The aim of the work is to compile distributional estimates of household income, consumption and saving consistent with national accounts totals. This chapter describes the underlying conceptual framework, focusing on the target population, the unit of analysis, the income and consumption concepts, and the household groupings and accompanying socio-demographic information targeted in the work.
OECD Handbook on the Compilation of Household Distributional Results on Income, Consumption and Saving in Line with National Accounts Totals

2. Conceptual framework
Abstract
2.1. Introduction
This chapter describes the conceptual framework underlying the compilation of distributional results on household income, consumption and saving consistent with national accounts. It starts with describing how the work fits within the System of National Accounts (SNA) in Section 2.2, focusing on the position of the household sector in this framework and presenting the specific accounts covering income, consumption and saving. Then, Section 2.3 discusses the delineation of the target population in relation to the household sector as described in the SNA and defining the units of observation and analysis as used in the compilation of distributional results. Subsequently, Section 2.4 provides an overview of the various income and consumption components included in the compilation of the distributional results, also showing how saving results can be derived on the basis of this information. The chapter then discusses various breakdowns that can be used to present data for more detailed household groups in Section 2.5. This is followed by a description of socio-demographic information that can be published together with the distributional information to provide more insight in the composition of the various household groups in Section 2.6. The chapter concludes with an overview of the main templates for compiling distributional results, based on this conceptual framework, in Section 2.7.
2.2. The position of the work in the System of National Accounts
The aim of the work is to arrive at distributional results on household income, consumption and saving in line with national accounts concepts and totals. This means that the information on income, consumption and saving as described in the system of national accounts for the household sector provides the starting point for the distributional results.
The System of National Accounts (European Commission et al., 2009[1]) (hereinafter referred to as 2008 SNA) provides a comprehensive and consistent overview of all economic activities and positions in a country. The information is presented as a sequence of accounts focusing on the various aspects of the economy (such as production, generation and re-distribution of income, consumption of goods and services, and the accumulation of assets and liabilities), also including balance sheets on the stocks of assets and liabilities at the start and the end of a recording period. Results are presented for the economy as a whole as well as for the main sectors and subsectors in the economy. These sectors are defined on the basis of similar kind of activities, with non-financial corporations, financial corporations, general government, households and non-profit institutions serving households constituting the main sectors. Furthermore, the system describes all transactions with non-resident entities, presented in the rest-of-the-world account, to arrive at a fully consistent framework.
The system reflects each transaction and position from the perspective of both parties involved and uses a quadruple-accounting system. This means that a counterpart entry is recorded in the financial accounts for each income or capital transaction recorded in the current or capital account and for each purchase/sale of a financial asset or incurrence/repayment of a liability in the financial account. This ensures that the system is always consistent, adding to the reliability and the usefulness of the results.
As explained above, the results are presented as a sequence of accounts, including balance sheets that record stocks of assets and liabilities at the start and the end of a recording period. Figure 2.1 provides a schematic overview of the main accounts distinguished in the system, broken down into the main sectors in the economy, also showing flows and positions vis-à-vis the rest-of-the world.
As presented in the figure, the sequence of accounts can be broken down into current and accumulation accounts. The current accounts provide information on production, income generated by production, the subsequent distribution and redistribution of incomes, and the use of income for consumption and saving purposes. These all relate to the upper part of the figure. The accumulation accounts record flows that affect the balance sheets and consist of the capital and the financial account, which primarily record transactions and the other changes in assets account. Together these accounts represent the changes in the stock accounts or balance sheets. All of this is presented in the lower part of the figure.
Ideally, distributional results are available for the full set of accounts for the household sector, including their balance sheets, as this would provide a comprehensive overview of the distribution of the various types of resources available to households. For this reason, the 2008 SNA also discusses sub-sectoring of the household sector in paragraphs 4.158 to 4.165. Furthermore, it would provide the opportunity to cross-check the consistency of the data at the level of the various household groups, confronting information on saving as derived from income and consumption with saving as derived from the accumulation accounts.
For now, the focus of the work has been on compiling distributional results on income, consumption and saving (i.e. the upper part of Figure 2.1), focusing on the allocation of primary income account, the secondary distribution of income account, the redistribution of income in kind account, and the use of disposable and of adjusted disposable income account. The decision to exclude wealth (i.e. the capital, the financial, the other changes in the volume of assets, and the revaluation accounts as well as the balance sheets) from the work up until now was mainly related to pragmatic considerations. However, the OECD launched a new expert group early 2023, to start developing templates and methodology for the compilation of distributional information on wealth, with the aim of having regular distributional results at decile level by the end of 2026 (see also Section 1.4).
In addition to the sequence of accounts as described above, the system of national accounts includes other accounts and tables that may present information in alternative ways or that may provide more detailed information on specific aspects of the economy. With regard to the compilation of distributional results on consumption, the supply-and-use tables contain very relevant information. Whereas the supply table records the supply of goods and services in an economy on the basis of domestic production and imports, the use table focuses on the use of these goods and services, either as input in the production process (i.e. intermediate consumption) or as final use, broken down into consumption, gross capital formation and exports. This means that the use table contains information on consumption of goods and services at very granular levels of detail. Although this detailed information may not always perfectly match the total consumption of resident households of these goods and services (see Section 2.4.2 for more information), it provides a good starting point in deriving distributional results on household consumption.
2.3. Delineation of the population
The household sector as defined in the SNA is the starting point for the compilation of distributional results. In the SNA, a household is defined as a group of persons who share the same living accommodation, pool some, or all, of their income and wealth, and consume certain types of goods (mainly housing and food) and services collectively (see 2008 SNA, §4.149). In general, each member of a household has some claim upon the collective resources of the household and some influence on the decisions affecting consumption or other economic activities. For these reasons, the household is regarded as institutional unit in the SNA, even though income is usually received by the individual, and the household is used as the unit of observation in compiling distributional results. Correspondingly, the Canberra Group (United Nations Economic Commission for Europe, 2011[2]) and the OECD Framework for statistics on the distribution of income, consumption and wealth (OECD, 2013[3]) also recommend focusing on the household in analysing economic well-being and its distribution.
Figure 2.1. Sequence of accounts in the system of national accounts
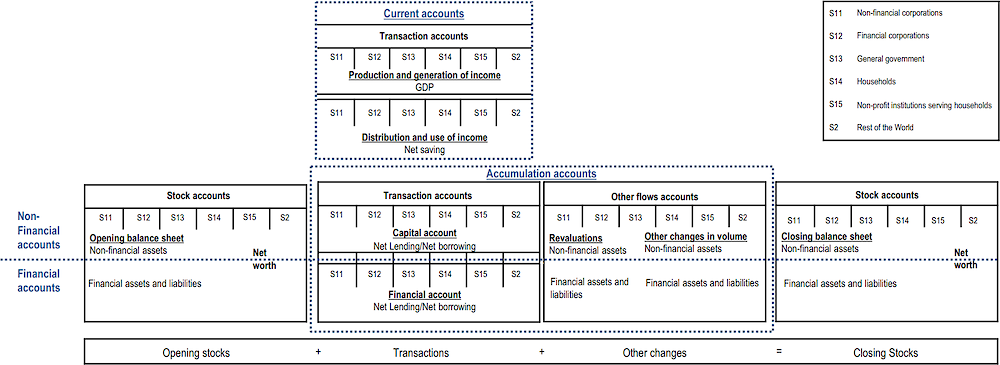
Source: Van de Ven and Fano (2017[4]).
Whereas the household constitutes the unit of observation in compiling distributional results, it has to be borne in mind that households may differ in size and composition, and consequently may have different consumption needs. An income level of 3 000 euros per month for a single person household is not comparable with an income level of 3 000 euros for a household consisting of two adults and three children living at home. Therefore, in analysing data at the household level, it is recommended to focus on so-called “equivalised” results to arrive at comparable figures across households. Equivalence scales are used that take into account differences in size and composition of households, recalculating results according to the number of consumption units in each household. A value is assigned to each household type in proportion to its needs, depending on its size and composition. Due to economies of scale (in particular the sharing of dwellings), the per capita requirements of larger households are lower than those of smaller households to achieve the same levels of economic well-being.
For the purpose of this study, the OECD-modified equivalence scale is used as reference method. Accordingly, the first adult1 counts as 1 consumption unit, any additional persons aged 14 and over count as 0.5 while all children under 14 count as 0.3. However, as the most appropriate scale may depend on specific national circumstances, countries may also look for more appropriate equivalence scales to apply in deriving distributional results. Box 2.1 provides more information on the use of equivalence scales.
Not all households included in the household sector are within the scope of the work. The household sector in the SNA includes both private and institutional households. The latter concern persons living permanently in an institution or who may be expected to reside in an institution for a very long, or indefinite, period of time, with little or no autonomy of action or decision in economic matters. Examples are people living in prison, boarding schools, retirement homes, hospitals, nursing homes and religious institutions (see 2008 SNA, §4.152). These types of households may comprise large groups of individuals with very different socio-demographic backgrounds, who are not related, and who may have very different income and consumption patterns. As a consequence, they behave differently from private households and their (equivalised) results are not really comparable. Whereas it may be assumed that people in a private household have similar levels of economic well-being, this may often not be the case for people living in institutional households. For that reason, it is recommended to exclude them from the compilation of household distributional results, and to present and analyse results for this category separately.2 Their inclusion would lead to heterogeneous results which may have a distorting effect on distributional analyses.
In addition to institutional households, micro statistics may also exclude some other types of households, such as people living in overseas or sparsely populated areas, persons with no usual place of residence, or persons illegally residing in the country. The main reason is that these people are usually hard to capture in micro statistics. However, as they are part of the target population and are assumed to be comparable with other private households, they are taken into consideration in the DNA work. Omitting them would not provide an accurate picture of inequality in an economy.
In delineating the household sector, it is also important to note how the SNA deals with unincorporated enterprises owned by households. This concerns enterprises that are owned by households and for which it is not possible to separate the assets into those that belong to the household in its capacity as a consumer from those belonging to the household in its capacity as producer (see 2008 SNA, §4.155-4.157). As a consequence, they are consolidated in the household sector in the national accounts. The SNA explains that these unincorporated enterprises can relate to all kinds of productive activities, ranging from agriculture, mining, manufacturing, construction, to retail distribution, and that it may concern single persons working as street traders or shoe cleaners to large manufacturing, construction or service enterprises with many employees.
Box 2.1. The use of equivalence scales in analysing household results
Equivalence scales are often used in distributional analyses to arrive at comparable results across households. These scales take into account that consumption needs of a household will increase with each additional household member, but not in a proportional way due to economies of scale. A value is assigned to each additional household member in proportion to its needs, often depending on their age, but possibly also taking into account other socio-demographic characteristics, such as sex, level of income, labour force status and home ownership. It may also depend on the specific delineation of the income or consumption measure that is analysed. For example, if it includes social transfers in kind, this may require a somewhat different assignment of number of consumption units to the individual household members than when these transfers are excluded. Furthermore, it may depend on the composition of consumption expenditure of various households. Equivalence scales that are appropriate for lower income households may be less appropriate for higher income households due to different consumption patterns. For that reason, equivalence scales may differ across countries, as well as within a country for households with different socio-demographic characteristics (see Radner (1994[5])) for more information).
As it is virtually impossible to derive equivalence scales that take into account all the relevant underlying factors, distributional studies often apply a simplified scale. Although this may have some caveats, it ensures consistency and transparency towards users, and also facilitates the assessment of the impact of the equivalence scale on the results. For the purpose of the DNA work, the OECD-modified equivalence scale has been chosen as reference method. Accordingly, the first adult counts as 1 consumption unit, any additional persons aged 14 and over count as 0.5 while all children under 14 count as 0.3. This means that the number of consumption units is derived according to the following formula:
Household income and consumption are divided by the sum of consumption units to obtain a comparable measure across households.
The OECD-modified scale is only one of the possible scales that can be applied. As the most appropriate scale may depend on specific circumstances, countries may look for more appropriate equivalence scales to apply in deriving distributional results. The most important issue is that compilers are transparent about the equivalence scale used and the impact on the results. In that regard, it is recommended to publish information on the number of consumption units and the number of households together with the distributional results.
As was explained, most distributional analyses focus on equivalized results. However, the DINA project (see Section 1.3) applies a slightly different approach. In this project, the unit of observation is the individual, and results are compiled on the basis of equal split income series and individualistic series. Whereas the individualistic series focus on the actual income earned by that specific individual, the equal split series distributes the income between the adult household members. In that sense, it can be regarded as a specific application of the equivalence scale. However, where equivalence scales usually take into account economies of scale from belonging to the same household, the DINA project derives the income of the relevant individuals as a simple average of the sum of their incomes, implicitly assigning a value of 1.0 to each additional adult household member. Moreover, it does not take into account any additional consumption needs that may result from children belonging to the household. It is clear that this will lead to different numbers of consumption units for multi-person households, also affecting the distributional results and inequality measures (see Zwijnenburg (2017[6]) for more information).
In practice, it turns out to be rather difficult to come up with a clear set of criteria to describe and delineate unincorporated enterprises. Often the legal status is applied to determine whether an entity qualifies as an unincorporated enterprise. Another criterion that is often applied relates to the number of employees, but in practice other criteria may be applied as well. The difficulty in clearly defining unincorporated enterprises means that the delineation may differ across countries and that the treatment in the national accounts may differ from the treatment in micro statistics. In that regard, the Canberra Group explicitly excludes unincorporated enterprises from the definition of the household sector. As will be discussed in Chapter 7, it is important to take note of any differences in the treatment of unincorporated enterprises in aligning micro data to the national accounts totals, as they may be responsible for large gaps between the micro and the national accounts totals.
2.4. Defining Income, Consumption and Saving
The aim of the work is to derive distributional results for income, consumption and saving according to the national accounts. Figure 2.2 provides an overview of the link between these aggregates in the system of national accounts. The left-hand side of the overview presents household income, broken down into various underlying items respectively adding up to primary income, disposable income and adjusted disposable income. The latter is the most comprehensive measure of income which is the main measure used in the DNA work for analysing income inequality. However, for policy purposes it may also be of interest to look at inequality according to primary income3 and disposable income. Household consumption is presented on the right-hand side which can be broken down into final consumption expenditure and actual final consumption. The bottom of the overview shows how household saving can be derived on the basis of these results. For that purpose, an additional item is introduced to adjust for the change in pension entitlements related to pension contributions and benefits. This adjustment is needed to reflect that changes in pension entitlements are included in the income measures but are also regarded as part of households’ (dis)saving (see Section 11.16 for more information).
Figure 2.2. Income, consumption and saving in national accounts
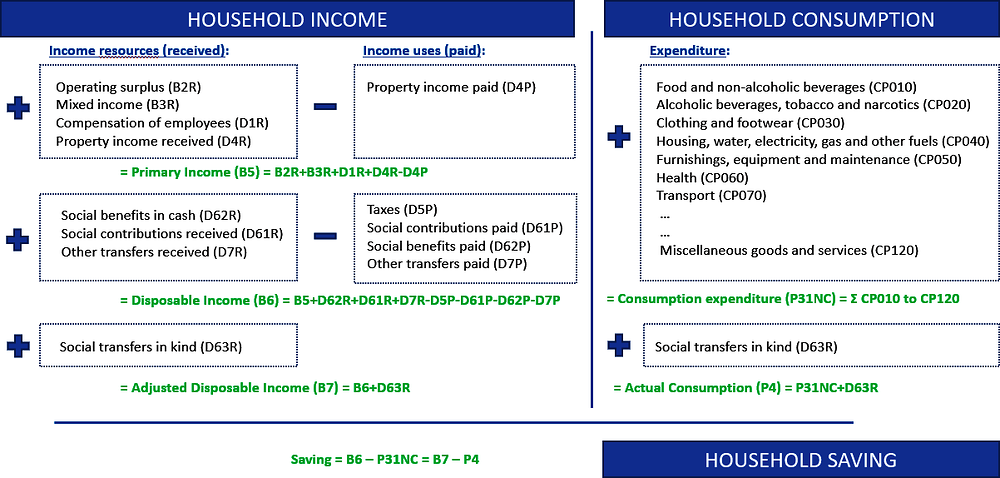
Source: The Author.
This overview is at the basis of the work and underlies the template for compilers to derive distributional results in line with national accounts totals. The next subsections provide a more detailed overview of the various income and consumption items distinguished in the work. The template as developed by the expert group is presented in Section 2.7.
2.4.1. Income
The work identifies three income concepts in line with the system of national accounts, i.e. primary income, disposable income and adjusted disposable income. Primary income is the income that accrues to units “as a consequence of their involvement in processes of production or ownership of assets that may be needed for purposes of production” (see 2008 SNA, §7.2). The main items for the household sector concern operating surplus, mixed income, compensation of employees and net property income, which can be further broken down into more detailed underlying items, such as interest, distributed income of corporations and rent.
Disposable income is the income after re-distribution, i.e. after taking into account current transfers paid and received, such as current taxes on income and wealth, social contributions and social benefits, non-life insurance premiums and claims, and other current transfers like remittances. It is defined in the SNA as the maximum amount that a household can spend on consumption without having to finance it by disposing of assets or increasing its liabilities (see 2008 SNA, §8.25).
Adjusted disposable income is derived on the basis of disposable income, but also including the value of social transfers in kind received by households. These consist of goods and services provided to households by government and non-profit institutions either for free or at prices that are not economically significant. They are a direct alternative to receiving a social benefit in cash for the purchase of these services and therefore are included to arrive at a more comprehensive and comparable income measure. Adjusted disposable income is regarded as the most comprehensive income concept and constitutes the main income measure in the DNA work. It is regarded as providing the best insights into inequality in a country and the best measure to use for cross-country comparisons as well as analyses of dynamics of inequality over time.4
In the template, the income measures are further broken down into more detailed income components. Table 2.1 provides an overview of the components distinguished in the DNA work in relation to the three income measures. This more detailed breakdown provides compilers the possibility to better match the various income items to information from micro statistics and to impute for missing information at a more granular level. It is recommended to compile results at this more granular level (or even more granular levels if this provides a better match to the corresponding income item(s) in the micro data), as it is expected to lead to better quality results than directly targeting the aggregates. Furthermore, such an approach allows for a publication of distributional results at a more detailed level, which will provide users more insight in the composition of household income for the various household groups. The various items are discussed in more detail in Chapter 10.
The main focus in the template is on gross income measures. Although net measures are preferable from a conceptual point of view, gross measures are still frequently used in macroeconomic analyses given the difficulty in measuring consumption of fixed capital (i.e. depreciation). However, in the interest of giving more prominence to net measures (as will be recommended in the 2025 SNA), the template includes memorandum items for the consumption of fixed capital for the two relevant income items (i.e. operating surplus and mixed income), providing the opportunity to present net values for the main income measures in addition to the gross measures, as well as to compile net saving results (see Section 2.7).
Differences with other income measures
To have a better understanding of the income concept as used in the work, this subsection provides an overview of some other frequently used income concepts and explains the main differences with the concept used in the DNA work.
A frequently used income measure concerns the one defined by the Canberra Group (United Nations Economic Commission for Europe, 2011[2]). This income measure comes close to adjusted disposable income as defined in the 2008 SNA but differs in some important respects reflecting the different focus of the two concepts. The income measure as used by the Canberra Group is based on the conceptual definition as established by the International Conference on Labour Statisticians (ICLS) and states that “household income consists of all receipts whether monetary or in kind (goods and services) that are received by the household or individual members of the household at annual or more frequent intervals but excludes windfall gains and other such irregular and typically one-time receipts”.
When comparing the Canberra definition with the income definition in the SNA, the main differences relate to the exclusion of some imputed income items (such as investment income disbursements (D44R)), as well as the exclusion of non-life insurance benefits (D72R) and winnings from lotteries (included in D75R) from the Canberra definition. Furthermore, whereas the conceptual definition used by the Canberra Group includes social transfers in kind, these are excluded from the operational definition because of measurement difficulties. Another important difference relates to the use of cash recording in the Canberra measure versus the use of accrual accounting in the SNA. This may lead to differences in time of recording when the actual payment does not coincide with the economic transaction (e.g. deferred tax payments). As the Canberra Handbook underlies a lot of the micro data sources that may be used in the compilation of distributional results in line with national accounts totals, Annex A provides a detailed overview of the differences between the income concepts as defined in the SNA and as used by the Canberra Group.
A Handbook that also underlies a lot of micro statistics is the OECD Framework for Statistics on the Distribution of ICW (OECD, 2013[3]). This framework applies the same income definition as used in the Canberra Group Handbook but distinguishes some different underlying income items. As it has been developed to maintain full consistency with the income concepts as used in the Canberra Group Handbook, the income measure as used by the ICW Framework shows more or less the same differences with the SNA concept. However, as the underlying items may sometimes differ, Annex A provides a detailed overview of the differences between the income concept as defined in the SNA and in the ICW Framework.
Thirdly, a well-known income concept is the one developed by Haig (1921[7]) and Simons (1938[8]), and by Hicks (1946[9]), measuring income as the maximum amount that can be consumed in a given period while keeping real wealth unchanged. This means that in addition to income as defined in the SNA, it also includes holding gains and losses related to the holding of non-financial and financial assets and liabilities. This type of information is included in the accumulation accounts in the framework of national accounts (see Figure 2.1) and could be taken into account once distributional information becomes available for the accumulation accounts. Although it is not part of the income definition as defined by the SNA, it would provide more insight into the economic situation of various household groups.
Finally, the DINA project also compiles distributional results in line with national accounts totals. The income measures5 used in this project have a broader coverage than household income as defined in the SNA, as their focus is on alignment to national income, i.e. the income of the economy as a whole, so also including income of the other sectors in the domestic economy. The main underlying reason is that in their view all forms of income in the economy eventually accrue to resident individuals (see Blanchet et al. (2021[10])). In that sense, they aim to come closer to the income concepts of Haig, Simons and Hicks as explained above. However, it is questionable whether national income would in this regard lead to the best approximation of this income concept. As explained above, it may be better to focus on deriving distributional results for the accumulation accounts to obtain more insight on how holding gains and losses are distributed across various household groups, also taking into consideration other holding gains and losses than only those resulting from (undistributed) income.
Table 2.1. Composition of main income measures
Notes: The classification is in line with the 2008 System of National Accounts.
1. FISIM stands for “Financial Services Indirectly Measured” and is explained in more detail in Section 10.5.1.
Source: 2008 SNA (European Commission et al., 2009[1]).
The main differences between post-tax national income as used in DINA and adjusted disposable income as defined in the SNA concerns the inclusion of net primary income of corporations, government surplus/deficit, collective consumption and any gaps between social insurance pension contributions and benefits, and the exclusion of net other current transfers received in the DINA measure. This may lead to very different income levels for the household sector as a whole and may lead to quite different distributional results (see Zwijnenburg (2017[6]) for more information).
2.4.2. Consumption
With regard to consumption, the work identifies two main measures, i.e. final consumption expenditure and actual final consumption. Final consumption expenditure focuses on the amount that households actually spend on consumption goods and services. For distributional purposes, it is important to bear in mind that this also includes any consumption by a household which is paid for by another household (e.g. college fees paid for by a family member in another household). Actual final consumption also includes the consumption of social transfers in kind, which are goods and services that are provided to households by government and non-profit institutions and are thus not directly paid for by households themselves.
The consumption items are broken down into detailed categories on the basis of the classification of individual consumption by purpose (COICOP (United Nations Statistics Division, 2011[11])).6 This is a functional classification which is used to classify the consumption expenditures of households. It distinguishes fourteen main categories. The first 12 items sum up to total final consumption expenditure by households. The last two items identify those parts of consumption expenditure by general government and NPISHs that are treated as social transfers in kind and that are only included in actual final consumption. The DNA work focuses on the breakdown according to COICOP as macro aggregates are usually available at this level of detail from the supply-and-use tables (as explained in Section 2.2), and as most budget surveys usually provide micro information at this level of detail, providing the opportunity to match these data at the detailed level.
Detailed information on the consumption of goods and services is available from the supply-and-use tables. However, it has to be borne in mind that this detailed information may not always concern consumption by resident households only. In some cases, it may also include consumption expenditure by non-resident households which will then have to be excluded at this detailed level. Furthermore, depending on the set-up of the supply-and-use tables, the results at the detailed level of consumption items may only concern consumption expenditure in the domestic economy, whereas any consumption expenditure abroad may only be available as an aggregate item. Depending on the coverage and the level of detail available in the micro data, this could also require a specific adjustment to arrive at total consumption expenditure of resident households only. For that reason, the template identifies specific rows to make any necessary corrections in this light. Section 4.4 explains these corrections in more detail.
Table 2.2 offers an overview of the consumption table as used in the DNA work. It shows the COICOP categories as well as some additional breakdowns for specific items which are included to provide compilers the opportunity to either better match the data with information available from micro data sources or to impute for specific elements in case of missing micro data. Countries are encouraged to compile results at these more detailed breakdowns as it is expected to lead to better results. As explained above, the table also contains two specific rows to include expenditures by resident households abroad and to correct for expenditures by non-resident households on the territory depending on how they are calculated in the supply-and-use tables and dependent on how they are covered in the micro data. The various consumption items are discussed in more detail in Chapter 11.
In addition to the various consumption items, the template also includes memorandum items to separately distinguish expenditures on consumer durables and to record information on taxes and subsidies on production and imports as paid by the various household groups. Separate information on consumer durables is of relevance as they may significantly affect saving results and might explain negative savings for specific households in specific years. Information on taxes and subsidies on production and imports is of relevance in analysing the impact of government taxes on various household groups. For that reason, compilers are encouraged to include this information if possible.
Table 2.2. Composition of main consumption expenditure measures
Notes: The classification is in line with the 2008 System of National Accounts and COICOP 2011.
1. FISIM stands for “Financial Services Indirectly Measured” and is explained in more detail in Section 10.5.1.
Source: 2008 SNA (European Commission et al., 2009[1]).
Differences with other consumption measures
As was the case for income, micro statistics use a slightly different definition of household consumption expenditure from the SNA. The ICW Framework (OECD, 2013[3]) explains that consumption expenditure only includes the acquisition of consumption items, i.e. items that are expected to be used up immediately or in a relatively short period of time. This means that whereas consumer durables are included in the consumption measure of the SNA, they are excluded in the OECD Income Distribution Database (IDD) measure because they are regarded as providing services to the household over a longer period of time. The purchases of consumer durables are treated as capital expenditure in the IDD and the resulting services are treated as being consumed by households. This is not the case in the SNA (see 2008 SNA, §9.44), mainly because of the difficulty in deriving accurate measures of the value of the unpaid household services that would be produced on the basis of these durables.
The IDD database also applies a different recording of non-life insurance premiums and claims, as well as for expenditure and gains related to gambling. Whereas these are recorded as current transfers in the SNA, they are treated as consumption expenditure in the IDD. The expenditures on non-life insurance and gambling are recorded as consumption, whereas small windfall gains from non-life insurance and small gambling winnings are treated as negative consumption. On the other hand, large windfall gains are treated as capital transfers in the IDD. Annex A provides a detailed overview of the differences between the consumption concept as defined in the SNA and by the Canberra Group.
2.4.3. Saving
As the work focuses on both income and consumption, results can also be derived for savings across the distribution. Table 2.3 provides an overview of how saving is derived in the DNA approach.
Table 2.3. Derivation of saving
Note: The classification is in line with the 2008 System of National Accounts.
Source: 2008 SNA (European Commission et al., 2009[1]).
In addition to income and consumption there is an additional item that is needed to derive saving for the various household groups. This concerns an adjustment for the change in net equity of households in pension funds (D8). This is needed because of the way contributions paid to and the benefits received from pension funds are treated in the SNA. On the one hand, they are recorded as current income and expenditure, while on the other hand they are also considered as a (dis)saving, adding to (or reducing) the value of pension entitlements. Because the related transactions are not treated as purely financial, but also as income flows, a correction has to be made when deriving saving to reflect that these flows also affect households’ saving, increasing their pension entitlements as a consequence of pension contributions and decreasing their entitlements due to the receipt of pension benefits (see also Section 11.16).
2.5. Household group breakdowns as identified in the work
In the DNA approach, results can be broken down into various types of household groups. This section provides examples of breakdowns that have been identified in the DNA work so far, but depending on the available underlying information, other breakdowns can be envisaged as well.
2.5.1. Standard of living (equivalized disposable income)
First of all, data can be broken down according to standard of living, i.e. on the basis of equivalized disposable income of households. For that purpose, household disposable income has to be divided by the number of consumption units depending on the equivalence scale used (see Box 2.1), after which households can be ranked according to this equivalized disposable income. They can then be clustered accordingly, for example into income quintiles (Q1, Q2, Q3, Q4 and Q5) in such a way that each quintile represents 20% of the households.
Please note that whereas the classification is done on the basis of equivalised results, thus taking into account the number of consumption units, the distribution into quintiles is done solely on the basis of the number of households. Hence, when breaking down by income quintile, each quintile represents 20% of the total number of households and not of consumption units. Furthermore, please note that whereas the main focus for measuring income inequality is on adjusted disposable income, as it constitutes the most comprehensive income measure, the classification for standard of living is based on equivalized disposable income, as disposable income is the income that households can freely dispose of.
In the first three collection rounds, the EG DNA has focused on breakdowns by income quintile but depending on user needs and the quality of the underlying data, more granular breakdowns can be envisaged as well, for example into deciles or percentiles. In this regard, the new G20 Data Gaps Initiative (IMF, 2023[12]) includes the recommendation for G20 economies to publish annual distributional results at the decile level by the end of 2026. In view of the recommendations of the new Data Gaps Initiative and increasing user demands for more granular information, particularly for the upper and lower tail, the template already includes the possibility for recording data at the decile level, as well as for the bottom 5% and the top 5%, 1% and 0.1%.
In compiling more detailed breakdowns, compilers have to be aware of the quality of the distributional results and their sensitivity to specific assumptions in the compilation process, for example to bridge any gaps between the micro and macro data. It needs to be carefully assessed what level of detail may be opportune given the quality of the data.
2.5.2. Main source of income
A different classification that can be applied is according to main source of income. For that purpose, four categories are currently distinguished, namely a) wages and salaries (i.e. linked to item D11R), b) income from self-employment (i.e. linked to item B3R3), c) net property income (i.e. linked to item D4N), and d) current transfers received (i.e. linked to the sum of D62R (social benefits in cash received), D63R (social benefits in kind received) and D7R (other current transfers received)).7 Households should be classified in the category which shows the highest contribution to the household income.
2.5.3. Household type
A third classification in the DNA work is according to household type. This takes into account the presence, number and age of the members of the household. In the DNA work eight categories of household types are distinguished, i.e. a) single less than 65 years old, b) single 65 and older, c) single with children living at home, d) two adults less than 65 without children living at home, e) two adults at least one 65 or older without children living at home, f) two adults with less than 3 children living at home, g) two adults with at least 3 children living at home, and h) others. In this classification, an adult is defined as anyone 18 years or older.8 Furthermore, the delineation of “children living at home” is based on all individuals up until the age of 16 plus the individuals whose age is between 17 and 24 and are offspring of one of the household members and are still living at home. Depending on user needs and the quality and available detail from the underlying data, more granular breakdowns can be envisaged as well.
2.5.4. Other possible breakdowns
In addition to the classifications presented here, one could also envisage other breakdowns which may be of interest to users. This may for example include breakdowns according to housing status (rental, owner-occupied with mortgage, and owner-occupied without mortgage), region (for example according to Nomenclature of territorial units for statistics (NUTS) levels in Europe) or on the basis of socio-demographic information, e.g. according to the age, gender or labour market status of the head of the household, where the head of the household is usually defined as the person with the highest income.9 It will depend on user needs, the level of available detail in the underlying data, and on the quality of the underlying results, which level of detail could be targeted.
When the breakdown is based on characteristics of the household head, it needs to be borne in mind that this is only focusing on the characteristics of one household member and may not provide a balanced overview for the situation of the population at large. In this regard, the people that may qualify as household head may not be reflective of other people with similar socio-demographic characteristics. For example, when looking at income inequality by gender on the basis of distributional results broken down according to gender of the head of the household, this only provides insights into the difference in (equivalised) income between households with a man as household head versus those with a woman as head of the household, but not of the difference in (equivalised) income between men and women in general. Conclusions on the latter can only be derived, if the men and women acting as household head are representative for all men and women in society, which will often not be the case. This caveat needs to be made clear when presenting results on the basis of breakdowns according to household head to users.
2.6. Additional socio-demographic information accompanying the results
To obtain more background information on the various household groups, the DNA work also recommends compiling socio-demographic information to accompany the results for the various household groups. Some of these breakdowns may focus on specific socio-demographic characteristics of households, whereas others may focus on characteristics of the individuals belonging to the households in the various household groups. It will depend on the information available from micro data sources and the way in which the results are aligned to the national accounts totals, which type of socio-demographic information can be published. This section provides a description of the additional socio-demographic information that is targeted in the DNA work, although other breakdowns may be envisaged as well.
2.6.1. Household type
Background information can be provided on the size and composition of the households included in the various household groups. In the DNA work, the household types are distinguished according to the presence, number and age of the members of the household. See Section 2.5.3 for more information on the categories that are identified. Depending on user needs and the quality of the underlying data, more granular breakdowns can be targeted.
2.6.2. Housing status
An overview can also be provided on the basis of the housing status of the households included in the various household groups. This breaks down households into a) households that rent their house (rental), b) households that own their house (partly) financing it via a mortgage loan (owner-occupied with mortgage), and c) households that own their house without having a mortgage loan (owner-occupied without mortgage).
2.6.3. Age
The classification according to age10 looks at how people of different ages are distributed across the various household groups. Instead of only looking at households and the age of the household head, in this case, each individual is classified according to the category in which the household he/she belongs to is classified. For this purpose, the DNA work defines six age groups, i.e. individuals between a) 0-14, b) 15-24, c) 25-34, d) 35-44, e) 45-64, and f) individuals above 65.11 Depending on user needs and the quality of the underlying data, more granular breakdowns can be envisaged.
2.6.4. Sex
A breakdown can also be envisaged according to sex, showing the number of males and females (and non-binary) in each household group. Depending on user needs and the quality of the underlying data, this could also be combined with some of the other breakdowns presented in this section, for example in combination with age.
2.6.5. Main activity
Useful information can also be obtained by breaking down the various household groups into number of individuals according to their main activity. For that purpose, the DNA work identifies nine categories, i.e. a) unemployed, b) employee, c) employer, d) own-account worker, e) unpaid family worker, f) member of producer’s cooperative, g) student, h) retired, and i) not classifiable. These categories are partly derived on the basis of the employment status categories as defined in the ILO International Classification by Status in Employment (ICSE) 1993 (International Labour Organisation, 1993[13]), supplemented by relevant categories for individuals without any form of employment.12
To start with the categories related to employment status, in line with the definition of ICSE-93, employees should encompass persons with paid employment jobs i.e. people with explicit or implicit employment contracts “which give them a basic remuneration which is not directly dependent upon the revenue of the unit for which they work”. Own-account workers or self-employed refer to those people for which the remuneration is directly dependent upon the profits from the production process and that have not employed staff on a continuous basis during the reference period. In case they do employ staff, they are classified as employers. Members of producers’ cooperatives are workers who hold self-employment jobs in a cooperative, in which each member “takes part on an equal footing with other members in determining the organization of production, sales and/or other work of the establishment, the investments and the distribution of the proceeds of the establishment among their members”. This excludes employees of producers’ cooperatives who should be classified as employees. Unpaid family workers are workers that hold a "self-employment" job in an enterprise operated by a related person living in the same household, but that are not regarded as a partner (International Labour Organisation, 1993[13]).
In addition to these employment status categories, the DNA work also distinguishes non-employment related categories. The category “unemployed” concerns all persons who during the reference period were not in employment or self-employment but were available for employment or self-employment and were actually seeking work (International Labour Organisation, 1982[14]). Students are persons that are not classified as usually economically active, who attend any regular educational institution, public or private, for systematic instruction at any level of education (United Nations, 2008[15]). There are several definitions that are used to delineate retired persons. The definition that is used in the DNA work is to distinguish those individuals that are eligible for private or public pension benefits. Finally, individuals not classifiable include those for whom insufficient relevant information is available, and/or who cannot be included in any of the preceding categories.
Individuals should be classified according to their main activity, which is defined as the activity which they spend most of their time on. For persons that may change status throughout the reference period, ideally information is available on the length of the activities they engaged in. In that case, individuals can be classified according to the status that they held for the longest period. Alternatively, a decision could be made on the basis of underlying micro data, e.g. tax data may provide information on how many months an individual received wages and for how many months unemployment (or other) benefits; otherwise it may perhaps be possible to derive it on the basis of the relevant amounts; if the amount of wages is still significant (e.g. in relation to wages of previous (or future) years or comparable to other persons holding the same job) and/or if unemployment benefits are still small (also in relation to other unemployed persons or in relation to previous (or future) years), it may be better to classify a person in the “employed” category than in the “unemployed” category.
2.6.6. Highest level of education achieved
Another socio-demographic breakdown that may be of interest to users is a categorisation of individuals according to their highest level of education achieved. The categories that are used in the DNA work are derived on the basis of the International Standard Classification of Education (ISCED) (UNESCO Institute for Statistics, 2012[16]) which distinguishes nine categories, i.e. 0) less than primary education, 1) primary education, 2) lower secondary education, 3) upper secondary education, 4) post-secondary non-tertiary education, 5) short-cycle tertiary education, 6) bachelor’s or equivalent level, 7) master’s or equivalent level, 8) doctoral or equivalent level, and 9) not elsewhere classified. In the DNA work, some of these levels are combined to arrive at a smaller level of detail, distinguishing: a) low (corresponding to levels 0-2 of the ISCED-A, 2011), b) middle (3-5), c) high (6-8), and d) not elsewhere classified (9). As individuals that never attended an education program (including small children) have to be classified in category zero according to the ISCED-A, they would end up in category “low” in the DNA template.
2.7. Presentation of the template
The conceptual framework as presented in this chapter is at the basis of the template that is recommended for the compilation of distributional results according to the methodology as developed by the EG DNA. Table 2.4 to Table 2.6 provide an overview of the general set-up of this template.
The template presents the household groups in the columns and the national accounts item in the rows. In that, it distinguishes two blocks, focusing on respectively income (Table 2.4), and consumption and saving (Table 2.5).
In the income block, the columns start with the information available from the national accounts (“original estimates”), targeting data on the household sector (column B1) but also providing the opportunity to first report data for the household and NPISH sector jointly (column A) if results for the household sector are not available separately. In that case, adjustments will have to be made to arrive at results that only relate to the household sector (see Section 4.2). The consumption and saving block has a similar setup, but in this case the first column (A1) relates to totals obtained from the supply-and-use tables. As these results may include amounts relating to NPISHs and non-resident households, the template includes two columns to correct for these amounts (A2 and A3, respectively). Furthermore, it includes a column (A4) to include consumption of resident households abroad (column A4), in case this information is available at the detailed level of consumption items, to arrive at total consumption expenditure of resident households (column B1).
Both blocks then shows two columns (“adjusted estimates”) to distinguish institutional households (column B2) from private households (column B3), the latter constituting the target population of the DNA work. Their results are broken down into household groups on the basis of the breakdowns, as explained in Section 2.5, and the accompanying levels of detail as selected by the compiler. In the example in Table 2.4 a breakdown is presented according to equivalised disposable income levels broken down into income deciles.13 In this case, households are categorised on the basis of their ranking according to equivalised disposable income as explained in Section 2.5.1.
Given the importance of the micro data in the process, the template also includes a column (C1) showing the aggregate from the micro data source used for the distribution of the specific national accounts item (“micro source aggregate”) as well as the discrepancy between this aggregate and the adjusted national accounts totals relating to private households (column D, i.e. “discrepancy”).
Finally, the template includes a block that focuses on socio-demographic characteristics of the various household groups (Table 2.6). This block shows breakdowns into the various socio-demographic characteristics as described in Section 2.6 for the specific household groups for which distributional results have been compiled. It starts with information for the household sector as a whole (column B1), with a breakdown into institutional households (column B2) and private households (column B3). It then targets the information by the various household groups.
Compilers are recommended to use this template in compiling distributional results according to the DNA methodology. As changes be made to the templates over time (for example in view of the G20 Data Gaps Initiative recommendations and the update of the 2008 SNA), it is advised that compilers check the latest version of the template which can be found here.
Table 2.4. Template for distributional results on income
Source: The Author.
Table 2.5. Template for distributional results on consumption and saving
Source: The Author.
Table 2.6. Template for socio-demographic background information on distributional results
Source: The Author.
References
[10] Blanchet, T. et al. (2021), Distributional National Accounts guidelines - Methods and concepts used in the World Inequality Database.
[1] European Commission et al. (2009), System of National Accounts 2008, https://unstats.un.org/unsd/nationalaccount/docs/SNA2008.pdf (accessed on 29 September 2017).
[7] Haig, R. (1921), “The concept of income - Economic and legal aspects”, in Haig, R. (ed.), The federal income tax, Columbia University Press, https://ia800208.us.archive.org/25/items/cu31924020062935/cu31924020062935.pdf (accessed on 5 December 2017).
[9] Hicks, J. (1946), Value and Capital: An Inquiry Into Some Fundamental Principles of Economic Theory, Clarendon Press.
[12] IMF (2023), G20 Data Gaps Initiative, https://www.imf.org/en/News/Seminars/Conferences/g20-data-gaps-initiative (accessed on 14 March 2023).
[13] International Labour Organisation (1993), Resolution concerning the International Classification of Status in Employment (ICSE), adopted by the Fifteenth International Conference of Labour Statisticians (January 1993), http://www.ilo.org/wcmsp5/groups/public/---dgreports/---stat/documents/normativeinstrument/wcms_087562.pdf (accessed on 29 September 2017).
[14] International Labour Organisation (1982), Resolution concerning statistics of the economically active population, employment, unemployment and underemployment, adopted by the Thirteenth International Conference of Labour Statisticians (October 1982), http://www.ilo.org/public/english/bureau/stat/download/res/ecacpop.pdf (accessed on 8 December 2017).
[3] OECD (2013), OECD Framework for Statistics on the Distribution of Household Income, Consumption and Wealth, OECD Publishing, Paris, https://doi.org/10.1787/9789264194830-en.
[5] Radner, D. (1994), “Noncash income, equivalence scales, and the measurement of economic well-being”, ORS Working Paper Series, No. 63, https://www.ssa.gov/policy/docs/workingpapers/wp63.pdf (accessed on 29 September 2017).
[8] Simons, H. (1938), Personal Income Taxation: the Definition of Income as a Problem of Fiscal Policy, University of Chicago Press, Chicago.
[16] UNESCO Institute for Statistics (2012), International Standard Classification of Education (ISCED-2011), http://uis.unesco.org/sites/default/files/documents/international-standard-classification-of-education-isced-2011-en.pdf (accessed on 29 September 2017).
[17] United Nations (2018), Classification of Individual Consumption According to Purpose 2018.
[15] United Nations (2008), “Principles and Recommendations for Population and Housing Censuses”, https://unstats.un.org/unsd/publication/seriesm/seriesm_67rev2e.pdf (accessed on 8 December 2017).
[2] United Nations Economic Commission for Europe (2011), Canberra Group Handbook on Household Income Statistics, https://www.unece.org/fileadmin/DAM/stats/groups/cgh/Canbera_Handbook_2011_WEB.pdf (accessed on 27 September 2017).
[11] United Nations Statistics Division (2011), Classification of Individual Consumption According to Purpose (COICOP) - Global Inventory of Statistical Standards, https://unstats.un.org/unsd/iiss/Classification-of-Individual-Consumption-According-to-Purpose-COICOP.ashx (accessed on 20 October 2017).
[4] van de Ven, P. and D. Fano (eds.) (2017), Understanding Financial Accounts, OECD Publishing, Paris, https://doi.org/10.1787/9789264281288-en.
[6] Zwijnenburg, J. (2017), “Unequal distributions? - A study on differences between the compilation of household distributional results according to DINA and EGDNA methodology”, http://wordpress.wid.world/wp-content/uploads/2017/11/054-DNA_OECD.pdf (accessed on 5 December 2017).
Notes
← 1. An adult is defined here as anyone 18 years or older. In line with general SNA principles, the age of a person for a given reference year should be derived on the basis of its age during the largest part of the year. This means that anyone born after the 1st of July should be assigned its age at the start of the year, whereas anyone born on or before the 1st of July should be assigned its age at the end of the year. If this is not feasible, it could also be decided to take one cut-off point in the year (e.g. at the start or at the end of the reference period), bearing in mind that this may generate slightly different results.
← 2. Alternatively, they could be treated separately in the process; deriving distributional results for them, separate from the private households, and then adding these results back at the end of the exercise. Another alternative is to treat all persons within an institutional household as a separate one-person household in compiling the distributional results. The benefit of these approaches is that it will lead to results that are in line with those for the household sector as published in the national accounts (although it needs to be borne in mind that some other adjustments may be needed in the process, which may lead to deviations from the national accounts totals in any case (see also Chapter 4)). However, compilers and users need to be aware that these approaches may not do justice to the specific circumstances these individuals live in and that it may lead to heterogeneous results and distort distributional analyses.
← 3. Please note that in the standard of living classification as applied in the DNA approach (see Section 2.5.1), households are ranked and clustered according to their equivalized disposable income. In analysing income inequality according to primary income, it may be better to rank and cluster households according to their equivalized primary income.
← 4. Dependent on the specific policy purpose, some users may be more interested in alternative income measures, such as primary income and disposable income. The DNA approach also provides the possibility to compile results according to these measures. However, for international comparisons, it is recommended to compile and analyse information on the basis of adjusted disposable income.
← 5. In DINA, four income concepts are distinguished. Factor income focuses on the income before any re-distribution takes place. Pre-tax income looks at the impact of the pension system, recording pension transactions on a distribution basis instead of on a contribution basis. Post-tax income focuses on income after re-distribution, i.e. after deduction of all taxes, processing all social transfers, and after adding back all public spending, including collective consumption. In addition to post-tax national income, the project also distinguishes post-tax disposable income, which excludes the value of collective consumption and social transfers in kind, as well as any government surplus or deficit.
← 6. A new version of COICOP has become available in 2018 (COICOP 2018 (United Nations, 2018[17]), with includes some minor changes in comparison to the 2011 version. Once this new COICOP will have been implemented by countries, it will also be reflected in an updated version of the DNA template.
← 7. The latter category could be further broken down into pension benefits received and other current transfers received, in case the relevant information is available at that level of detail.
← 8. In line with general SNA principles, the age of a person for a given reference year should be derived on the basis of his/her age during the largest part of the year. This means that anyone born on or after the 1st of July should be assigned its age at the start of the year, whereas anyone born before the 1st of July should be assigned its age at the end of the year. If this is not feasible, it could be decided to take one cut-off point in the year (e.g. at the start or at the end of the reference period), bearing in mind that this may generate slightly different results.
← 9. Countries apply different rules to determine the head of the household, but most of them define it as the person with the highest income (see also (United Nations Economic Commission for Europe, 2011[2]) and (OECD, 2013[3])).
← 10. See footnote 11 for more information on how to determine the age of the relevant persons.
← 11. For national purposes, it may also be of interest to delineate the last two groups on the basis of the retirement age in the country. However, for international comparability, it is recommended to maintain the breakdowns as suggested here. Furthermore, in using the retirement age, it has to be borne in mind that time series analysis may be affected, when the retirement age is changing over time.
← 12. In the meantime, the ISCE-93 has been updated to ISCE-18, including more granular classes based on the type of authority that the worker is able to exercise in relation to the work performed and the type of economic risk to which the worker is exposed. In the future, it may be assessed whether the categories in the DNA template could be updated to reflect (some of) these new categories.
← 13. The template also includes the possibility to record results broken down by income quintile, as well as the option to provide more granular information for the tails, i.e. results for the bottom 5% and the top 5%, 1% and 0.1%. Furthermore, the template includes “optional” breakdowns which are not presented in Table 2.4 and Table 2.5 classifying households according to main source of income and household type as explained in Sections 2.5.2 and 2.5.3.