Mario Piacentini
OECD
Innovating Assessments to Measure and Support Complex Skills

6. Defining the conceptual assessment framework for complex competencies
Abstract
This chapter outlines the key elements and tools involved during the initial phases of complex assessment design, focusing on the decisions required of assessment designers to delimit the assessment domain, progressively define the assessment arguments, describe the characteristics of tasks and identify a suitable measurement model. Evidence-Centred Design (ECD) is presented as a guiding framework for making these coherent design decisions. The chapter then illustrates the process of assessment framework development for a complex construct using the example of the PISA 2025 Learning in the Digital World assessment. This example typifies the complexities of building a new assessment when the target competencies lack established definitions and theories of development and when part of the assessment validity argument relies on correctly interpreting test takers’ behaviours in open and interactive simulation environments.
Introduction
Developing any new assessment is a challenging task. Assessment design essentially involves a series of decisions starting from identifying broad objectives and possibilities before arriving at specific tasks and measures, progressively adding in relevant constraints related to the context and circumstances of the intended assessment. In this process, assessment developers must answer several interconnected questions: 1) what claims do we want to make about students and how will these claims be used? 2) In which type of situations do we expect students to apply the skills that we want to make claims about? 3) What defines good performance in those situations? 4) What constitutes evidence of different skill levels? 5) Are those skills best evidenced in the processes or in the products of students’ work, or do we need to consider both? 6) How can we accumulate the many observations of students’ actions and behaviours into scores? 7) How do we report these scores so that assessment users can understand them and make justified conclusions? As the competencies targeted for an assessment become more complex, so does answering these questions – heightening the importance of following a principled design process that builds in validity considerations at each step along the way.
This chapter outlines the key elements and tools of the initial phases of assessment design, focusing on the decisions required of assessment designers to delimit the assessment domain and progressively define the assessment arguments, describe the characteristics of tasks and identify a suitable measurement model. The process of Evidence-Centred Design (ECD) (Mislevy and Riconscente, 2006[1]) is presented as a guiding framework for making these coherent design decisions. ECD is particularly useful for conceptualising and designing assessments of complex competencies in interactive environments, where students can acquire new knowledge and skills through automated feedback and interaction with learning resources. The chapter then illustrates the framework development process using the example of the Learning in the Digital World assessment, to be administered in the 2025 cycle of the Programme for International Student Assessment (PISA). This example was chosen as it typifies the complexities of building up a new assessment when the target competency lacks established definitions and theories of development and when part of the validity argument relies on correctly interpreting test takers’ behaviours in open simulation environments.
Complexity breeds complexity: The importance of theory to orient initial design decisions
The conceptual assessment framework defines the target constructs and the key characteristics of an assessment. In general, this framework includes an analysis of the domain, describes the target constructs, lists the latent variables to be measured and describes expected progressions on these variables, defines features of families of assessment tasks, indicates how students’ behaviours on these tasks can be converted into scores, and how these scores are accumulated to provide summary metrics and make claims about test takers. ECD provides a framework for connecting all these pieces of the assessment puzzle into a coherent frame, where specifications for task design, task performance and competency estimates are explicitly linked via an evidentiary chain.
In test development, arguably no other issue is as critical as clearly delineating the target domain and describing the constituent knowledge, skills, attitudes and contexts of application that underpin performance in that domain. Indeed, if the domain is ill-defined then no amount of care taken with other test development activities nor complex psychometric analysis once data have been collected will compensate for this inadequacy (Mislevy and Riconscente, 2006[1]). It is far more likely that an assessment achieves its intended purpose when the nature of the construct guides the construction of relevant tasks as well as the development of construct-based scoring criteria and rubrics (Messick, 1994[2]).
This critical activity becomes more challenging as the complexity of the domain (and its constituent competencies) increases. One source of difficulty stems from the lack of validated theories about the nature of such domains as well as models of how students progress in the development of relevant competencies. If we want to assess reading ability, for example, assessment developers can rely on an extensive literature that defines the knowledge and skills required and that has examined how children learn to read and progress in proficiency. However, the same understanding of the target domain or knowledge on learning progressions is not available for more complex competencies like collaborative problem solving or communication.
Another difficulty relates to the multidimensional nature of these competencies: for example, collaborative problem solving involves both the capacity to solve problems in a given domain as well as the skills and attitudes to work effectively with others. These two sets of capabilities interact in complex ways, making it hard to disentangle them from one another when reporting on students’ performance in collaborative tasks.
A third difficulty arises from the way that complex competencies manifest themselves in the real world. As discussed in previous chapters of this report, validly assessing these competencies requires being able to replicate complex performance tasks from which we can observe how people behave and adapt to problem situations. Identifying those situations, reproducing their core features in authentic digital simulations and translating traces of actions within the digital test environment into evidence for the claims represents a sequence of hurdles that assessment designers have to overcome.
In short, every new assessment needs to be guided by a theory of learning in the domain that identifies what is important to measure. Anchoring the subsequent design of tasks and the evidence model into a well-defined theoretical framework is therefore essential for generating valid inferences about test takers’ performance. However, while the theoretical knowledge accumulated during the domain analysis phase provides critical direction, especially in the initial stages of an assessment design process, it does not closely prescribe what the final assessment will look like.
Each assessment is ultimately the result of a creative design process, where a design team strives to achieve near-optimal solutions under multiple (sometimes conflicting) constraints and a certain degree of uncertainty. This design process is also iterative: several rounds of revisions are typical and, more importantly, necessary when developing assessments of complex competencies that make use of extended performance tasks. Test takers might interact with task situations in unexpected ways or things might go wrong both in terms of the user experience and in terms of the data quality. During these iterations the assessment designer often must go back and revise the theoretical student model because some variables of interest inevitably end up being more difficult to measure than initially anticipated.
The following sections of the chapter discuss the various phases of defining an assessment framework according to ECD. These phases are summarised in Figure 6.1. An analysis of the target domain – in other words, clearly defining its constituent knowledge, skills, attitudes and relevant contexts – lies at the foundation of any conceptual assessment framework. The following step is domain modelling, which involves translating these core definitions into assessment claims. This preparatory work on describing the domain orients the construction of more detailed test specifications through the three interconnected ECD models: the student model, the task model and the evidence model. Although the phases are described here sequentially, as earlier mentioned, in practice these phases are iterative.
Figure 6.1. Phases of defining the conceptual assessment framework in an ECD process
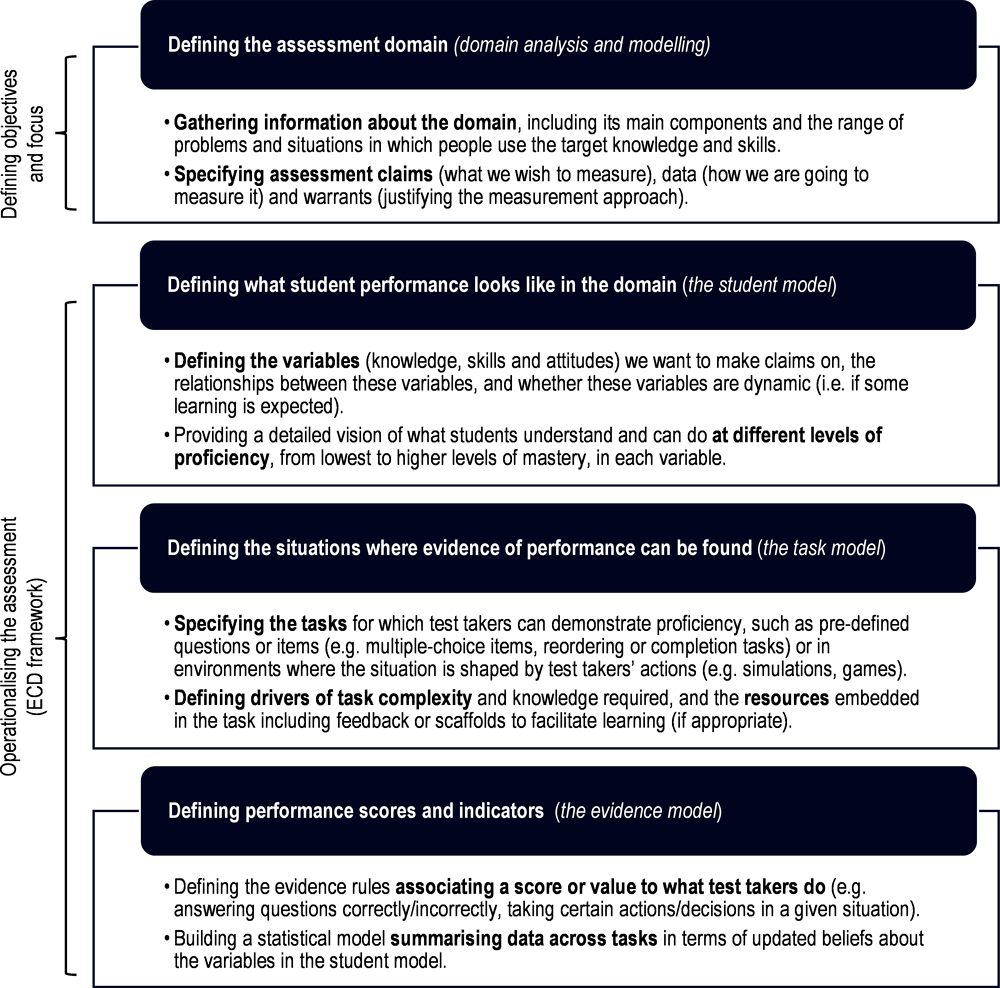
Establishing solid conceptual foundations: Domain analysis and modelling
Domain analysis
Domain analysis includes making an inventory of the concepts, language and tools that people use in the target domain, identifying the range of problems and situations in which people use those target knowledge and skills, and defining the characteristics of good performance in those domain contexts. There are many possible methods to gather this information. In traditional assessments of disciplinary subjects (e.g. mathematics), detailed descriptions of the domain are already available for use in assessment design. For international large-scale assessments, comparative reviews of curriculum content are regularly undertaken – for example for the International Association for the Evaluation of Educational Achievement (IEA) studies (Twist and Fraillon, 2020[3]). However, this is generally not the case for assessments of complex competencies. This means that it is essential to rely on the contribution of a group of experts capable of constructing new representations of what expertise means in those domains using, to the extent possible, empirical observations.
Cognitive task analysis (CTA) is one useful method for identifying and understanding the behaviours that are associated with successful outcomes in complex problem situations (Clark et al., 2008[4]). CTA uses a variety of interview and observation strategies including process tracing to capture and describe how experts perform complex tasks. For example, an established strategy used for CTA is the “critical incident technique” in which an expert is asked to recall and describe the decisions they made during an authentic situation. These descriptions generated through CTA are then used to develop training experiences and assessments, as they allow assessment designers to identify salient features of tasks that are appropriate to include as well as identify decisions that are most indicative of expertise (see Chapter 4 of this report for an example of CTA used to define the assessment domain of complex problem solving in science and engineering as well as to inform subsequent assessment design via the lens of critical decision making).
The definition of an empirically-based model for the domain can be supported by observational studies of how students work on tasks that engage the target skills. For example, in an assessment of collaboration skills, developers can craft some model collaborative activities that reflect their initial understanding of relevant situations in the domain. They can then use CTA methods to identify those students who are more or less successful in driving the collaboration towards the expected outcome and make an inventory of what students at different proficiency levels say and do (e.g. how they share information within a group, how they negotiate the sharing of tasks, etc.). Observational studies provide clarity on the sequence of actions that must be performed to achieve a performance goal and can produce exemplars of real work products or other tangible performance-based evidence that can be associated to proficiency claims.
Domain modelling
In the domain modelling phase, assessment designers collaborate with domain experts to organise the information collected during the domain analysis phase into assessment arguments (Figure 6.2). An assessment argument consists of three main elements: claims, data and warrants (Toulmin, 2003[5]; Mislevy and Riconscente, 2006[1]). A claim refers to what we wish to measure – for example, how proficiently a student solves mathematics problems or how capable they are of using language appropriately in an intercultural encounter. Data, such as the number of correct responses to test questions or behaviours observed in an interactive simulation, serve to support the claims. The warrant is the reasoning that explains why certain data should be considered appropriate evidence for certain claims.
Whenever an inference is based on complex data, such as those derived from actions in an open performance task, it becomes useful to add a fourth element to the assessment argument: alternative explanations. An alternative explanation refers to any other way(s) students could have done well in the test without engaging the relevant skills (e.g. gaming the system or guessing the right answer). For example, might a student struggle because of time pressure and not because they lack the relevant skills? Could the student be distracted by game-like aspects of the assessment?
Assessment arguments can be usefully formalised using “design patterns”. Design patterns describe, in a narrative form, the student knowledge, skills and abilities (KSAs) that are the focus of the assessment, the potential observations, work products and rubrics that test designers may want to use, as well as characteristics and variable features of potential assessment tasks. The design pattern structure helps to identify which decisions have already been made and which still need to be made. Note that a design pattern does not include specific information about how materials will be presented to students in a given task nor about how scores will provide evidence about their proficiency in a domain; this more granular level of information is provided in the successive steps of ECD via the construction of the student, task and evidence models.
Figure 6.2. Assessment design as a process of argumentation
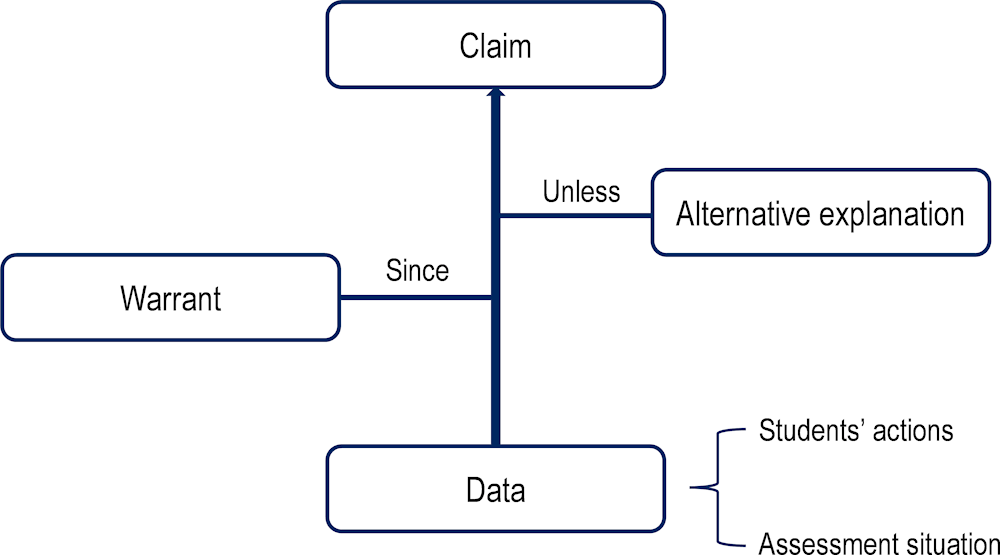
Notes: Inference flows from data to claim by justification of a warrant; the inference may also need to be qualified by alternative explanations. Data are observed actions (by the student) that need to be contextualised in the specific assessment situation.
Source: Adapted from Mislevy and Riconscente (2006[1]).
The three models of an ECD assessment framework
While the domain analysis and modelling phases provide the conceptual foundations for assessment, the three models of an ECD assessment framework guide the operationalisation of the assessment by providing substantive, technical and operational specifications used by task designers and data analysts.
The student model
The student model defines in detail the variables (KSAs) we expect to make claims about and the relationships between these variables. The student model is essentially the outcome of the assessment: it provides a map of each student’s inferred KSAs, as specified in the domain model. In the simplest case the student model contains a single variable and student performance is computed from the proportion of tasks they answer correctly. For assessments of complex competencies with extended performance tasks, there are invariably multiple skills that, together, determine proficiency. In these assessments the variables in the student model generally include knowledge of key concepts in the domain, cognitive and metacognitive processes, mastery of specific work practices and strategies, and attitudinal, motivational and affect-regulation components.
The variables and their interconnections are often represented as a map in which each variable is a node connected by one or more links with other nodes. Figure 6.3 shows an example of a student model developed by Shute, Masduki and Donmez (2010[6]) for an assessment of system thinking using an immersive role-playing game. The model consists of three first-level variables: 1) specifying variables and problems in a system; 2) modelling the system; and 3) testing the model. Each of these first-level variables is further broken down into a number of second-level variables for which it is possible to define specific observables within the game environment corresponding to students’ actions (e.g. interviewing stakeholders, collecting data, annotating hypotheses and conclusions, etc.).
Figure 6.3. An example of a student model for system thinking
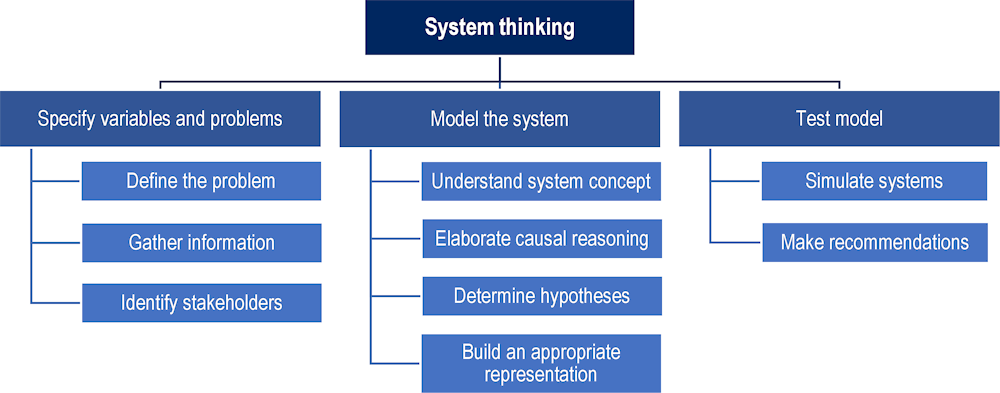
Source: Adapted from Shute, Masduki and Donmez (2010[6]).
In the student model it is important to provide a vision for what the assessment can tell us about examinees’ proficiency as they progress from the lowest to the highest levels of mastery in each of the constituent variables. Construct mapping is a design process that embeds this idea of progression, supporting the design of assessments that are closely connected to instructional goals. A construct map details what students understand and can do at incrementally higher levels of one or more proficiencies and indicates common misconceptions at each level (Wilson, 2009[7]). For example, in a construct map describing students’ progression in their understanding of the Earth in the solar system, students at “level 3” proficiency think that it gets dark at night because the Earth goes around the Sun once a day (a common error for students at this level), while students a “level 4” no longer believe that the Earth orbits the Sun daily and instead understand that this occurs on an annual basis (Briggs et al., 2006[8]).
In most psychometric models the assumption is that the variables in the student model represent latent traits that are “fixed” at the time of taking the test. This assumption might not hold in innovative simulation-based assessments because students’ knowledge or ability may change as they interact with the test environment. In other words, students may be able to learn during the assessment. This opportunity to learn during the test depends largely on the degree to which explicit and implicit feedback is integrated in the assessment tasks and environment (see Chapters 7 and 9 of this report for more on the design and implications of providing feedback as an intentional assessment design choice). Measuring the occurrence of learning within an assessment can help to identify those students who are more prepared for future learning. As discussed in Chapter 2 of this report, one core feature of next-generation assessments consists of shifting the focus of assessment from the reproduction of acquired knowledge to students’ capacities to learn from new situations and using resources.
One issue this raises is how learning dynamics can be represented within a student model. Arieli-Attali and colleagues (2019[9]) have proposed to include additional “learning layers” for each of the three ECD models in order to describe the dynamics of change from one state of knowledge to another in digital environments. In their iteration of ECD, the “Student-Change model” specifies sequences of knowledge students are expected to acquire in the test environment and the processes they need to enact in order to move along this sequence. The sequence of knowledge components can be defined in terms of knowledge precursors needed to perform a given practice in the student model. For example, sentence comprehension relies on word identification, which in turn relies on letter recognition. The Knowledge-Learning-Instruction framework developed by Koedinger, Corbett and Perfetti (2012[10]) indicates three kinds of learning processes: 1) memory and fluency building; 2) induction and refinement; and 3) understanding and sense‑making. Specifying which kind of process is needed across all the learning sequences in the student-change model guides decisions about the scaffolding to include in the assessment environment. For example, if the focal learning process is fluency building, the environment should provide multiple opportunities to practice the relevant operation. In contrast if the focal learning process for a different KSA is understanding and sense-making, then the system should provide explanations and examples (Arieli-Attali et al., 2019[9]).
The task model
The task model defines the set of situations in which test takers can demonstrate their KSAs. It indicates appropriate stimulus materials, tasks and affordances, and clarifies variables that affect task difficulty as well as describes the work products that proficient students are expected to achieve (Mislevy et al., 2010[11]). The task model is closely connected to the student model as the tasks should be designed to elicit evidence for the KSAs. Multiple task models are possible in any given assessment, and different dimensions of proficiency might be best measured through different families of tasks.
Informative task models can be represented in different ways. One useful approach involves defining a Task-Model Grammar (TMG) following the principles of assessment engineering (Luecht, 2013[12]). The TMG approach provides an explicit description of: 1) the combination of KSAs needed to solve the task; 2) the types of declarative knowledge components that are typically used to challenge the examinee; 3) the complexity of the task components (e.g. investigating one simple variable vs. a complex system); 4) auxiliary information, resources or tools that should be embedded in the task; and 5) other relevant properties or attributes associated with each of the above components that might affect item difficulty.
There are no specific boundaries as to what constitutes an appropriate task. New ideas for engaging tasks are constantly emerging as information, interactivity and gaming technologies become increasingly integrated in assessment. Scalise and Gifford (2006[13]) presented a taxonomy of task formats in computer-based testing, largely distinguished by response type and level of interactivity. In this taxonomy, multiple-choice items represent the “most constrained” end of the taxonomy while presentations and portfolios represent the “least constrained” task formats; between them lies a range of other types of tasks including selection/identification, reordering/rearrangement, substitution/correction, completion and construction tasks. Chapter 7 of this report also presents a taxonomy of three broad task formats enabled in technology-enhanced assessments centred rather on the user experience and problem type presented to students. These three task formats include non-interactive problems, interactive problems with tools and immersive problem environments. Designers of complex assessments can draw on any of these technology-enabled task types when conceptualising their task models.
Unlike in standard assessments, evidence-bearing opportunities in complex assessment tasks are not limited to how students respond to pre-defined questions. Evidence of relevant KSAs can also be extracted by observing what test takers decide to do (or not) in a simulation or game – often referred to as “stealth assessment” (see Shute, Rahimi and Lu (2019[14]) for a review). For example, Wang, Shute and Moore (2015[15]) embedded an assessment of problem solving within the game Plants vs Zombies. The goal of the game was to protect a “home” base from zombie invasion by growing different types of powerful plants; to grow the plants, players needed to collect sun power by planting sunflowers. In this stealth assessment, players could demonstrate they “understand the givens and constraints in a problem” (one of the four variables in the student model) if they decided early in the game to plant sunflowers, as this action demonstrated that they understood that a lack of sun power was the primary constraint in the game. There was no explicit question in the assessment to elicit this behaviour; rather the relevant observables were obtained by tracking the sequence of test taker actions together with the corresponding changes in the game state. In games or simulations that are explicitly designed for assessment – see also the SimCityEdu example from Mislevy et al. (2014[16]) described in Box 3.1 (Chapter 3 of this report) – an essential part of task modelling consists of defining the classes of actions that could be taken for each possible game state and associating these contextualised actions to unobservable KSAs (including no action taken at all).
When the focus of assessment is just on measuring how well students know or can do something at a given point in time, then there is no real need to incorporate feedback or scaffolds in the task. However, as already discussed, innovative assessments might want to make claims about how students learn in authentic problem situations where they have access to resources and support. In the extended-ECD model developed by Arieli-Atteli and colleagues (2019[9]) and applied to the Holistic Educational Resources and Assessment (HERA) system for teaching and assessing scientific thinking skills, a new layer called the “Task-Support” model specifies the types of support that should be provided to students to facilitate their engagement in the learning progress(es) outlined in the “Student-Change” model. Three types of learning supports are offered after student errors: 1) “rephrase” (i.e. a rewording of the question that explains in more detail what is expected); 2) “break it down” (i.e. providing the first of several steps required to answer the question); and 3) “Teach me” (i.e. a written or visual explanation of the main concepts and operations required with illustrative examples).
Other ways to provide opportunities for learning exist that can be either on-demand or prompted by specific actions and outcomes in the environment (see, for example, Chapter 9 of this report). These resources must be designed with the same level of rigour that is put into the design of the task itself, establishing explicit connections to the claims one wants to make about students’ use of these resources. For example, if the assessment aims to evaluate how students acquire fluency in a given skill (e.g. interpreting two-dimensional graphs), then providing them with a sequence of practice exercises focusing on that specific operation would be a justified resource. However, if the interest is rather on how students learn through transfer (i.e. applying concepts and skills to novel situations), then making worked examples available might represent a better way to provide scaffolding that is aligned with the assessment arguments.
The evidence model
Evidence models are the bridge between what students do in various situations (as described in task models) and what we want to infer about students’ capabilities (as expressed in the student model variables). They specify how to assign values to observable variables and how to summarise the data into indicators or scales. The evidence model actually includes two interrelated components: evidence rules and the statistical model.
Evidence rules associate a score to student actions and behaviours. Formulating such rules is rather straightforward in traditional and non-interactive assessments, particularly when multiple-choice items are used. However, more complex performance tasks require assessment designers to describe the characteristics of work products or other tangible evidence that domain experts would associate with the KSAs in the student model (Mislevy, Steinberg and Almond, 2003[17]; Mislevy and Riconscente, 2006[1]). In simulation- or game-based assessments, evidence rules often rely on interpreting actions and behaviours that are recorded as process data (see Chapter 7 of this report for a description of different sources of process data). However, interpretation is susceptible to error as actions in digital environments can often be interpreted in different ways. For example, observing that a test taker interacts with all the affordances of a simulation environment could be interpreted as demonstrating high engagement (i.e. the student confidently explores possibilities) or, conversely, high disengagement (i.e. the student does not engage meaningfully with the task). Defining evidence rules in open and interactive environments therefore requires: 1) reconstructing the universe of possible actions that the test taker can take and classifying them into meaningful groups; 2) defining the extent to which actions depend on the state of the simulation (and thus on previous actions); and 3) using this information to identify sequences of contextualised actions that demonstrate mastery of the target KSAs and that can be transformed into descriptive indicators or scores.
In the process of defining evidence rules for complex assessments, it is fairly frequent that designers have to revise their task designs – either to add affordances to capture targeted actions or to make the environment more constrained to reduce the range of possible actions and interpretations. An iterative cycle of empirical analyses and discussions with subject-matter experts is therefore essential for evidence identification in interactive environments. This process often combines a priori hypotheses about the relationships between observables and KSAs with exploratory data analysis and data mining.
Mislevy et al. (2012[18]) describe this interplay between theory and discovery for an assessment activity involving the configuration of a computer network. The researchers ran confirmatory analysis on a set of scoring rules defined by experts that considered characteristics of test takers’ submitted work products (for example, a given section of the network is considered “correct” if data successfully transfer from one computer to another). They complemented this evidence from work products by applying data mining methods to time-stamped log file entries. This analysis identified certain features including the number of commands used to configure the network, the total time taken and the number of times that students switched between networking devices as additional potential evidence that could be combined into a measure of efficiency.
The second component of the evidence model is the statistical model that summarises data across tasks or assessment situations in terms of updated beliefs about student model variables. The objective in the statistical model is to express in probabilistic terms the relationship between observed variables (e.g. responses, final work products, sequences of actions, etc.) and a student’s KSAs. Modelling specifications described in the assessment framework provide a basis for operational decisions during test construction such as deciding how many tasks are needed to make defensible conclusions based on test scores.
The simplest measurement models sum correct responses to make conclusions on competence proficiency. More complex measurement models use latent variable frameworks, for example item response theory (IRT) (de Ayala, 2009[19]; Reckase, 2009[20]), diagnostic classification models (Rupp, Templin and Henson, 2010[21]) and Bayesian networks (Levy and Mislevy, 2004[22]; Conati, 2002[23]). A Bayesian network is a graphical representation of the conditional dependencies between observables and variables (nodes), and they constitute a particularly effective way of specifying, estimating and refining a measurement model in complex assessments. The conditional probability distributions of each variable are initially set following the opinions of domain experts and then refined empirically as data are accumulated. As indicators are produced by students (as defined in the evidence rules) their scores increase with respect to the relevant node of the student model, which then propagates through the network to increase the probability for the student’s overall proficiency. Bayesian networks can also be combined with other analytical techniques (see Chapter 8 of this report for more on hybrid analytical models that combine strengths from different techniques).
Both the evidence rules and the statistical model can take into account the possibility of learning during a resource-rich assessment. If learning supports are available (e.g. hints, worked examples, scaffolds, etc.), students’ decisions to use them can be modelled to make inferences about learning skills. Specific evidence rules are needed to specify how use of the learning supports can be interpreted as evidence of productive learning behaviour; these rules likely need to be conditional on the state of the test environment at the moment the student accesses the support. For example, the decision to consult a hint can be interpreted as evidence of productive help seeking only if the student has made (unsuccessful) attempts to solve the task on their own. In terms of the statistical model, changing levels of proficiency can be represented as a Hidden Markov model. The input-output structure of a Markov model allows for estimating the contribution of each support to a change in the latent KSAs, based on the change in the observed work product following the use of a support (Arieli-Attali et al., 2019[9]).
An illustrative example: The PISA 2025 Learning in the Digital World assessment
The previous sections of this chapter have underlined that assessment design is a complex process of decision making and iteration, guided by relevant theory, constraints, data collection and analysis. To illustrate the complexities of this process using a tangible example of a complex assessment, this chapter provides a short overview of the decisions taken during the framework (and instrument) development of the PISA 2025 Learning in the Digital World (LDW) assessment. An interdisciplinary group of experts, coordinated by the OECD, led these decisions.
Domain analysis for LDW
Preparing the LDW assessment involved addressing a number of key questions, taking into account the specific constraints of the PISA test – namely: 1) What is the intended purpose of the test? 2) What type of learning is valued in the test? And 3) what concepts and practices are students expected to demonstrate and learn during the assessment? The purpose of the LDW assessment is to provide comparative, system-level data on students’ preparedness to learn and solve open problems within digital learning environments. The focus of the assessment is motivated by the proliferation of digital learning resources and the rapid increase in their use as a result of the COVID-19 pandemic. However, while the potential of digital tools for empowering learning is broadly recognised in the literature and in the field, there is still insufficient evidence on whether students around the world are prepared to use these tools effectively.
Assessing how students engage in a learning process first requires identifying the type of learning we want to observe. The expert group decided to anchor the assessment in constructivist theories of learning. Constructivism is built on the belief that learners need to be active participants in the creation of their own knowledge and that students learn better if they possess a schema on which to build new understanding and link new concepts (National Research Council, 2000[24]). Social constructivists extended these ideas and emphasised the importance of interactions with other people and systems during learning. They contend that understanding is not constructed alone or within a vacuum but rather “co-constructed” through socially negotiated interactions with other people or objects. Assessments based on constructivism move away from focusing on discrete pieces of knowledge towards examining the more complex process of knowledge creation with external tools and resources, such as how individuals learn during effective, inquiry-based learning. For the LDW assessment, the expert group decided to focus on how well students can construct new knowledge and solutions through interactions with virtual tutors and digital tools.
Constructivism assigns a central importance to self-regulated learning and metacognition. Self-regulated learning (SRL) refers to the monitoring and control of one’s metacognitive, cognitive, behavioural, motivational and affective processes while learning (Panadero, 2017[25]). Metacognition refers to the ability to monitor one’s understanding and progress and to predict one’s capacity to perform a given task (Connell, Campione and Brown, 1988[26]). Assessments that incorporate elements of metacognition ask students to reflect on what worked and what needs improving. From a design perspective, generating observations on SRL and metacognitive processes requires identifying problems that can only be solved through multiple iterations and developing test environments that include tools for monitoring and evaluating progress as well as providing feedback.
A key question during the domain analysis concerned what exactly students should learn and with what digital tools. In the digital world, tools abound that support the kinds of active and situated learning experiences that define constructivist approaches (see also Chapter 9 of this report for a more detailed description of the tools used to support self-regulated learning in the LDW assessment). Millions of students around the world design digital animations in Scratch (Maloney et al., 2010[27]) or explore scientific phenomena using PhET Interactive Simulations (Wieman, Adams and Perkins, 2008[28]). The experts referred to these practical examples from science, technology, engineering and mathematics (STEM) fields when imagining the type of work products that students should construct in the assessment as evidence of learning. Increasingly available evidence on how students’ work with these tools also provided important empirical and theoretical references for defining the practices of proficient students and the typical struggles of beginners (see Brennan and Resnick (2012[29]) for an analysis of work practices in Scratch and de Jong, Sotiriou and Gillet (2014[30]) for an analysis of students’ learning processes with scientific simulations). The opportunity to rely on an established body of evidence on instructional design and learning progressions led the expert group to focus on the scientific practices of experimentation, modelling and design of algorithmic solutions as the “objects of learning” through which students could solve problems or understand complex phenomena. In those practices, it was deemed relatively easy to identify concepts and operations, such as the control of variable strategy or the use of conditional logic, that students could practice and “learn” in the short assessment time available.
Domain modelling for LDW
Domain modelling is essentially about defining assessment arguments. The LDW assessment aims to make multiple claims including: 1) Can students construct, refine and use models with the support of digital tools? 2) Can students define and apply algorithmic solutions to complex problems? 3) Do students seek feedback on their work or seek help when they are stuck? And 4) can students accurately evaluate their knowledge gaps and progress as they engage with complex challenges?
Let’s consider the first of these claims in order to demonstrate how it can be represented through a design pattern for the LDW assessment (Table 6.1). As described earlier in this chapter, design patterns support test developers by providing a narrative description of the situations that the test should present to students as well as describing the core skills for which observables have to be generated, those that are not central to the claim but might affect performance, and the characteristic and variable features of possible tasks.
Table 6.1. Design patterns for the practice of modelling in the PISA 2025 LDW assessment
The student model in LDW
The domain analysis indicated that students can construct scientific knowledge and solve problems using digital tools if they master a set of computational thinking and scientific inquiry skills, can effectively monitor and evaluate their progress on a knowledge construction task, and can maintain motivation and manage their affective states. The student model for the LDW assessment is thus composed of three interconnected components: 1) computational and scientific inquiry practices; 2) metacognitive monitoring and cognitive regulation processes; and (3) non-cognitive regulation processes. Within each of the components, there are several facets (constituent skills).
Figure 6.4. Student model for the PISA 2025 LDW assessment
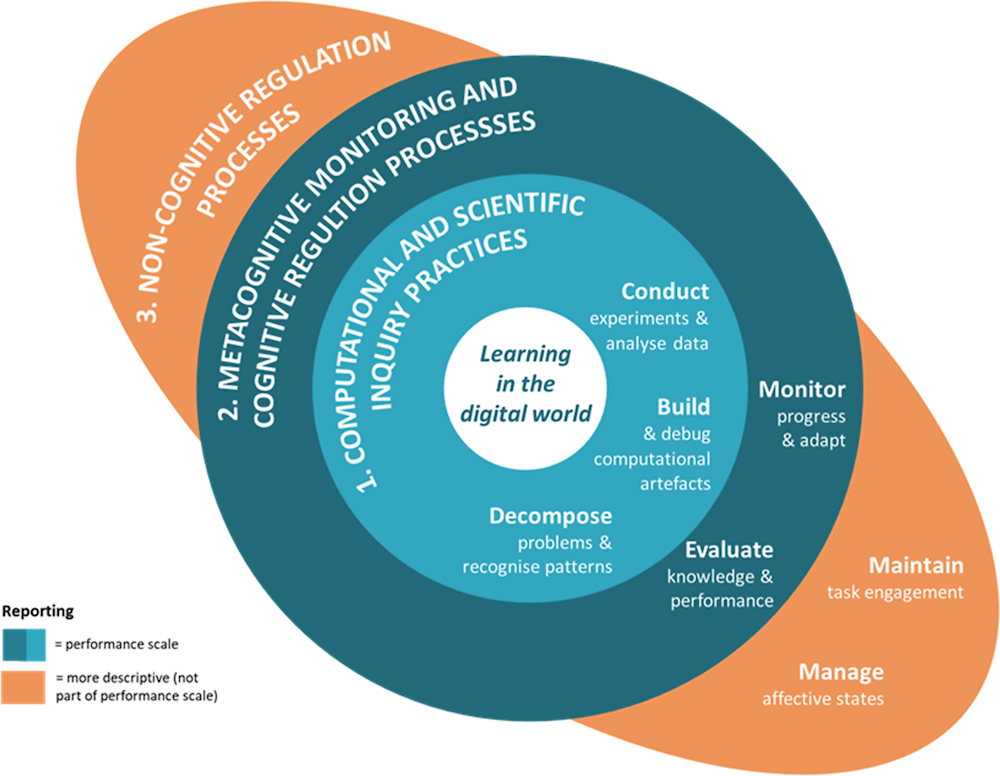
Source: OECD (forthcoming[31]).
Figure 6.4 illustrates the current version of the student model for the LDW assessment. At the core of the student model lies the construct, defined as “the capacity to engage in an iterative process of knowledge building and problem solving with digital tools” (OECD, forthcoming[31]). This definition of the construct with the notion of learning (“knowledge building and problem solving”) at its core indicates that the assessment should not only provide measures of students’ mastery of each of the constituent skills but also evaluate the extent to which students can progress towards their learning goals during the assessment.
Construct maps are currently being assembled for each of the facets of the student model (i.e. conduct experiments and analyse data, build and debug computational artefacts, etc.). The assessment development team is using data from observational studies and pilot tests to confirm initial hypotheses about what students are capable of doing at incremental levels of proficiency for each of the facets, and to identify common errors and misconceptions at each level. Similarly, the team is working on defining the content and processes of learning that can occur during the assessment. This exercise is complex as the learning gradient depends to some extent on the initial level of knowledge of the student (i.e. students who start with a low level of initial knowledge might find it easier to progress using the learning resources in the assessment).
Task models for LDW
The development team identified two main typologies of units for this assessment. Units are sequences of tasks that are connected by the same scenario or learning goal. In the first type of unit, students construct an algorithm using different tools such as block-based programming or flow charts to solve a problem. In the second type, students represent and experiment with variables using a computational model that they can use to solve problems and make predictions (e.g. building an executable concept map where any change in one variable propagates to other linked variables). Drivers of complexity have been identified for both typologies of units (see Table 6.1). These relate to the accessibility of the digital tool that students are asked to use, the familiarity of the context of application, the intuitiveness of system dynamics and relationships between variables (in modelling tasks), and the complexity of the final product (in modelling tasks, the number of variables to experiment with or the presence of complex relationships such as moderating or random variables; or in programming tasks, the need to use complex control flows such as nested loops).
The team also worked on the definition of learning resources that could be standardised across test units. On one hand, these resources need to be useful so that students have an incentive to consult them; on the other hand, resources need to encourage transfer of concepts and should therefore avoid reducing the cognitive demand of the problem too much or directly giving students the solution. The experts decided to address this complex trade-off by choosing “worked examples” as the main learning resource. The worked examples provide an indication of how similar problems can be solved but students still have to transfer what they see in the example to a different context. Other opportunities for learning are provided by affordances to test programs and models or to check the correctness of one own’s solution after submission.
The aim of generating observables to evidence learning processes also demanded an innovative organisation of the unit. While discrete skills can be efficiently assessed through short and targeted questions, the process of knowledge construction can only be assessed through more extended tasks where students have opportunities to build on their initial understanding. Each unit has thus a duration of approximately thirty minutes and is organised as a series of phases. At the beginning, a virtual agent introduces the overall learning goal of the unit, framing the experience as a tutoring session (e.g. “I’m going to teach you how to…”). After this introduction, the students complete a pre-test that aims to measure students’ prior knowledge of the concepts and operations they will have to learn and apply in the unit. The third phase is a tutorial, where students are familiarised with the core functionalities and learning affordances of the digital learning interface. The fourth “learning phase” contains a series of discrete, carefully scaffolded and incrementally more complex tasks, the latter of which requires students to apply what they have learnt throughout the whole unit to a complex and multi-step problem. After the time available for learning and problem solving has expired, students complete some self-evaluation questions and report on their affective states during the unit. This complex design aims to immerse the students in an authentic digital experience where they are motivated to learn new things. Each unit contains a well-defined set of concepts and operations that students are expected to master following a coherent instructional sequence, starting from basic and progressing towards more complex applications. Two detailed prototype units are included in the framework to guide test developers in the application of these design decisions to the assessment tasks (OECD, forthcoming[31]).
Evidence model for LDW
The evidence needed to make claims on students’ proficiency in the target KSAs is collected by checking the correctness of their responses to explicit questions in the learning and challenge phase, assessing the completeness of their work products (i.e. programs and models), and examining the strategies they followed as they worked as revealed by sequences of process data (log files). The LDW framework includes detailed evidence rules tables that describe how the observables above should be interpreted for scoring.
Some uses of process data for scoring are relatively straightforward. For example, in the modelling units, process data are used to check whether students completed all the steps required such as conducting a sufficient number of experiments to make an evidence-based conclusion on the relationship between two variables. Using process data is essential but much more complex for evaluating and interpreting SRL actions, given that any potential evidence of SRL behaviours must be evaluated in the context of the students’ previous and following actions as well as the state of the environment when the action takes place. For example, the action of seeking help from the LDW tutor is considered evidence of proficiency in the facet “monitor progress and adapt” only if the student needs help (i.e. the student does not immediately seek help at the beginning of the task without first attempting to address the task) and only if the student does what the tutor recommends (where this is possible). The team has developed complex evidence rules for SRL actions that condition the scoring of potential evidence in this way. These evidence rules will also be complemented by applying data mining methods to pilot data to uncover other potential evidence of coherent SRL behaviours.
The statistical model used in this assessment will necessarily be more complex than those used in previous PISA tests. The main challenges in the LDW assessment lie in the local dependency of the measures (i.e. the tasks are not independent). Students’ behaviours and actions in earlier tasks will likely influence subsequent performance. For example, those who carefully follow the tutorial and initial learning tasks are expected to perform better in the latter more challenging tasks. This violates the assumption of local independency of standard IRT models, requiring instead a model that is flexible and robust enough to account for dependencies across task observables.
Another complexity in defining the statistical model arises from the generation of non-random missing data. Some of the indicators for SRL are based on the choice of consulting learning resources; however, this choice is observed only for a fraction of self-selected students (i.e. those who struggle on the task are more likely to seek for resources). Tree-based item response models (IRTrees) represent one option that is being evaluated to address these issues of dependencies and non-random missing data (Jeon and De Boeck, 2015[32]). IRTrees models can deal with the dependence between observables that arise within extended tasks by capturing sequential processes as tree structures, where each branch finishes with a binary end-node. Alternative modelling approaches using dynamic Bayes nets are also being considered.
Conclusion
Thanks to progress in technology, it is now possible to build complex simulation environments that mirror or extend the real world and enable students to engage in the processes of making, communicating and interacting. Assessments using games, simulations or other digital media have the potential to generate better measures of deep learning, attitudinal beliefs and motivations, and thinking skills. In the context of international large-scale assessments, these technology-enabled innovations can serve to evaluate the efforts of education systems to support 21st Century competencies in more valid ways. However, designing new assessments in these dynamic environments is a complex exercise: designers must address multiple interconnected questions at the same time as confronting multiple uncertainties, ranging from the definition of the assessment arguments to the identification of statistical models that can deal with multidimensional and dynamic constructs.
Even more so than in assessments of established domains like reading and mathematics, the defensibility of any decision resulting from test scores crucially depends on early collaborative efforts to establish a solid assessment framework. As pointed out by Mislevy (2013[33]), close collaboration from the beginning of the design process is needed among users of the results (who understand the intended purposes of the assessment), domain experts (who know about the nature and progression in the target skills, the situations in which these skills are used and the behaviours that can be considered as evidence for these skills in these situations), psychometricians (who know about the requirements to achieve defensible reporting metrics), software designers (who build the infrastructure to bring the assessment to life) and user interface (UI) experts (who make sure that the assessment environment is intuitive to navigate). Not even the best and most complete team of designers can get everything right on the first iteration: by necessity, the design must be iterative and build on information collected through observational studies and small-scale validation efforts.
The design of the PISA LDW assessment has followed these principles and used the tools of ECD as described in this chapter. This was possible because more time and resources were available to develop the assessment framework and to undertake multiple design iterations following cognitive laboratories and pilot data collections than in previous PISA assessments. By articulating the complexity of design decisions behind an innovative test such as LDW, this chapter hopes to increase awareness about the fact that technology will deepen what we assess only if we multiply our efforts to learn how to use it within an evidence-centred framework.
References
[9] Arieli-Attali, M. et al. (2019), “The expanded Evidence-Centered Design (e-ECD) for learning and assessment systems: A framework for incorporating learning goals and processes within assessment design”, Frontiers in Psychology, Vol. 10/853, pp. 1-17, https://doi.org/10.3389/fpsyg.2019.00853.
[29] Brennan, K. and M. Resnick (2012), “New frameworks for studying and assessing the development of computational thinking”, Proceedings of the 2012 Annual Meeting of the American Educational Research Association, Vol. 1, http://scratched.gse.harvard.edu/ct/files/AERA2012.pdf (accessed on 27 March 2023).
[8] Briggs, D. et al. (2006), “Diagnostic assessment with ordered multiple-choice items”, Educational Assessment, Vol. 11/1, pp. 33-63, https://doi.org/10.1207/s15326977ea1101_2.
[4] Clark, R. et al. (2008), “Cognitive task analysis”, in Spector J. et al. (eds.), Handbook of Research on Educational Communications and Technology, Macmillan/Gale, New York.
[23] Conati, C. (2002), “Probabilistic assessment of user’s emotions in educational games”, Applied Artificial Intelligence, Vol. 16/7-8, pp. 555-575, https://doi.org/10.1080/08839510290030390.
[26] Connell, M., J. Campione and A. Brown (1988), “Metacognition: On the importance of understanding what you are doing”, in Randall, C. and E. Silver (eds.), Teaching and Assessing Mathematical Problem Solving, National Council of Teachers of Mathematics, Reston.
[19] de Ayala, R. (2009), The Theory and Practice of Item Response Theory, Guilford Press.
[30] de Jong, T., S. Sotiriou and D. Gillet (2014), “Innovations in STEM education: the Go-Lab federation of online labs”, Smart Learning Environments, Vol. 1/1, https://doi.org/10.1186/s40561-014-0003-6.
[32] Jeon, M. and P. De Boeck (2015), “A generalized item response tree model for psychological assessments”, Behavior Research Methods, Vol. 48/3, pp. 1070-1085, https://doi.org/10.3758/s13428-015-0631-y.
[10] Koedinger, K., A. Corbett and C. Perfetti (2012), “The Knowledge-Learning-Instruction framework: Bridging the science-practice chasm to enhance robust student learning”, Cognitive Science, Vol. 36/5, pp. 757-798, https://doi.org/10.1111/j.1551-6709.2012.01245.x.
[22] Levy, R. and R. Mislevy (2004), “Specifying and refining a measurement model for a computer-based interactive assessment”, International Journal of Testing, Vol. 4/4, pp. 333-369, https://doi.org/10.1207/s15327574ijt0404_3.
[12] Luecht, R. (2013), “Assessment Engineering task model maps, task models and templates as a new way to develop and implement test specifications”, Journal of Applied Testing Technology, Vol. 14/4, https://www.testpublishers.org/assets/documents/test%20specifications%20jatt%20special%20issue%2013.pdf.
[27] Maloney, J. et al. (2010), “The Scratch programming language and environment”, ACM Transactions on Computing Education, Vol. 10/4, pp. 1-15, https://doi.org/10.1145/1868358.1868363.
[2] Messick, S. (1994), “Validity of pyschological assessment: Validation of inferences from persons’ responses and performances as scientific inquiry into score meaning”, ETS Research Report Series, Vol. 1994/2, pp. i-28, https://doi.org/10.1002/j.2333-8504.1994.tb01618.x.
[33] Mislevy, R. (2013), “Evidence-centered design for simulation-based assessment”, Military Medicine, Vol. 178/10S, pp. 107-114, https://doi.org/10.7205/milmed-d-13-00213.
[11] Mislevy, R. et al. (2010), “On the roles of external knowledge representations in assessment design”, Journal of Technology, Learning and Assessment, Vol. 8/2, pp. 1-51, http://www.jtla.org.
[18] Mislevy, R. et al. (2012), “Design and discovery in educational assessment: Evidence-centered design, psychometrics, and educational data mining”, Journal of Educational Data Mining, Vol. 4/1, pp. 11-48, https://doi.org/10.5281/zenodo.3554641.
[16] Mislevy, R. et al. (2014), Psychometric Considerations in Game-Based Assessment, GlassLab Research, Institute of Play, http://www.instituteofplay.org/wp-content/uploads/2014/02/GlassLab_GBA1_WhitePaperFull.pdf (accessed on 27 March 2023).
[1] Mislevy, R. and M. Riconscente (2006), “Evidence-centered assessment design”, in Downing, S. and T. Haladyna (eds.), Handbook of Test Development, Lawrence Erlbaum, Mahwah.
[17] Mislevy, R., L. Steinberg and R. Almond (2003), “Focus Article: On the structure of educational assessments”, Measurement: Interdisciplinary Research & Perspective, Vol. 1/1, pp. 3-62, https://doi.org/10.1207/s15366359mea0101_02.
[24] National Research Council (2000), How People Learn, National Academies Press, Washington, D.C., https://doi.org/10.17226/9853.
[31] OECD (forthcoming), The PISA 2025 Learning in the Digital World assessment framework (draft), OECD Publishing, Paris.
[25] Panadero, E. (2017), “A review of self-regulated learning: Six models and four directions for research”, Frontiers in Psychology, Vol. 8/422, pp. 1-28, https://doi.org/10.3389/fpsyg.2017.00422.
[20] Reckase, M. (2009), Multidimensional Item Response Theory, Springer, New York, https://doi.org/10.1007/978-0-387-89976-3.
[21] Rupp, A., J. Templin and R. Henson (2010), Diagnostic Measurement: Theory, Methods, and Applications, Guilford Press, New York.
[13] Scalise, K. and B. Gifford (2006), “Computer-based assessment in e-learning: A framework for constructing “intermediate constraint” questions and tasks for technology platforms”, Journal of Technology, Learning, and Assessment, Vol. 4/6, http://www.jtla.org.
[6] Shute, V., I. Masduki and O. Donmez (2010), “Conceptual framework for modeling, assessing and supporting competencies within game environments”, Technology, Instruction, Cognition and Learning, Vol. 8/2, pp. 137-161.
[14] Shute, V., S. Rahimi and X. Lu (2019), “Supporting learning in educational games: Promises and challenges”, in Díaz, P. et al. (eds.), Learning in a Digital World, Smart Computing and Intelligence Series, Springer, Singapore, https://doi.org/10.1007/978-981-13-8265-9_4.
[5] Toulmin, S. (2003), The Uses of Argument, Cambridge University Press, Cambridge, https://doi.org/10.1017/cbo9780511840005.
[3] Twist, L. and J. Fraillon (2020), “Assessment content development”, in Wagemaker, H. (ed.), Reliability and Validity of International Large-Scale Assessment, IEA Research for Education Series, Springer, Cham, https://doi.org/10.1007/978-3-030-53081-5_4.
[15] Wang, L., V. Shute and G. Moore (2015), “Lessons learned and best practices of stealth assessment”, International Journal of Gaming and Computer-Mediated Simulations, Vol. 7/4, pp. 66-87, https://doi.org/10.4018/ijgcms.2015100104.
[28] Wieman, C., W. Adams and K. Perkins (2008), “PhET: Simulations that enhance learning”, Science, Vol. 322/5902, pp. 682-683, https://doi.org/10.1126/science.1161948.
[7] Wilson, M. (2009), “Measuring progressions: Assessment structures underlying a learning progression”, Journal of Research in Science Teaching, Vol. 46/6, pp. 716-730, https://doi.org/10.1002/tea.20318.