Kathleen Scalise
University of Oregon
Cassandra Malcom
University of Oregon
Errol Kaylor
University of Oregon

Kathleen Scalise
University of Oregon
Cassandra Malcom
University of Oregon
Errol Kaylor
University of Oregon
This chapter explores whether robust analytic techniques are available to generate defensible inferences from complex data generated by digital assessments, including process data. Digital technologies hold great promise for helping to bring about changes in educational measurement and assessment, but one challenge to be faced is how to accumulate different sources of evidence in defensible ways to make inferences when constructs and observations include inherent complexity. This chapter discusses some potential solutions for making measurement inferences at scale using complex data, notably hybrid measurement models that incorporate one measurement model within another. The chapter conceptually draws on an example of a complex task in a technology-rich environment from the OECD Platform for Innovative Learning Assessments (PILA) to highlight this analytical approach.
This chapter addresses some analytical approaches for including complex process and interaction data from technology-based tasks into educational assessments. An intersection is emerging between applications of learning analytics and traditional psychometric approaches to educational measurement (Papamitsiou and Economides, 2014[1]; Scalise, Wilson and Gochyyev, 2021[2]). This emerging intersection may help assessments to tap new technology for analysing and integrating different sources of data reliably in innovative assessments. By establishing some common ground between fields, new approaches called “hybridised” may borrow strength across toolkits to good effect.
When tackling the topic of next-generation analytics for next-generation educational assessment tasks, the first question one might ask is whether new analytical approaches are needed. This is a typical “double-barrelled” question – or even “triple-barrelled.” That is, there are at least three questions involved here: first, is there value in leveraging more complex and richer data in educational assessments available through new technology tools? Secondly, do we still need traditional response data? Finally, are sufficient techniques already available to accumulate the evidence from such tasks and make robust and interpretable inferences? The general consensus of this report regarding the first two questions is “yes”, based on the earlier chapters. We will not explore the first two questions further because they are addressed elsewhere in this report (see Chapters 5, 7 and 12, particularly). Instead, we turn to the third question: Are robust techniques available to generate defensible inferences from such complex content?
Part of the answer depends on what is meant by “defensible” inferences. Over six decades of research in psychometrics and measurement technology for summative assessment has matured to establish well-accepted procedures for important issues, which include calibration and estimation of overall score(s), reliability and precision information, test form creation, linking and equating, adaptive administrations, evaluating assumptions, checking data-model fit, differential functioning and invariance. Much of this is done using well-fitting measurement models. According to Levy (2012[3]) and others, new approaches using more complex and noisier data such as process data are still in their infancy and cannot rely on such procedures to establish validity if they are not well-fitting to measurement models. We will call this the “Levy challenge”.
Chapter 5 of this report argues that information technology provides new opportunities to assess some hard-to-measure 21st Century competencies. Chapter 6 discusses the decisions involved in translating a theoretical model of a complex domain into an operational assessment, including when the domain involves observing dynamic states over time and capturing processes via technology-based simulations. Chapter 7 provides an overview of how information technologies can support scaffolding, feedback and choice while presenting video, audio, agent-based and immersive experiences. All of these information technology advances are very compelling, but a key question remains: has measurement technology evolved far enough to tell us how all these new information technology affordances can generate defensible measurement claims and allow us to make interpretable inferences about respondents or the groups they represent?
While many innovative psychometric models exist that can handle a variety of complexities in measurement, these are often employed in research projects only. Conversely, psychometric models used operationally do not well incorporate complex data (which can include but not be limited to process data). For instance, achieving goals in a serious gaming product or simulation setting may involve complex data such as examining an outcome figure with computer vision. While machine learning (ML)/Artificial Intelligence (AI) engines along with innovative psychometric models have been proposed in research to handle a variety of situations, operational models tend to better handle single dimensions and standardised cross-sectional data better than complex data. Operational models tend to require very robust characteristics at the item level (that is, for a single question or a single observation) and do not work for assessments where different tasks are connected, and examinees’ behaviours can only be interpreted by considering patterns of combined observations. These traditional models therefore often narrow constructs, with those aspects of constructs that are not yet well understood arguably the most vulnerable to inadvertent pruning. Scores or categorisations that are intended to provide evidence for different facets of a construct often are “collapsed” after delivery of an innovative task by combining score categories, with the consequence of obscuring different strategies for reaching the score – highly instructionally-relevant information for teachers and other users of the assessment results. Highly constrained assessments can generate relatively sparse, clean and standardised data for which such models are designed, but these assessments leave limited room for agency, adaptivity, cultural relevance, maker culture, collaboration or other potentially desirable aspects of student performance.
Such issues related to accumulating complex bits of evidence to make valid and defensible inferences suggest that existing analytic approaches are unlikely to be the next-generation models needed for large-scale summative assessments without some degree of revision and update. Although we argue elsewhere (see Chapter 13 of this report) that much work remains to bridge the broader fields of learning analytics and psychometrics to develop innovative measurement solutions, we summarise here a few directions of possible solutions for the technology-enhanced realm:
Borrowing strength from each other directly within the analytic techniques, for example incorporating one measurement model within another or using one model to extend another. We describe this approach in more detail later in the chapter.
Establishing multiple inferential grain sizes, for example designing a task to report out at different grain sizes for different purposes. The results from different analyses should be triangulated to ensure that there is consistency in the overall communication about students’ proficiency.
Drawing on stronger confirmatory data from improved domain modelling and analysis, for example drawing on strong theoretical research about learning patterns to design a task and then collecting data, analysing and then revising tasks and constructs iteratively based on findings as more data are gathered (see also Chapter 6 of this report). This approach contrasts with “dropping” more complex tasks that don’t fit as well as more traditional ones after field trial testing, for instance – although it does require more flexible budgets and timelines for test development.
Using a richer range of exploratory data to explain more variance, which can be done in a variety of ways such as including process data. However, such results may originate a theory through data mining rather than confirming one with a designed experience based on research, such as described in the first and third bullet points. If data mining is intended to generate a metric, it implies a couple of different commitments. Initial results – even if at scale – need to be interpreted cautiously, even though this flies in the face of making large claims to gain funding and support for projects. This therefore interacts with assessment literacy about the use of evidence (i.e. will the information, once available, be employed cautiously?). It also implies a commitment to investing considerable resources over time, ultimately converting from an exploratory to a confirmatory position with additional data sets and a clear interpretation.
Functioning with much more (and noisier) data by attempting to use different types of technology-enhanced tasks to measure the same construct. This may reduce validity issues related to results being dependent on the technology presented in the task; however, it becomes an empirical question of whether a generalisable trait is being tapped across tasks. Technology-based tasks can generate a big data stream, but it is often unclear in what ways the data are “contaminated” with construct-irrelevant variance. Typically, this is resolved by making inferences only over a body of different tasks, observations or questions rather than depending too much on one type – but this often implies a willingness to accept somewhat noisier tasks (or in formal measurement language, noisier testlets). Even when very carefully designed, individual tasks or testlets in such assessments tend to pick up on at least some constructs not being measured, including format effects, the context, passage, phenomena or other non-standardised elements. Trying to discard unique variance from technology tasks to solve this in a simple statistical adjustment, such as with bivariate models or even testlet models, also can discard salient variance unique to that task. To avoid this, the assessment blueprint needs duplicate tasks on the same standards, blocks of individual independent questions and good attention to testlet effect reduction. These requirements may mean time is too restricted to meet the evidentiary need if only large-scale assessments with relatively short testing times are used for inferences, as compared to inferences from well-developed systems of assessment such as multiple assessments designed to aggregate effectively together that are less constrained by time.
To find a measurement solution for innovative tasks that generate complex data, the first step is to broadly understand the measurement challenges your types of innovation will face. To discover this, the key elements of an innovative task can be mapped into a conceptual space that can help describe it for measurement purposes. A taxonomy of five conceptual elements has been released (Table 8.1), based on examining several use cases from different types of assessments (Scalise, Wilson and Gochyyev, 2021[2]). The framework is expected to evolve and be revised over time as more use cases are examined.
Notes: * Categories C and D differ as C does not align observations transparently (e.g. to a declared framework). Both use purposefully designed data rather than “found” process data not designed for the assessment purpose (e.g. social media “likes” for deducing attitudinal constructs).
** Data validation checks are when the software prompts the user to confirm their choice.
*** Overall, this refers to how much agency the user has in terms of personal choices. When the assessment developer (Category A) or computer algorithm (Category B) entirely select the content, these are lower on the spectrum of choice. Although Category B uses data based on the individual to adapt the assessment, it does not give personal choice; when the user is allowed some choice (Category C) this is considered higher on this spectrum. Full choice (Category D) is highest for this element. Recall that lower does not necessarily imply a value judgement in this taxonomy but rather describes a purpose and potentially a need for how to accumulate the evidence effectively to make an inference.
Source: Adapted from Scalise et al. (2021[2]), updated in elements 3B-C with information derived from the PILA use case.
To illustrate how this taxonomy helps to identify measurement challenges, we apply it to an assessment of computational problem solving that has recently been developed by the OECD for its Platform for Innovative Learning assessments (PILA, https://pilaproject.org/). One PILA application (Karel) involves block-based programming of a virtual robot, “Karel”, to execute actions in a grid-based environment (see Figure 8.1). Karel understands a few basic instructions such as moving forward, turning left and picking up stones, and a tutorial explains to students how to program these basic movements using the block coding language. In a typical assessment activity in PILA, students complete a set of tasks that is either assembled by their teacher or by a researcher. Within the body of work selected, the student can decide how much time to dedicate to each task and (in some cases) which task they want to complete first in the sequence. This introduces measurement challenges but also allows the PILA assessments to have high agency for the learning context. This may relate to whether relevance and intrinsic motivation are perceived by the user when engaging in the tasks, especially within the naturalistic setting. Self-directed learning is also part of the framework being addressed with such tasks.
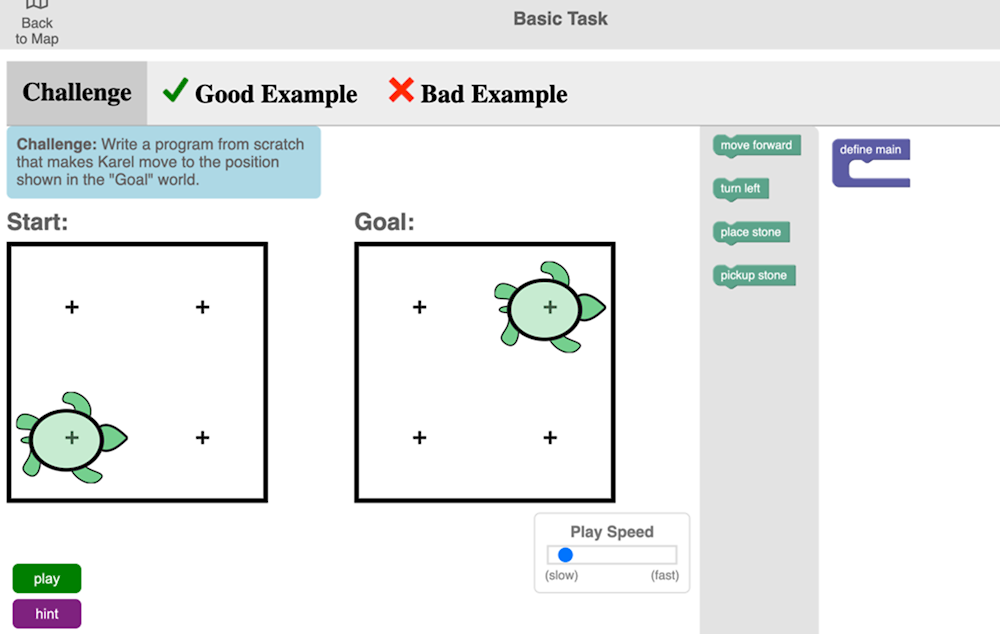
Source: OECD (n.d.[4]), OECD’s Platform for Innovative Learning Assessments (PILA), https://pilaproject.org/.
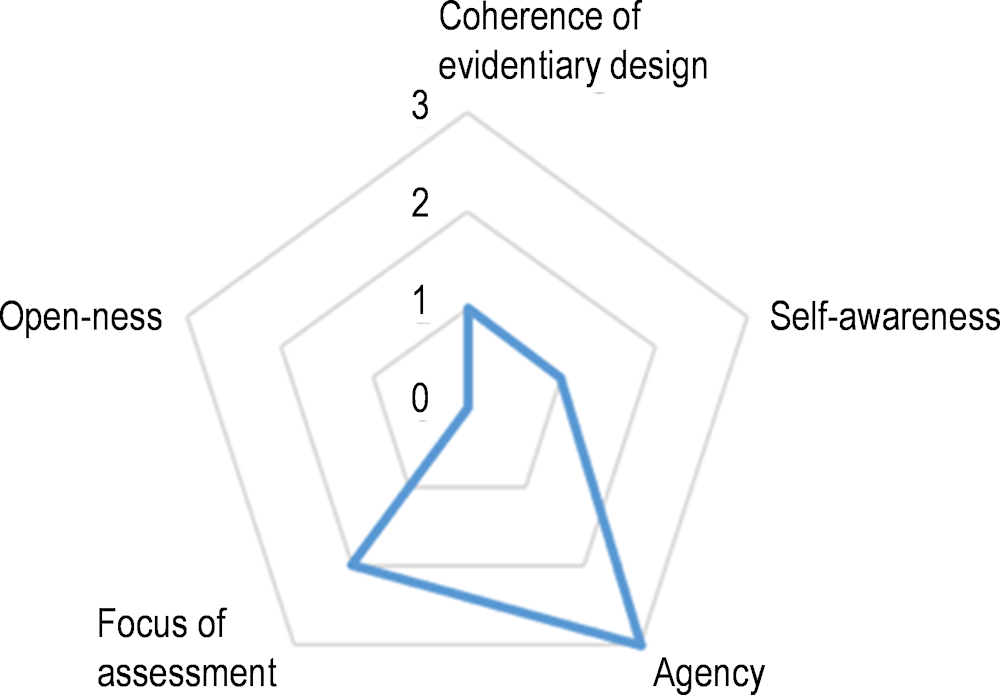
Using the five conceptual elements described in Table 8.1, the radar plot below (see Figure 8.2) illustrates where the original PILA Karel task fell in this conceptual space at the time reviewed. Note that where a task falls in the conceptual space described in Table 8.1 is not intended as a value judgement: good activities might potentially fall anywhere in the space and still offer useful evidence, but different parts of the space involve different challenges for making measurement claims. For instance, a task high in agency (such as the PILA Karel task), often considered a valuable trait by learning scientists, means the student self-selects many choices in how the task plays out. They can decide, for example, to consult a worked example or access a hint at any point in the task. This agency provides opportunities to measure self-regulated learning, which is a measurement target across all PILA activities. However, such choices may make evidence streams more or less different between respondents, and this poses measurement challenges for comparability.
In the remainder of this chapter, we elaborate on the approach “borrowing strength across models to effectively aggregate evidence” as a possible solution to some of the measurement challenges discussed in the context of complex, interactive and innovative tasks. Since results can be examined for robust traits, this approach has become a common suggestion for complex technology-based experiences that want to make measurement claims. An AI group in Hong Kong, for instance, recently advocated for “Deep-IRT” (Yeung, 2019[5]):
“We propose Deep-IRT which is a synthesis of the item response theory (IRT) model and a knowledge tracing model that is based on the deep neural network architecture called dynamic key-value memory network (DKVMN) to make deep learning based knowledge tracing explainable. Specifically, we use the DKVMN model to process the student’s learning trajectory and estimate the item difficulty level and the student ability over time. Then, we use the IRT model to estimate the probability that a student will answer an item correctly using the estimated student ability and the item difficulty. Experiments show that the Deep-IRT model retains the performance of the DKVMN model, while it provides a direct psychological interpretation of both students and items.”
Such an approach is an example of a nested or hybridised measurement model. In this case, first an ML/AI model is used to process a complex learning trajectory, then an overarching IRT model is applied for interpretation. Looked at from this perspective, many types of ML/AI or other accumulation techniques that yield ordered or even nominal ways of valuing performances over a set of complex observables could yield evidence for a hybridised measurement model. For instance, scores from many “scoring engines” used in large-scale assessment already implicitly employ such a type of hybridisation. In two phases, scores are generated by machine learning of essays, for instance, then accumulated with psychometric models to make inferences along with other data on language constructs of interest. Many examples of scoring engines exist in other fields too, such as computer science.
The Harvard Virtual Performance Assessment (VPA) is an immersive virtual environment with the look and feel of a videogame. In the task “There’s a New Frog in Town” (New Frog), each participant participates as an avatar that can move around the virtual environment. The reporting goals of the assessment were multidimensional and involved scientific exploration and inquiry (as reflected in science standards at the time).
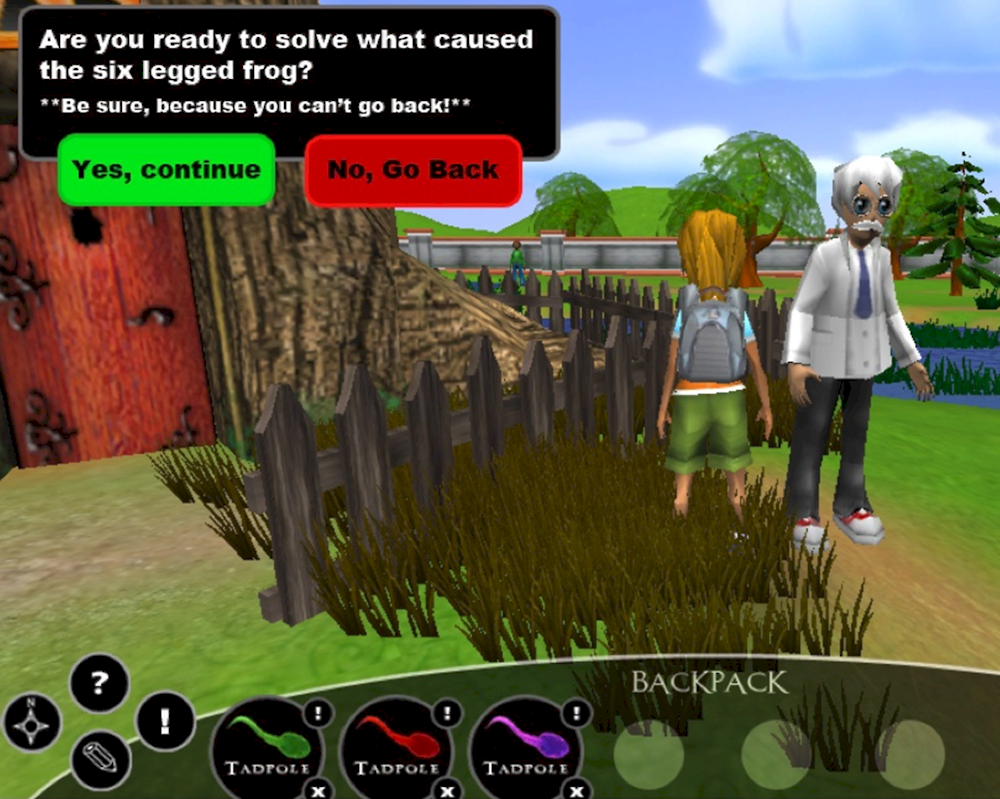
Source: Scalise and Clarke-Midura (2018[6]), originally accessed at http://vpa.gse.harvard.edu/.
In New Frog, examinees were asked to explore the problem of a frog with six legs. They could choose to examine different frogs to investigate the problem, whereby the choice in itself was neither right nor wrong (so, this was not a typical “item” with a keyable answer). However, patterns over the type and number of frogs examined (e.g. those located at different farms, along with water samples from the farms) were deemed construct salient information and these patterns could be represented in a small but informative Bayes’ net.
The Bayes net accumulation added considerable information to the IRT model, showed acceptable fit to the patterns of the naturalistic task and resulted in a reduction of the standard error of measurement (Scalise and Clarke‐Midura, 2018[6]). In fact, the scores generated by the two Bayes subnets proved to be among the three most informative “items” in the task in terms of the model’s fit in the study, despite being designed from data that was originally discarded. This is not terribly surprising given that the score was a pattern over salient observations, but the other most informative item was a significantly more expensive human-rated constructed response item. Note that the cost of reliably hand scoring constructed responses is often the white elephant in the room for costs of large-scale assessment. Overall, a finer grain-size of inference was made possible on the task without additional testing time or scoring resources, and the strengths of low performing students in conducting inquiry were more evident.
Learning tasks that also gather assessment evidence often employ Bayes Nets in scoring engines, which are highly flexible and easy to use. When content experts create naturalistic authentic technology tasks, such as simulations or serious gaming, they almost always incorporate many activities intended to frame small experiences that are easily described in a small Bayes’ net. Small Bayes’ nets are easy to define and to generate scores, assuming tasks have sufficient “left over” data considered salient to the construct but not yet connected together to incorporate in a formal scoring model.
One hybridised model that has appeared is mIRT-bayes (Scalise, 2017[7]). It employs small Bayesian networks to help score over rich patterns of evidence, then uses a multidimensional IRT (mIRT) model to accumulate scores and yield inferences. In mIRT-bayes, the overarching IRT model can be uni- or multidimensional and will yield the solution needed to meet the “Levy challenges” at large scale. Applied originally to simulation-based data from Harvard’s Virtual Performance Assessments (VPA) (Dede, Clarke-Midura and Scalise, 2013[8]), mIRT-bayes was examined across two VPA tasks with similar results (see Box 8.1).
Although estimating the model all at once (one phase) is mathematically possible for mIRT-bayes, the two phases intentionally offer modularity. This preserves the flexibility of Bayes Nets for task design while retaining the robust statistical properties of latent variable methods for accumulation and inferences. In a modular approach, changes to the tasks are easier. If Bayes Nets are described during task development (i.e. before data collection), it can help task designers think about how to revise tasks to elicit the needed evidence. Change can also involve simply keeping and dropping scores, a well-known procedure in educational measurement, or applying simple treatments to scores without revising full analytic models
We exemplify a possible use of mIRT-bayes in the PILA Karel task presented in Figure 8.1. The draft scoring rubric for the task assigns credit for using control flow structures (loops and conditionals) to address repeating patterns in code. High performance for the age group involves solving a complex problem by writing nested repetition(s) of commands. Whether or not respondents can finally generate this type of code is revealed by the end product, which can be scored for “correctness”. The product might be scored acceptable or not or might be given credit for partial solutions with a polytomous rubric. However, scoring only the final work product ignores considerable construct-relevant information in the process data, or interactions in which respondents engage.
For this task, process data is deemed salient by learning scientists in many screens of the PILA activity. Usually learning scientists who are experts in a given area have been selected to design a task because they can describe their ideas of what salient actions are. In other words, they often hold an implicit theory for why they designed the task as they did. Descriptions of Bayes subnets generally start with this theory. Alternatively, or to further develop implicit theories, data sets can reveal interesting patterns to improve nets. This is not unique to Bayes and is also true of other cluster and AI/ML techniques.
Because the PILA tasks allow considerable agency and incorporate a great deal of complexity through a naturalistic flow, many single actions taken by a respondent can’t be expected to say much alone but may be deemed salient over a group of observables. From a measurement perspective, these groups of observations are known as “semi-amorphous” data. These data are also “semi-structured” from a computer science perspective since the observations to be captured are tagged in the data collection file and can be parsed but are not valued with a score.
With semi-amorphous data, trying to accumulate individual actions directly within an IRT model is often a validity threat. If only sequences or patterns over the actions are salient, each individual action alone is not salient – in other words, other equally meaningful actions could have been taken. Stakeholders often rightly reject the approach of trying to make claims on individual actions and patterns can be hard to evaluate without models to help with the process. However, if larger patterns of actions are deemed meaningful by the learning scientists designing the tasks, then this information should be relevant to accumulate and might be included in an IRT model for reporting if a score for the pattern is used and models can be shown to fit. This is what hybrid models (like Deep-IRT or mIRT-bayes) are intended to accomplish. Patterns of salient actions can be identified before data collection (from theory), or after data collection if the necessary data are tagged in the software and can be parsed (i.e. semi-structured). If a pattern is identified afterward rather than from theory, then results can be considered exploratory and should be subjected to expert identification and confirmation with subsequent data sets.
Table 8.2 describes the construct-relevant information available in the PILA Karel task. For the example discussed, relevant information that might be used as traditional “item” scores in a hybridised model include success in generating a simple loop and success in extending the simple loop to a nested loop. However, some patterns to be scored on this construct are not this simple. For example, one high level of the rubric on the nested loop goal requires adapting control flow structures to generalise across multiple problems. Salient semi-amorphous information from process data might include whether available examples were accessed, whether the hint was accessed, the degree and type of prior flawed attempts to generate both simple and nested loops, and whether feedback was viewed with indicators such as NT10. The NT10 metric describes whether students took enough time to use the information and is an indicator of test effort (Wise et al., 2004[9]). In this case, it might reveal extremes of insufficient time allotted to use feedback.
Note: y=yes, n=no.
An example Bayes subnet showing a simple theoretical relationship for a few of the nodes from Table 8.2 for the PILA Karel task is shown in Figure 8.4. A subnet is a small part of a Bayes net that generates a score over a pattern as an “estimate”. Often it is possible to identify several subnets to expand salient evidence used from a complex task. Theoretical ideas for how the nodes might be connected in a Bayes subnet for Figure 8.4 were based on information in the description of the task and conversations about implicit theories for how the task was designed. The elements within the subnet are labelled as follows:
“GE” for good example accessed (yes/no);
“BE” for bad example accessed (yes/no);
“hint” for hint accessed (yes/no);
“run” for prior run with incorrect use of nested block (yes/no);
“NT10”, a flag discussed earlier for insufficient test effort based on time taken compared to normative time (0/1, if less than 10 percent of the normative time);
“type”, a set of strategies identified a priori by learning scientists coded as to which ones the student tried; and
“lo”, a flag for the total number of prior runs without the nested block (0/1).
This subnet could be applied to parsed process data on the first nested loop challenge in the PILA Karel task. The data set can be used to determine the full joint probability and query individual estimates for the subnet.
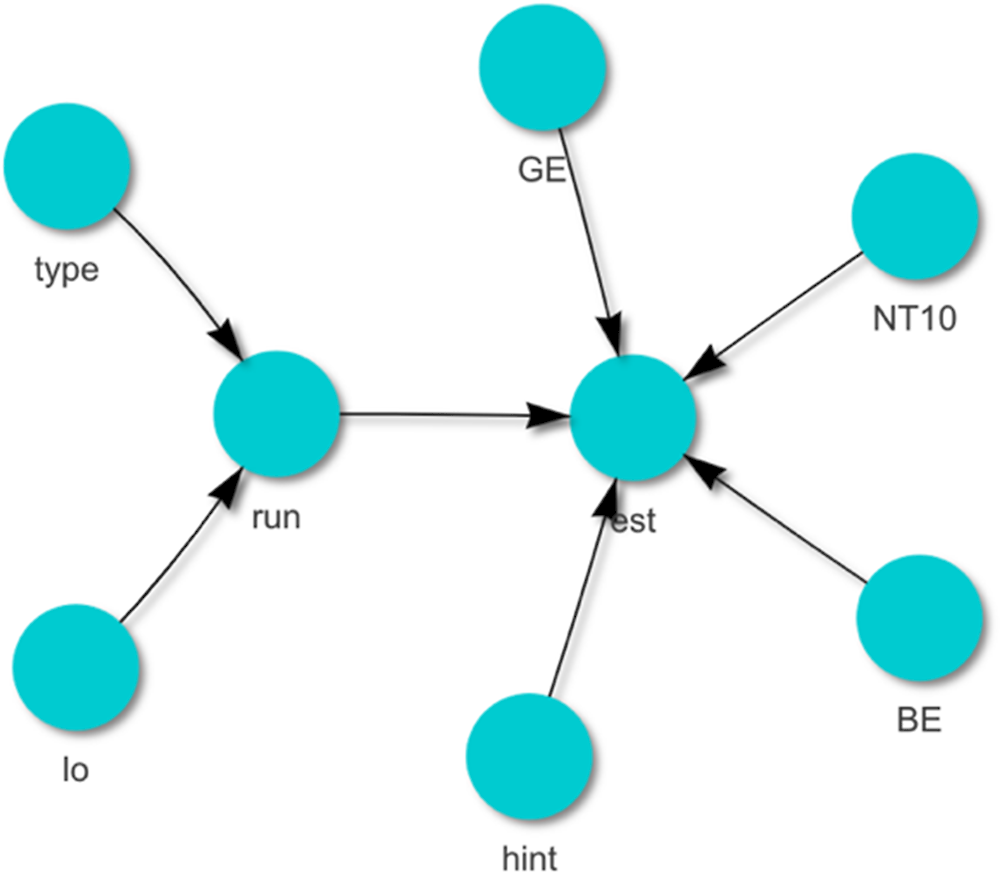
Source: Diagram generated through the R Bayes Net package bnlearn (Scutari, 2010[10]).
To illustrate how implicit theories can evolve into questions for data mining, there are several questions involving the “run” node of the subnet. Currently the run node is shown conditioned on the type (“type”) and number (“lo”) node parents shown in Figure 8.4. Based on the eventual data, do the node parents provide helpful information or is the dichotomised “run” node alone enough? If “lo” is informative, should we maintain intervals (e.g. 0, 1, 2, 3, 4+) or can we dichotomise to low and high? If so, where is the most informative location for the cut point? Another question relates to the “type” node: can we categorise the student exemplars of prior runs without a nested block into a set of meaningful types? In order to answer these questions, we need to examine the results in the data set and likely also consult with the task’s learning scientist developers to see if they observe patterns in the results.
Data sets are not yet available for PILA tasks but are expected to be used soon to explore if this subnet configuration is informative or if other configurations might better fit, as well as to investigate other possible subnets. This approach blends theory with data mining. Ultimately multiple data sets will be available in PILA so we also intend to compare the utility of different clustering algorithms within the mIRT model. This can help us say whether Bayes subnets are most useful or if another emerging clustering algorithm might be useful.
Such embedded model comparisons through OECD-sponsored innovations in learning assessments represent an important opportunity for innovation. For the moment, IRT itself seems a given within the context of large-scale assessment due to its ability to meet the “Levy challenges” discussed earlier. For PILA, mIRT is a suggested approach given the intended multidimensional nature of the draft framework. Recently, engines have also been developed that derive Bayes Nets automatically from task data sets and “discover” subnets that may provide additional information to a measurement model. Such subnets would still need to be reviewed for saliency by learning scientists, but this automated approach to hybridising models also poses interesting possibilities.
Digital technologies hold promise for helping to bring about changes in educational measurement and assessment. As described in the Introduction chapter of this report, one challenge to be faced is how to accumulate evidence in defensible ways when constructs and observations include inherent complexity. Several different approaches have been discussed and an example developed.
We argue that viable approaches should propose a set of potential solutions to the dilemmas described in this chapter. We have shown there is space to consider change and we have exemplified some approaches – but we do not intend to specify what form such change should take. We have illustrated using a PILA example for an approach to hybridise models by borrowing strength across different emerging and traditional methods. Hybrid models may flexibly accumulate patterns of evidence and generate scores using ML/AI approaches such as Bayes Nets or more current clustering algorithms, while preserving an overarching IRT model to meet the “Levy challenges”. Such innovations might help not only to empower the use of technology affordances discussed in earlier chapters of this report, but also could generate important advances in measurement technologies for hard-to-measure constructs and novel, engaging activities for students.
[8] Dede, C., J. Clarke-Midura and K. Scalise (2013), “Virtual performance assessment and games: Potential as learning and assessment tools”, in Paper presented at the Invitational Research Symposium on Science Assessment, Washington, D.C..
[3] Levy, R. (2012), “Psychometric advances, opportunities, and challenges for simulation-based assessment”, Invitational Research Symposium on Technology Enhanced Assessments, ETS, Washington, D.C., https://www.ets.org/Media/Research/pdf/session2-levy-paper-tea2012.pdf.
[4] OECD (n.d.), Platform for Innovative Learning Assessments, https://pilaproject.org/ (accessed on 3 April 2023).
[1] Papamitsiou, Z. and A. Economides (2014), “Learning analytics and educational data mining in practice: A systemic literature review of empirical evidence”, Educational Technology and Society, Vol. 17/4, pp. 49-64.
[7] Scalise, K. (2017), “Hybrid measurement models for technology-enhanced assessments through mIRT-bayes”, International Journal of Statistics and Probability, Vol. 6/3, pp. 168-182, https://doi.org/10.5539/ijsp.v6n3p168.
[6] Scalise, K. and J. Clarke‐Midura (2018), “The many faces of scientific inquiry: Effectively measuring what students do and not only what they say”, Journal of Research in Science Teaching, Vol. 55/10, pp. 1469-1496, https://doi.org/10.1002/tea.21464.
[2] Scalise, K., M. Wilson and P. Gochyyev (2021), “A taxonomy of critical dimensions at the intersection of learning analytics and educational measurement”, Frontiers in Education, Vol. 6, https://doi.org/10.3389/feduc.2021.656525.
[10] Scutari, M. (2010), “Learning Bayesian Networks with the bnlearn R package”, Journal of Statistical Software, Vol. 35/3, https://doi.org/10.18637/jss.v035.i03.
[9] Wise, S. et al. (2004), “An investigation of motivation filtering in a statewide achievement testing program”, in Paper presented at the Annual Meeting of the National Council on Measurement in Education, San Diego, California.
[5] Yeung, C. (2019), “Deep-IRT: Make deep learning based knowledge tracing explainable using item response theory”, in EDM 2019 - Proceedings of the 12th International Conference on Educational Data Mining, Montréal, Canada, https://doi.org/10.48550/arXiv.1904.11738.