This chapter provides an overview of the methodology to derive distributional estimates within the national accounts framework on the basis of micro data sources, according to the conceptual framework as laid down in the previous chapter.
OECD Handbook on the Compilation of Household Distributional Results on Income, Consumption and Saving in Line with National Accounts Totals

3. Overview of the methodology
Abstract
3.1. Introduction
Given the fact that the methodology uses both national accounts data and micro data sources for the compilation of the distributional results, an approach is needed to combine these two types of information in a way that addresses the important differences that may exist between them and that deals with any additional information that may be needed to arrive at robust distributional results. The overall results will depend on the inherent quality of the micro and macro data used, the quality of any necessary alignments and edits made to both sources, and of the imputations that are needed to correct for any missing elements. In consideration of these tasks, the expert group developed a methodology and practical guidance on how to deal with specific methodological challenges. This chapter provides a general description of the methodology and some explanation on the specific steps. The next chapters discuss them in more detail.
3.2. Step-by-step approach
The methodology for compiling distributional information within the national accounts framework is set up as a step-by-step procedure to clearly distinguish between the various steps that are needed to arrive at the distributional results in line with the conceptual framework as explained in the previous chapter. Figure 3.1 provides an overview of this step-by-step approach.
Figure 3.1. A step-by-step approach for the estimation of distributional information
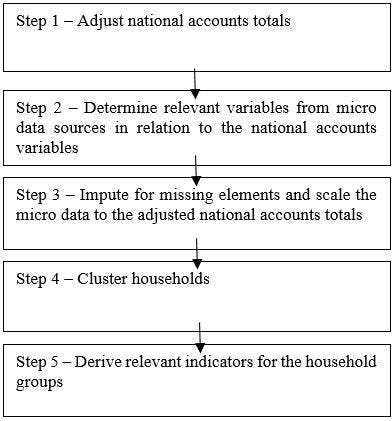
Source: The Author.
As the distributional results only concern a specific part of the household sector in the national accounts, i.e. private households, in the first step the national accounts totals on income and consumption have to be adjusted to exclude information that does not relate to private households. This entails adjustments to exclude for the part of the national accounts data that relates to institutional households, but may also concern other adjustments, depending on the coverage of the available data. For example, in case the household sector is published in combination with non-profit institutions serving households, a correction would be needed to exclude the latter from the national accounts results. Furthermore, it may be the case that the available consumption data include expenditures of non-residents on the territory. This may also require corrections to arrive at comprehensive results relating to private resident households only. This first step in the methodology is discussed in more detail in Chapter4.
In a second step, micro variables should be selected in accordance with the relevant national accounts variables, to provide the underlying distributional information for the relevant items. In some cases, this may be rather straightforward, but sometimes there may be conceptual and classification differences between the national accounts items and the corresponding micro variables. This may then necessitate combining multiple micro variables and/or the re-classification of certain sub-items in order to arrive at conceptually sound matches with the national accounts items. Furthermore, in selecting the relevant items from micro data, multiple data sources may be available providing information on a similar topic. In that case, it should be assessed which data source(s) and item(s) provide the best link. The selection of micro data variables is discussed in Chapter 5.
As the micro data will usually not perfectly align with the national accounts data, the third step concerns the bridging of any gaps. First of all, this may concern items that are not covered by micro data at all. Certain variables are specific to the System of National Accounts and do not have a counterpart item in the micro data. This for example concerns items such as financial intermediation services indirectly measured (FISIM) (see Section 10.5.1) and investment income disbursements (see Section 10.5.4). For these items, the distribution will have to be obtained in a different way, for example on the basis of auxiliary information or linking it to the distribution of other items. The imputation for missing items will be discussed in more detail in Chapter 6.
Secondly, for items for which a corresponding micro item is available, the aggregates will not always match perfectly. This may be due to several reasons, such as measurement and estimation errors in the micro data or quality issues with the national accounts totals or with any adjustment that was made to arrive at data for private households. As the goal is to arrive at distributional data in line with national accounts totals, these gaps will need to be bridged in the third step of the step-by-step approach. This issue is discussed in more detail in Chapter 7.
In the fourth step, on the basis of the aligned results, households can be clustered into household groups. This may for example be done based on equivalised disposable income (e.g. in income quintiles or deciles), but also on the basis of alternative classifications, such as main source of income or household composition. This step is explained in Chapter 9.
After this clustering, disparity indicators can be derived in the fifth step to provide more insight in the levels of inequality. Chapter 13 presents several indicators that can be used for this purpose.
The step-by-step procedure requires that the micro data sets that are used in the process are properly linked in order to construct coherent distributional information at the level of the household or at least at the household group. As different micro data sources may be used to obtain details on income, consumption and saving, the compiler must ensure that each source identifies households in a consistent manner. As the method of linking micro sources can significantly impact the results, special consideration is assigned to this task in Chapter 8.