, offering insight into the advantages and disadvantages of different strategies and provides examples from the Canadian setting.
Once a decision has been made to evaluate ALMPs in a country, three broad strategies exist:
In-house – e.g. Australia, Canada;
Out-sourced – e.g. Denmark, Finland;
A combination of in-house and outsourced – e.g. Estonia, France, Germany, New Zealand, Sweden, Switzerland, United Kingdom.
Conducting evaluations in-house or by contracting-out depends largely on decisions around the required expertise to conduct analysis, the possibility to make data available to external partners, the frequency of such studies, the capacity to manage external research projects and the capacity to manage the narrative from the analysis.
Those ministries that have smaller, or no, analytical functions may be better placed to contract-out research, rather than having a dedicated evaluation function. For example, The Ministry of Economic Affairs and Employment in Finland made the decision to rationalise its previous evaluation function as part of a drive to focus resource on day-to-day policy delivery and retains only a small team of analysts to serve ministerial business. It instead chooses to out-source its delivery of evaluation. This contrasts to the evaluation directorate in ESDC which shifted to a strategy of conducting this type of evaluation work in-house, so that ESDC can more easily ring-fence specialist resource for evaluation.
Some countries navigate these issues using a “quasi‑in-house” research institute‑ such as the Institute for Employment Research in Germany or the Institute for Evaluation of Labour Market and Education Policy in Sweden. These institutes are external to the employment ministry and allow research expertise to coalesce around specific mandates for analysis. This separation is useful to ensure resources are devoted to analytical assessment of public policy, ring-fencing them from divergence within ministries to other policy development priorities. They can also serve as a data warehousing and access body that can facilitate the wider sharing of their data with external researchers. This happens at both of the institutes mentioned.
Legislative requirements to evaluate, as happens in Germany and Sweden, as well as in Canada, are useful to ensure open and transparent assessment of policy (see OECD (2020[35]) for a discussion of developments). It avoids the political “cherry picking” of policy analysis- only choosing to evaluate policies that are convenient to a particular political narrative at the time. Those countries without legislative mandates to evaluate policy and who do not open data up to external researchers risk ad hoc and piecemeal policy assessment. Even countries that do offer open data access, without legislative evaluation requirements, risk their evaluations following the same path, if data and analysis is not suitably accessible and demanded enough by the wider research community. For example, whilst Finland offers researchers access to high-quality microeconomic data on its ALMPs, that in principle mean that they could be assessed in observational studies, it still lacks evidence on some of its programmes. Concerted efforts from policy makers, external pressure groups or research communities to ensure assessments are prioritised, can help countries to ensure that policy evaluation does not remain incomplete.
4.5.1. Impact evaluation in ESDC is carried out in-house
ESDC moved capacity to conduct impact evaluations in-house after the first iteration of summative evaluations of the LMDA were completed. The driving force behind this move was a desire to increase responsiveness of analysis to policy and utilise administrative data to increase precision of estimates and to reduce costs. Whilst the use of contractors to analyse administrative data could have been facilitated, there are additional benefits for internal analysts to conduct such work. It is easier for them to collaborate with internal colleagues who have knowledge on the existing data that is housed within the department. It also offers wider spill-over effects within the organisation, particularly when staff move into different but related analytical roles- they retain their knowledge of the data and its structure and can bring this to bear in new analytical projects. Over the years, ESDC has built up a store of analytical expertise centred on knowledge transfer via individuals and knowledge retention via extensive documentation of data, code and techniques.
Expertise was developed primarily through two distinct teams. One with a remit to create analytical datasets to use for evaluation and conduct rigorous econometric techniques to these data to estimate causal impacts of programmes offered and another to manage the process of engagement with PTs and qualitative data collection (see Chapter 2, Section 2.4.2 for more detail). This distinction allowed resources to specialise to deliver policy analysis at a faster pace and with greater precision. With the support of ESDC Chief Data Office, the data team focused on the inclusion of the CRA data into an integrated evaluation dataset and proceed with the quantitative work and the other team worked on “regional” issues, liaising with PTs to ensure that analytical requirements for data were well understood, that the underlying data transfers from PTs reliably captured those requirements and conducting the required qualitative work. The relationships built up with PTs by the data team made them the natural home to manage these ESDC-PTs interactions. As resource increased over time, further specialisation was made possible, including separation of resource to manage data processing; to advise on methodology and quality assurance; and to conduct analysis (see Chapter 2 for more details).
Reducing costs of delivery was one of the drivers for the change behind the shift to in-house administrative data led evaluations. Costs of external contractors were reduced from around CAD 1 million per annum to CAD 70 000 (Gingras et al., 2017[36]). However, it is unclear the extent to which in-house delivery of the quantitative evaluation work alone was responsible for this. The major methodological change of using integrated administrative data is likely to be the primary driver of reductions in costs (via avoidance of the associated costs of data collection via surveys). Unless productivity is sufficiently higher in the public sector, the cost of conducting evaluation should be broadly equivalent between the internal/contracted-out delivery methods- favouring government only via its lower financing costs (borrowing at the risk-free interest rate rather than private sector equity-debt rates).
One of the benefits of moving analysis in-house has been the consistency of the analysis and the continuity of the work. It has allowed ESDC to build a set of analytical processes and resources that is fully adapted to ESDC needs and is flexible to its requirements. The increased resources allocated by the Evaluation Directorate over time reflected, in part, the increase demand for the conduct of this type of analysis internally and for other ESDC active labour market programs. It has also freed up internal resources whose main tasked involved the management of processes to select contractors and the following contract, as well as the management and review of their deliverables. This means that resources can be focussed on conducting evaluation activities instead.
The building blocks to develop high-class internally delivered ALMP evaluations
The cyclical framework adopted by ESDC has also allowed it to develop a pathway for evaluation that contains key steps in ensuring that analysis is continuously developed and can be refined and adapted based on evolving needs and updated evidence. Figure 4.3 uses the ROAMEF framework, which categorises policy development into stages covering Rationale, Objectives, Appraisal, Monitoring, Evaluation and Feedback. It is useful for breaking down the process and visualising it as an iterative set of interconnected processes, though it is important to note this is not intended to convey a completely linear set of relationships and connections can flow between all of the individual processes (HM Treasury, 2020[37]). This illustrates how the different sets of processes and procedures that ESDC has developed have contributed to its development of programme evaluation. The delineation of analysis into discrete cycles allows ESDC to ensure it consistently iterates its objectives and deliverables based on the results from the previous wave of evaluation. In this manner, it formalises the process for renewal of these and provides natural break-points for the programme of work. This is evident when viewing the existing three cycles next to one another; the first based upon bilateral survey-based analysis; the second augmenting this with simultaneous administrative data-based analysis; the third re‑focussing towards sub-group analysis using machine‑learning. The internal delivery of analysis allows the analytical teams to be part of this entire cycle, facilitating responsiveness to changing evaluation needs and ensuring flexibility in planning and delivery of the work.
Figure 4.3. ESDC undertakes a number of steps to assure and iterate analysis
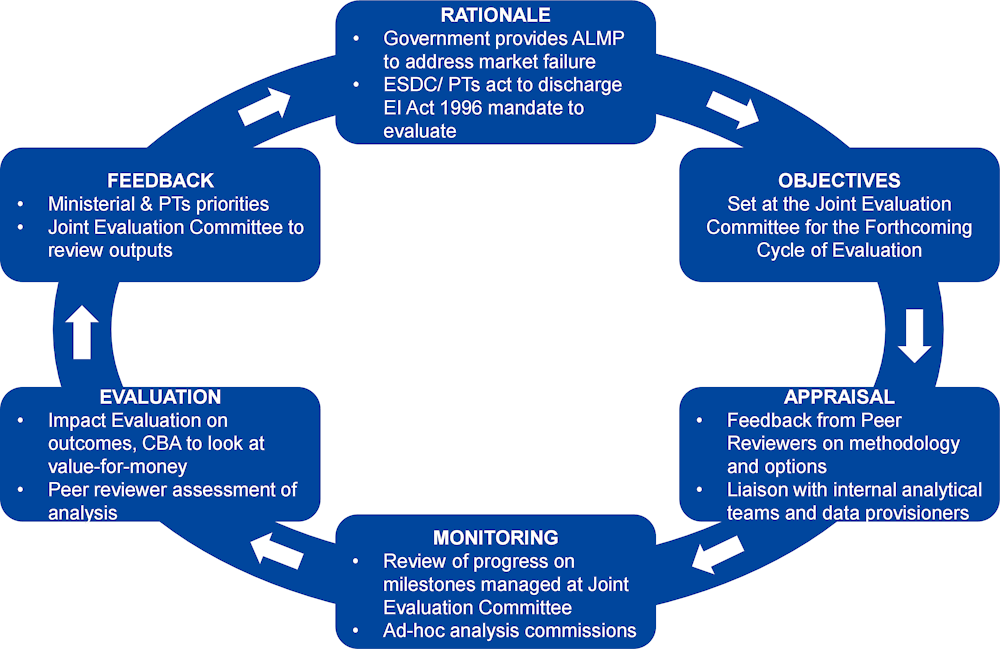
Source: Authors illustration, adapted from H M Treasury (2020[37]), Magenta Book Central Government guidance on evaluation, https://www.gov.uk/government/publications/the-magenta-book.
4.6. Peer review
In order to supplement analysis where needed, provide guidance and add additional scrutiny and quality assurance to the work, ESDC have employed a number of external academic experts. These experts lend both expert judgement and credibility to the programme of evaluation.
At the outset of the move towards in-house delivery, the production of a report to provide recommendations into the methodological requirements for evaluation of the LMDAs, was externally commissioned to guide the second stage of the evaluation (Smith, 2008[38]). The report set out the rationale for evaluation, the key research questions and suggestions on the outcomes to evaluate and the techniques to use in this evaluation. It formed the basis of the techniques utilised by ESDC in subsequent analysis and ensured that ESDC had a solid analytical platform from which to build its analytical resources. This was especially important at the beginning of their transition to in-house methodology, before expertise had really been built up internally into a sustained and established function.
ESDC have then continued to conduct peer reviews of their evaluations and reports, utilising contractual arrangements with three leading academics in the field of ALMPs.3 These reviews offer insight into the methodologies used and the writing up of results into reports. Having three independent sources of input allows ESDC to benefit from a wide‑ranging but extremely technical assessment of their policy evaluation strategies and methodology. The assessment mostly comes in the form of written comments on ESDC evaluation reports. This peer review process has also given ESDC the ability to verify the recommendations from the report which guided the second stage of LMDA evaluations and to further develop and refine the ESDC’s evaluation strategy. Box 4.3 provides some examples from the United Kingdom into how the communication of these peer reviews might be better shared with the general public and further support the credibility of the analysis. It also provides suggestions about how better strategic links with the academic may be fostered, to better inform future evidence‑making. The use of an advisory group, with different analytical specialisms, may be interesting to consider. ESDC have largely employed economists, who will offer similar professional perspectives than had a wider range of scientific disciplines been consulted.
One of the key features of the ESDC peer review system, has been the development of long-standing relationships with their main peer reviewers. This allows the peer reviewers to build a detailed and historically enriched view of the Canadian system, so that they too can develop their quality assurance over time, building on their previous assessments and their own institutional knowledge. At the same time this brings risks over future proofing, if these relationships cease to exist. This kind of knowledge becomes more difficult to institutionalise than if it existed internally to ESDC. The presence and retention of the previous assessments mitigates this risk somewhat.
Having a standardised template for peer reviews, with sections on the different aspects of the evaluation that have been reviewed (for example, the data, techniques, outcomes evaluated and the assessment of their use, advantages and shortcomings) and publishing summaries of them alongside the final ESDC evaluation reports would give greater confidence to the results reported, as it would allow the public to explicitly see how experts in the field appraise ESDC’s work and have confidence in the results (see (BIS, 2015[39]) for an example of where this is done in the United Kingdom).
The peer reviewers have not been in a position to scrutinise the underlying data and code used to produce results, which is not unusual for this type of assessment. But it does mean there is a primacy for this to be done correctly as part of ESDCs usual analytical processes. Peer reviewers cannot provide verification of the underlying analysis, but they require sufficient documentation to comment on analysis and outputs, provide guidance on at least part of the analytical structure and clarity (as it pertains to communicating results). Most importantly for this part of the quality assurance, they provide validation of the techniques and methods and on the underlying data and methodology.
Box 4.3. Put more peer in your review
The Department for Work and Pensions (DWP) in the United Kingdom offers practical examples that can increase trust and make best use of academic peer reviewers to inform policy analysis:
Methods Advisory Group – Is an expert panel in the DWP consisting of external specialists from several different scientific disciplines with the express intention of supporting the Chief Scientific Advisor to utilise cutting-edge scientific, technical and analytical approaches to generate robust evidence on analytical questions. In practice this group can be consulted prior to undertaking any research to offer advice on intended data and methodological approach. That its membership is diverse across the sciences allows cross-fertilisation of ideas to help avoid group-think. Individual members with specific subject expertise have also built up bilateral links with their relevant policy makers, to take advantage of more informal knowledge sharing. Applications to join the group are voluntary and appointments are made by open advertisement.
Areas of Research Interest – GO Science supports ministries to publish a summary of their core strategic research questions. This allows an open and transparent communication with academics, that allows them to structure their research proposals to areas of the government’s ministries and opens the path for future debate between policy makers and academics. The DWP has utilised their framework to embark on a series of national seminars taking place at universities, where government and academic researchers present work based around these themes. The idea being to foster further links between the DWP and the research communities.
PhD placements – DWP also participates in a broader government scheme to bring PhD students into the department for short periods- around three months- to work on specific research questions. The scheme is meant to be mutually beneficial to the department and individuals- giving the former access to extra, specialised resources to answer specific research questions and the latter experience in using rich, administrative data and practical implementation of the skills they have acquired. It has the additional benefit of further embedding the links between government and academia that the department has been developing. This is facilitated through a broader scheme run by the Open Innovation team, a team that sits within the Cabinet Office with a remit to generate analysis and ideas for policy by working with external experts.
ESDC already have informal engagement and good links with some universities, so are benefitting from some of these engagements already. However, proceeding on a more formalised basis may further encourage innovation and would open up opportunity to candidates for placements, and for academics research interests, in a wider range of universities on a more systematic basis.
Source: Methods Advisory Group, https://www.gov.uk/government/groups/dwp-methods-advisory-group; Areas of Research Interest, https://www.gov.uk/government/collections/areas-of-research-interest; PhD placements, https://openinnovation.blog.gov.uk/wp-content/uploads/sites/214/2020/10/OiT_PhD_Recruitment.pdf.
4.7. Summary
ESDC has made virtue of rich administrative data to conduct high-quality analysis of ALMPs using observational studies. It ensures that participants and non-participants are alike using a combination of techniques. The virtue of this is that it can use the administrative data available to construct pools of similar participants and non-participants and supplement this with a method that also controls for differences between individuals that do not change over time. Considering whether to supplement this analysis with well-designed randomised tests at the PTs level, would allow ESDC to look at more detailed questions on programme design and the best mode of delivery. A range of work is undertaken to demonstrate that the statistical models chosen are not sensitive to the variables they contain. Some extensions to testing, building on already disaggregated PTs reporting, would allow even further investigation in questions of model specification. Diagnostics tests are also performed to ensure that the estimates conform to the underlying assumptions necessary for them to provide robust results, such as ensuring participant and non-participants are alike and that differences between them are stable over time.
ESDC performs a thorough cost-benefit analysis, employing data on costs to properly contextualise the impacts of programmes. This could be extended further with incorporation of data on health and more work to vary assumptions to demonstrate uncertainty. All of this analysis is performed in-house, with expertise developed over the years by ESDC. In addition to internal analytical teams, ESDC uses expert external peer reviews to provide scrutiny and credibility to this work.
References
[19] Arni, P. (2011), Langzeitarbeitslosigkeit verhindern: Intensivberatung und Coaching für ältere Stellensuchende.
[20] Arni, P. et al. (2013), L’impact des réseaux sociaux sur le retour à l’emploi des chômeurs, State Secretariat for Economic Affairs SECO, https://www.seco.admin.ch/seco/en/home/Publikationen_Dienstleistungen/Publikationen_und_Formulare/Arbeit/Arbeitsmarkt/Informationen_Arbeitsmarktforschung/l_impact-des-reseaux-sociaux-sur-le-retour-a-lemploi-des-chomeur.html.
[21] Arni, P. and A. Schiprowski (2015), Die Rolle von Erwartungshaltungen in der Stellensuche und der RAV-Beratung (Teilprojekt 2): Der Jobchancen-Barometer und die Erwartungshaltungen der Personalberatenden, https://www.iza.org/publications/r/178/die-rolle-von-erwartungshaltungen-in-der-stellensuche-und-der-rav-beratung-teilprojekt-2-pilotprojekt-jobchancen-barometer.
[30] Benzeval, M. and K. Judge (2001), “Income and health: the time dimension”, Social Science & Medicine, Vol. 52/9, pp. 1371-1390, https://doi.org/10.1016/S0277-9536(00)00244-6.
[39] BIS (2015), “BIS Evaluation Summary and Peer Review Title: Measuring the Net Present Value of Further Education in England”, https://www.gov.uk/government/publications/further-education-comparing- (accessed on 14 October 2021).
[17] Boll, J. et al. (2013), Evaluering På rette vej - i job, https://star.dk/media/1309/paa-rette-vej-i-job-evaluering.pdf.
[16] Boll, J. and M. Hertz (2009), Aktive Hurtigere tilbarge, https://star.dk/media/1358/aktive-hurtigere-tilbage-implementering-og-deltageroplevelse.pdf.
[24] Caliendo, M. and S. Kopeinig (2008), “Some practical guidance for the implementation of propensity score matching”, Journal of Economic Surveys, Vol. 22/1, pp. 31-72, https://doi.org/10.1111/j.1467-6419.2007.00527.x.
[7] Card, D., J. Kluve and A. Weber (2018), “What Works? A Meta Analysis of Recent Active Labor Market Program Evaluations”, Journal of the European Economic Association, Vol. 16/3, pp. 894-931, https://doi.org/10.1093/JEEA/JVX028.
[32] Cheung, M. et al. (2019), “Does Job Search Assistance Reduce Unemployment? Experimental Evidence on Displacement Effects and Mechanisms”, SSRN Electronic Journal, https://doi.org/10.2139/SSRN.3515935.
[28] Department of Finance and Administration (2006), Handbook of Cost Benefit Analysis, Commonwealth of Australia, https://www.pmc.gov.au/sites/default/files/files/handbook-of-cb-analysis-2006.pdf.
[2] DiNardo, J. and D. Lee (2011), “Program Evaluation and Research Designs”, in Handbook of Labor Economics, Elsevier, https://doi.org/10.1016/s0169-7218(11)00411-4.
[23] ESDC (2021), Analysis of Employment Benefits and Support Measures (EBSM) Profile and Medium-Term Incremental Impacts from 2010 to 2017, Employment and Social Development Canada (unpublished).
[8] ESDC (2019), Quantitative Methodology Report – Final, Employment and Social Development Canada (unpublished).
[29] ESDC (2016), Cost-Benefit Analysis of Employment Benefits and Support Measures, Employment and Social Development Canada, https://publications.gc.ca/site/eng/9.834566/publication.html.
[27] Fujiwara D (2010), The Department for Work and Pensions Social Cost-Benefit Analysis framework: Methodologies for estimating and incorporating the wider social and economic impacts of work in Cost-Benefit Analysis of Employment Programmes, Department for Work and Pensions, United Kingdom, https://assets.publishing.service.gov.uk/government/uploads/system/uploads/attachment_data/file/214384/WP86.pdf.
[36] Gingras, Y. et al. (2017), “Making Evaluation More Responsive to Policy Needs: The Case of the Labour Market Development Agreements”, Canadian Journal of Program Evaluation, Vol. 32/2, https://doi.org/10.3138/cjpe.31119.
[31] Grogger, J. (1998), “Market Wages and Youth Crime”, Journal of Labor Economics, Vol. 16/4, pp. 756-791, https://doi.org/10.1086/209905.
[25] Handouyahia, A., T. Haddad and F. Eaton (2013), Kernel Matching versus Inverse Probability Weighting: A Comparative Study, International Journal of Mathematical and Computational Sciences, https://publications.waset.org/16101/pdf.
[4] Heckman, J., R. Lalonde and J. Smith (1999), “The Economics and Econometrics of Active Labor Market Programs”, in Handbook of Labor Economics, Elsevier, https://doi.org/10.1016/s1573-4463(99)03012-6.
[37] HM Treasury (2020), Magenta Book: Central Government guidance on evaluation, https://www.gov.uk/government/publications/the-magenta-book.
[33] HM Treasury (2020), The Green Book: appraisal and evaluation in central government, https://www.gov.uk/government/publications/the-green-book-appraisal-and-evaluation-in-central-governent.
[18] Høeberg, L. et al. (2011), Evaluering Unge-Godt i gang, Danish Agency for Labour Market and Recruitment, https://star.dk/om-styrelsen/publikationer/2011/06/evaluering-unge-godt-i-gang/.
[9] Iacus, S., G. King and G. Porro (2012), “Matching for Causal Inference Without Balance Checking”, SSRN Electronic Journal, https://doi.org/10.2139/SSRN.1152391.
[26] Kauhanen, A. and H. Virtanen (2021), “Heterogeneity in Labor Market Returns to Adult Education”, ETLA Working Papers, No. 91, http://pub.etla.fi/ETLA-Working-Papers-91.pdf.
[5] Kluve, J. and J. Stöterau (2014), A Systematic Framework for Measuring Employment Impacts of Development Cooperation Interventions, Deutsche Gesellschaft für Internationale Zusammenarbeit (GIZ) GmbH, https://energypedia.info/images/5/54/A_Systematic_Framework_for_Measuring_Employment_Impacts_of_Development_Cooperation_Interventions.pdf (accessed on 4 June 2020).
[13] Krogh Graversen, B., B. Damgaard and A. Rosdahl (2007), Hurtigt I Gang, Socialforskningsinstituttet, https://pure.vive.dk/ws/files/256773/0710_Hurtigt_i_gang.pdf.
[1] Leeuw, F. and J. Vaessen (2009), Address the attribution problem, Network of Networks of Impact Evaluation, http://www.dmeforpeace.org/sites/default/files/Leeuw%20and%20Vaessen_Ch4.pdf.
[34] New Zealand Treasury (2015), Guide to Social Cost Benefit Analysis, https://www.treasury.govt.nz/publications/guide/guide-social-cost-benefit-analysis.
[10] OECD (2022), Impact Evaluation of Vocational Training and Employment Subsidies for the Unemployed in Lithuania, Connecting People with Jobs, OECD Publishing, Paris, https://doi.org/10.1787/c22d68b3-en.
[35] OECD (2020), “Impact evaluation of labour market policies through the use of linked administrative data”, OECD, Paris, https://www.oecd.org/els/emp/Impact_evaluation_of_LMP.pdf.
[3] OECD (2020), “Impact Evaluations Framework for the Spanish Ministry of Labour and Social Economy and Ministry of Inclusion, Social Security and Migrations”, OECD, Paris, http://t4.oecd.org/els/emp/Impact_Evaluations_Framework.pdf.
[14] Rosholm, M. and M. Svarer (2009), Kvantitativ evaluering af Alle i Gang, Danish Agency for Labour Market and Recruitment, https://star.dk/media/1361/alle-i-gang-kvantitativ-evaluering.pdf.
[12] Rosholm, M. and M. Svarer (2009), Kvantitativ evaluering af Hurtig i gang 2 Af, Danish Agency for Labour Market and Recruitment, https://star.dk/media/1478/hurtigt-i-gang-2-kvantitativ-evaluering.pdf.
[22] SECO (2021), Optimierung RAV-Beratung, https://www.arbeit.swiss/secoalv/de/home/menue/institutionen-medien/projekte-massnahmen/rav-beratung.html.
[38] Smith, D. (2008), Analytical Framework for the Medium Term Indicators (MTI) Framework, Unpublished.
[15] Svarer, M. et al. (2014), Evaluering af mentorindsats til unge uden uddannel- se og job, Danish Agency for Labour Market and Recruitment, https://star.dk/media/6995/evaluering-mentorindsats-til-unge-uden-uddannelse-og-job.pdf.
[11] The Danish Agency for Labour Market and Recruitment (STAR) (2019), Evidence-based policy-making, https://www.star.dk/en/evidence-based-policy-making/.
[6] Wooldridge, J. (2009), Introductory econometrics : a modern approach, South Western Cengage Learning, Mason OH.
Notes
← 2. Lasso regression is used to determine these variables, via the minimisation of the Extended Bayesian Information Criteria.
← 3. Prof. Guy Lacroix (Université Laval and HEC Montréal), Prof. Michael Lechner (University of St. Gallen, Swiss Institute for Empirical Economic Research) and Prof. Jeffrey Smith (University of Wisconsin-Madison), have all provided systematic and sustained peer review contributions to the evaluation cycles.