In this report ASEAN, as a region, includes the following eight jurisdictions: Cambodia, Indonesia, Lao PDR, Malaysia, the Philippines, Singapore, Thailand and Viet Nam. Asia, as a region, includes the following 18 jurisdictions: Bangladesh, Cambodia, People’s Republic of China, Hong Kong (China), India, Indonesia, Japan, Korea, Lao PDR, Malaysia, Mongolia, Pakistan, Philippines, Singapore, Sri Lanka, Chinese Taipei, Thailand and Viet Nam.
Mobilising ASEAN Capital Markets for Sustainable Growth

Annex A. Methodology for data collection and classification
Balance sheet information for non-financial listed firms
The information presented in Chapter 1.1 is based on LSEG Datastream. The unbalanced global panel dataset contains financial statement information for non-financial listed companies between 2005 and 2022. The universe covers 52 320 companies registered in 135 countries.
Financial information cleaning
The raw financial dataset contains several firm-year observations when a company reports for different purposes. To construct a panel with a unique firm-year observation, the following steps are applied:
Financial companies are excluded
Firms listed on an over-the-counter (OTC) market are excluded
Security types classified as “units” and “trust” are excluded
Firms identified as delisted are excluded
For firms with multiple observations but different countries of domicile, their true country of domicile is manually checked to remove the duplicates
Financial statements covering a 12-month period are used
Companies with at least one observation showing negative assets or negative fixed assets are excluded
Financial information is adjusted by annual US Consumer Price Index changes and information is reported in 2022 USD
Industry classification
LSEG Datastream uses the Reference data Business Classification (TRBC).
Table A A.1. Economic sectors used in the balance sheet information data
Listing information
The information presented in Figure 1.2 is based on LSEG Screener and the following criteria are used to clean the data:
Security type classified as “units” and “trust” are excluded
For firms with multiple listings, only primary listings are kept
For firms with multiple observations but different countries of domicile, their true country of domicile is manually checked to remove the duplicates.
Firms trading on over-the-counter (OTC) markets and those listed on multilateral trading facilities (MTFs) or SME/growth markets are excluded.
Special Purpose Acquisition Companies (SPACs) are excluded.
Investment funds are excluded.
Real Estate Investment Trusts (REITs) are excluded.
Public equity data
The information on IPOs and SPOs or follow-on offerings presented in Section 1.5.1 is based on transaction and/or firm-level data gathered from several financial databases, such as LSEG (Screener, Datastream), FactSet and Bloomberg. Considerable resources have been committed to ensuring the consistency and quality of the dataset. Different data sources are checked against each other and, the information is also controlled against original sources, including regulator, stock exchange and company websites and financial statements.
Country coverage and classification
The dataset includes information about all IPOs and SPOs or follow-on offerings by financial and non-financial companies. All public equity listings following an IPO, including the first-time listings on an exchange other than the primary exchange, are classified as a SPO. If a company is listed on more than one exchange within 180 days, those transactions are consolidated under one IPO. The country breakdown is carried out based on the stock exchange location of the issuer. It is possible that a company becomes listed in more than one country when going public. The financial databases record a dual listing as multiple transactions for each country where the company is listed. However, there is also a significant number of cases where dual listings are reported as one transaction only based on the primary market of the listing. For this reason, the country breakdown based on the stock exchange is based on the primary market of the issuer. The IPO and SPO data are collected on a deal basis via commercial databases in current USD values. Issuance amounts initially collected in USD were adjusted by 2023 US Consumer Price Index (CPI).
Exclusion criteria
With the aim of excluding IPOs and SPOs by trusts, funds and special purpose acquisition companies the following exclusion criteria are used:
Financial companies that conduct trust, fiduciary and custody activities
Asset management companies such as health and welfare funds, pension funds and their third‑party administration, as well as other financial vehicles
Open-end investment funds
Other financial vehicles
Grant-making foundations
Asset management companies that deal with trusts, estates and agency accounts
Special Purpose Acquisition Companies (SPACs)
Closed-end investment funds
Trading on over-the-counter (OTC) markets
Security types classified as “units” and “trust”
Real Estate Investment Trusts (REITs)
Industry classification
LSEG uses the Reference data Business Classification (TRBC) Industry Description. The economic sectors used in the analysis are the following economic sectors:
Table A A.2. Economic sectors used in the public equity data
Corporate bond data
Data presented on corporate bond issuances in Section 1.5.2 are based on OECD calculations using data obtained from London Stock Exchange Group (LSEG)that provides international deal-level data on new issues of corporate bonds that are underwritten by an investment bank. The database provides a detailed set of information for each corporate bond issue, including the identity, nationality and sector of the issuer; the type, interest rate structure, maturity date and rating category of the bond, the amount of and use of proceeds obtained from the issue. Convertible bonds, deals that were registered but not consummated, preferred shares, sukuk bonds, bonds with an original maturity less than or equal to one year or an issue size less than USD 1 million are excluded from the dataset. The analyses in the report are limited to bond issues by non-financial companies. The industry classification is carried out based on the TRBC Industry Description. The country breakdown is carried out based on the issuer’s country of domicile. Yearly issuance amounts initially collected in USD were adjusted by 2023 US CPI.
Given that a significant portion of bonds are issued internationally, it is not possible to assign such issues to a certain country of issue. For this reason, the country breakdown is carried out based on the country of domicile of the issuer.
Early redemption data
When calculating the outstanding amount of corporate bonds in a given year, issues that are no longer outstanding due to being redeemed earlier than their maturity should also be deducted. The early redemption data are obtained from LSEG WS and cover bonds that have been redeemed early due to being repaid via final default distribution, called, liquidated, put or repurchased. The early redemption data are merged with the primary corporate bond market data via international securities identification numbers (i.e. ISINs).
Rating data
Rating information is based on OECD calculations using data obtained from LSEG that provides rating information from three leading rating agencies: S&P, Fitch and Moody’s. For each bond that has rating information in the dataset, a value of 1 is assigned to the lowest credit quality rating (C) and 21 to the highest credit quality rating (AAA for S&P and Fitch and Aaa for Moody’s). There are eleven non-IG categories: five from C (C to CCC+); and six from B (B- to BB+). There are ten IG categories: three from B (BBB- to BBB+); and seven from A (A- to AAA).
If ratings from multiple rating agencies are available for a given issue, their average is used. Some issues in the dataset, on the other hand, do not have rating information available. For such issues, the average rating of all bonds issued by the same issuer in the same year (t) is assigned. If the issuer has no rated bonds in year t, year t-1 and year t-2 are also considered, respectively. This procedure increases the number of rated bonds in the dataset and hence improves the representativeness of rating‑based analyses. When differentiating between investment and non‑IG bonds, the final rating is rounded to the closest integer and issues with a rounded rating less than or equal to 11 are classified as non‑IG.
Industry classification
For industry classification, dataset on corporate bonds uses the Reference data Business Classification (TRBC) Industry Description. The economic sectors used in the analysis are the following economic sectors:
Table A A.3. Economic sectors used in the corporate bond data
MSCI data
The MSCI data used in the Section 1.6.2 has been retrieved from the equity index constituents disclosed by MSCI, and the data is as of September 1, 2023. The details are cross-referenced with the OECD dataset on listed companies. Industry classification and market capitalisation are extracted from this dataset built with the aforementioned process on “Listing Information”. The information on listed companies was as of end 2022, REITS and investment funds are excluded from the analysis. The matched sample used in the analysis represents nearly 90% of the total weight for the MSCI Emerging Asia index and over 90% of the weight for the MSCI Emerging and AC Asia Pacific indices.
Ownership data
The main source of information is the FactSet Ownership database. This dataset covers companies with a market capitalisation of more than USD 50 million and accounts for all positions equal to or larger than 0.1% of the issued shares. Data are collected as of end of 2023 in current USD, thus no currency nor inflation adjustment is needed. The data are complemented and verified using LSEG and Bloomberg. Market information for each company is collected from LSEG. The dataset includes the records of owners for 31 342 companies listed on 115 markets covering 94% of the world market capitalisation. For each of the countries/regions presented, the information corresponds to all listed companies in those countries/regions with available information.
The information for all the owners reported as of the end of 2023 is collected for each company. Some companies have up to 5 000 records in their list of owners. Each record contains the name of the institution, the percentage of outstanding shares owned, the investor type classification, the origin country of the investor, the ultimate parent name, among other things.
The table below presents the five categories of owners defined and used in this report following (De La Cruz, Medina and Tang, 2019[1]). Different types of investors are grouped into these five categories of owners. In many cases, when the ultimate owner is identified as a Government, a Province or a City and the direct owner was not identified as such, ownership records are reclassified as public sector. For example, public pension funds that are regulated under public sector law are classified as government, and sovereign wealth funds (SWFs) are also included in that same category.
For the information provided in Table 2.2, the control is not restricted to the state where the company is listed. It can be any state, e.g. a company listed in Viet Nam can be controlled by a state different from the Vietnamese state. Therefore, the definition of state used in the table may differ from that used in individual jurisdictions.
Table A A.4. Categories of owners defined and used in the report
Industry classification
LSEG Datastream uses the LSEG TRBC. The economic sectors used in the analysis are the following:
Table A A.5. Economic sectors used in the ownership data
Sentiment indices from the NLP work
Definition of AI sentiment and polarity indices
To create the sentiment indices with the AI articles, defining the Sentiment and Polarity indices with its tone of the news is mandatory to show the AI interest of each country (Alonso Robisco and Carbó Martinez, 2023[2]). According to the publication, the Sentiment Index and Polarity Index were generated by the probability scores from the BERT model, which is apart from the traditional machine learning, the dictionary-based model for sentiment analysis. By using the probability scores of the positive and negative, those indices demonstrate the AI sentiments of Japan and Korea.
Choosing newspapers and webcrawling
Before scraping the browsers, choosing proper news platforms is very important which represent each nation’s economic status and atmosphere. The Nikkei Shimbun (also known as the Nihon Keizai Shimbun; https://www.nikkei.com/) was used for Japanese sentiment analysis, and The Korea Economic Daily (nicknamed Hankyung; https://www.hankyung.com/) was chosen for that of Korea, since both news platforms well stand out for each country, based on the number first circulation for the economic news, respectively.
The main logical tools by Python to scrape the data could be adjusted to both since the platforms have a lot of similarities as the web was created by front-end developers with HTML, CSS, and Javascript. Besides, as they have the similar structures and categories, International, Politics, Opinion, Financial, and Economy sections were scraped to establish an identical data setup of both platforms. Therefore, each article’s released date, headline, summary, and its url were scraped and contained to the Dataframe, which is a basic dataset framework of Python to use Pandas. Based on the customized web crawling codes, 436,509 Korean articles which include 9,730 AI articles and 44,222 Japanese ones which have1,027 AI related ones were scraped from January 2021.
Figure A A.1. Nikkei Shimbun and Hankyung
Source: https://www.nikkei.com/ and https://www.hankyung.com/
Labelling and pre-processing
After scraping the articles for the certain period, extracting the articles whose contents are related to the AI and classifying them with its sentiments would be needed1. While tokenizing each headline and summary, the articles which mention AI, Generative AI, and Chat GPT were automatically taken out and labelled by the Python with “AI: 1, non-AI: 0”2. As for the sentiment labelling process, the articles related to the AI were labelled by “negative: -1, neutral: 0, and positive: 1” with their tones of the writing. This was also labelled by whether related to finance (1) or not (0).
Since the Japanese and Korean languages share considerable similarities3, the API of DeepL, which is the deep learning-based AI translator, allows the Korean articles to be fully translated into Japanese, so that it enables us to understand the contexts and classify them with the three different sentiments. By using the API, the Large Languages Model (LLM) was saved into the Python Dataframe with its translated version, to make it easier to conduct the labelling. After classifying the articles with their contexts, the labelled data would be used to the sentiment analysis applied to the BERT, which is the recent deep learning model using Tensor Processing Unit (TPU).
Figure A A.2. The BERT Model and Chat GPT
Source: https://wikidocs.net/book/2155
The BERT model and the sentiment scores
The BERT (Bidirectional Encoder Representations from Transformers) model is a recent deep learning model of machine learning and Natural Language processing (NLP), using embedded LLMs to classify the sentiment while being based on the labelled data. Since the BERT is a masked language model, it uses the hidden masked sentence bidirectionally to predict the next words, based on its originally embedded contexts and labelled data.
With the BERT, the data was able to be estimated to the three different sentiments scores. Compared to the previous machine learnings, since the BERT is a pretrained and fine-tuning model, it could improve the previous ones more efficient with general transfer learning methods. By predicting the next sentences, the model could lower the required number of the trained data and eliminates the overfitting issues which decreases the performance. The Google Colab, which is an open platform to use TPU, was used for the whole sentiment analysis procedures. Since the ‘bert-base-multilingual-cased’ model offers 104 different languages with the analysis, the BERT could automatically recognise the language and produce the results. The Python code were generated and modified by ChatGPT.
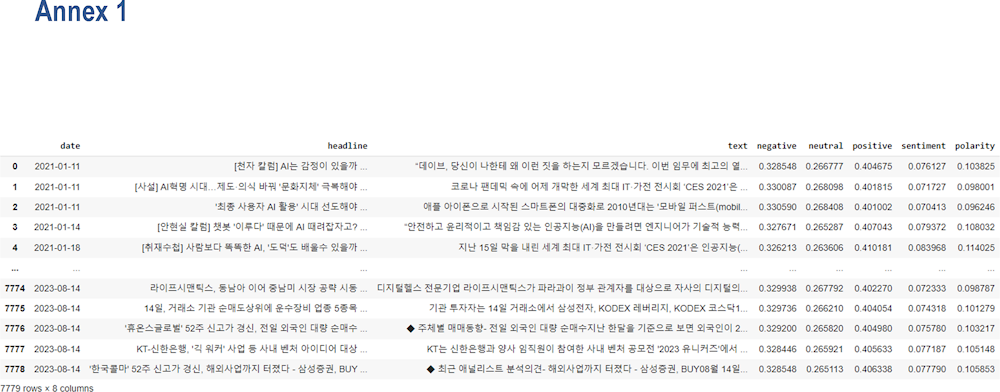
The sentiment scores from the BERT are based on the daily articles’ headline and summary and its sentimental labels. By calculating the average of daily scores with each article, the sentiment and polarity indices were finally obtained throughout those procedures.
Figure A A.3. Data frame of Japanese news: Sentiment scores, sentiment and polarity index

Figure A A.4. Data frame of Korean news: Sentiment scores, sentiment and polarity index
Sustainable bonds data and coverage
This dataset on sustainable bonds is mainly collected from LSEG and contains deal-level information of nearly 14 400 bonds issued by both the corporate and official sectors from 103 jurisdictions since 2013. This dataset provides a detailed set of information for each sustainable bond issue, including the identity, nationality, and industry of the issuer; the type, interest rate structure, maturity date and rating category of the bond, the amount of and “use of proceeds” obtained from the issue. The issuance amounts were adjusted by 2023 US CPI.
For sustainable bonds, values for corporations correspond to the “gross proceeds” (i.e., the amount paid by investors to acquire the bonds) in most cases. Where the information on the gross proceeds could not be retrieved, the “original amount issued” (i.e., the face value of the bonds in their legal documentation) has been used as follows: 22% of the amount issued from 2013 to 2023 corresponds to the original amount issued, whereas the remaining 78% corresponds to the gross proceeds. For that 78% in which the gross proceeds are used, the original amount issued is 2.9% higher. However, the amount issued in “all corporate bonds”, which includes conventional bonds, corresponds to the gross proceeds amounts in all cases.
Countries in the Asia region include Bangladesh, China, Hong Kong (China), Macau (China), India, Indonesia, Japan, Korea, Lao PDR, Malaysia, Marshall Islands, Philippines, Singapore, Chinese Taipei, Thailand, Viet Nam. Countries in the ASEAN region in the sample include Indonesia, Lao PDR, Malaysia, Philippines, Singapore, Thailand, and Viet Nam. Countries in Asia (exc. CN and JP) include Bangladesh, Hong Kong (China), Macau (China), India, Korea, Marshall Islands, and Chinese Taipei.
LSEG data contains both Regulation S and Rule 144A sustainable bonds. Rule 144A presents a safe harbour from the registration requirements of the Securities Act for resales of securities not fungible with securities listed on a US securities exchange to qualified institutional buyers. Regulation S provides a safe harbour from the registration requirements of the Securities Act for offerings made outside the United States (Bruckhaus, 2017[3]). The calculations presented take account of this factor, and an exercise to eliminate the duplication when a single bond was issued both under Regulation S and Rule 144A was performed.
In Table 4.1, for the GSS bonds where more than one “use of proceeds” was disclosed by the issuer, the amount issued by the GSS bond was equally split for each of the use of proceeds. For example, if a GSS bonds amounting to USD 1 000 displayed clean transport and energy efficiency as promised use of proceeds, USD 500 was allocated into the category clean transport and USD 500 into energy efficiency one.
In Table 4.2, for the SLBs where more than one key performance indicator was disclosed by the issuer, the amount issued by the SLB was equally split for each of the key performance indicators. For example, if a SLB amounting to USD 1 000 displayed renewable energy and sustainable forest management as key performance indicators, half of that amount was allocated into the category renewable energy and half into the sustainable and forest management one.
References
[2] Alonso Robisco, A. and J. Carbó Martinez (2023), “Analysis of CBDC narrative of central banks using large language models”, https://doi.org/10.53479/33412.
[3] Bruckhaus, F. (2017), SEC Issues Interpretations Relating to Rule 144A and Regulation S, Oxford Business Law Blog, https://blogs.law.ox.ac.uk/business-law-blog/blog/2017/01/sec-issues-interpretations-relating-rule-144a-and-regulation-s.
[1] De La Cruz, A., A. Medina and Y. Tang (2019), “Owners of the World’s Listed Companies”, OECD Capital Market Series, Paris, http://www.oecd.org/corporate/Owners-of-the-Worlds-Listed-Companies.htm.
Notes
← 1. When it comes to the current machine learning technology, classifying the articles by reading them one by one is inevitable to figure out whether it is related to the AI and to define the sentiments. If extracting the articles just by the bag of words without reading the context, this may cause errors and lower the model’s functional performance.
← 2. Within the Korean news, words for AI, 생성AI, 인공지능, Artificial Intelligence, ChatGPT, 챗GPT, Generative AI and its related words were used. On the other hand, AI, 生成AI, ジェネラティブAI, 人工知能, Artificial Intelligence, Chat GPT, チャットGPT, Generative AI, 対話型AI and related words were used for the Japanese News.
← 3. Supported by computational linguistics and archaeological evidence, the historically adjacent Tungusic languages are the likeliest candidates to explain the similarities between Japanese and Korea, and the geographical proximity has also led to successive waves of cultural and linguistic contact, such as language borrowing. For example, with the geographically close between Japan and Korea, both languages share considerable similarity in typological features of their syntax and morphology. Besides, both has a common denominator for the presence of Chinese characters and historical influence between them.