John Sabatini
University of Memphis
Xiangen Hu
University of Memphis
Mario Piacentini
OECD
Natalie Foster
OECD

John Sabatini
University of Memphis
Xiangen Hu
University of Memphis
Mario Piacentini
OECD
Natalie Foster
OECD
Next-generation assessments of 21st Century competencies should confront students with relevant activities that are situated within authentic contexts of practice. This chapter unpacks the contemporary assessment designers’ toolbox: it discusses how modern digital technologies can innovate assessment task formats, test features and sources of evidence to allow more interactive and immersive problems that are adaptive, include resources for learning and provide affordances for students to make choices. The chapter presents a framework that sets out technology-enhanced assessment task design possibilities and discusses the potential validity challenges and trade-offs that assessment developers will face when incorporating such innovations.
Motivating the need for change in assessment design, How People Learn I and II (National Research Council, 1999[1]; National Academies of Science, Engineering and Medicine, 2018[2]) reviewed and described the multiple ways that individuals learn in distinct disciplines and domains on a trajectory towards expertise, mastery or proficiency. The result of successful learning is the ability to flexibly call upon one’s knowledge and skills to identify and solve simple and complex problems in a domain – sometimes as an individual, sometimes collaboratively. As also argued elsewhere in this report (see Chapter 2), multiple voices in the field of assessment have applied this cognitive or learning science perspective to test design, proposing frameworks and models for transforming assessments from measures of static knowledge into measures with the twin purposes of evaluating an individual's position on a scale of expertise and drawing inferences about the kinds learning or instructional experiences that will likely advance them on this trajectory (Mislevy, 2018[3]; 2019[4]; Mislevy and Haertel, 2007[5]; Pellegrino, Chudowsky and Glaser, 2001[6]; Pellegrino, Baxter and Glaser, 1999[7]).
Assessing successful learning requires emulating the conditions in which knowledge and skills are applied. However, educational assessments have not always relied on the kinds of authentic tasks that enable one to evaluate the full range of constructs associated with a given competency – in part because the technical capabilities to instantiate such a vision at scale have been slow to emerge. Educational assessments, particularly large-scale standardised tests, have been designed within a set of constraints – for example printing and transporting costs, test security, test environment, testing time and cost of scoring – while at the same time needing to satisfy technical psychometric standards of reliability, validity, comparability and fairness. Many of the features of “traditional” test design, administration, scoring and reporting (e.g. multiple-choice items) have taken shape because of such constraints (OECD, 2013[8]) and led to a predominantly paper-and-pencil testing regime administered in a single (often lengthy) session. Actual performance assessments were instead restricted to areas like the fine arts or spoken language and the need for one-on-one administration conditions and expert judge appraisal rendered them prohibitively expensive for use at scale. These various constraints have all contributed to delimiting the prospect of building the types of assessments called for by the learning sciences.
However, many of these constraints in test design and administration either no longer apply, have been transformed or can be relaxed in large part due to technological and data analytic advances (see Chapter 5 of this report for an overview). In particular, the digital toolbox available to test developers now dramatically expands assessment design opportunities and affordances. For example, digital technologies create affordances for making the test experience less artificial (recall bubble-fill scantron answer sheets) and more face valid by approximating or simulating the situations or contexts in which target knowledge, skills, abilities and dispositions are used in real life. However, core steps in the assessment design process and validation of evidence remain conceptually the same and necessary to ensure that quality test results are produced.
The preceding chapter (Chapter 6) detailed the core components of an Evidence-Centred Design (ECD) approach for making coherent and robust assessment design decisions, including defining the student model (i.e. the variables that we want to measure as they determine performance in a domain), the task model(s) (i.e. the situations that can elicit observations and potential evidence of such performance) and the evidence model (i.e. the scoring and accumulation of evidence to draw inferences about proficiency). In this chapter, we zoom into the task model component. We describe how technology-enabled innovations are or could be applied to enhance several aspects of task design – namely, task format, test features and sources of evidence – with the goal of eliciting and generating better evidence of what individuals know and can do.
Assessment tasks should be designed to call upon the knowledge, skills, strategies and dispositions required to perform activities in the target domain, thus reflecting the student model. Key to this goal is what test takers encounter in a test: what they are expected to do, what they are able to do and the conditions in which they are expected to do it. Good assessment tasks should also be designed in anticipation of the subsequent interpretive and validation arguments both in terms of the information to be captured as potential evidence and how this evidence can be evaluated to produce valid inferences.
In the following sections, we propose a technology-enhanced assessment (TEA) task design framework that is organised around three main task model elements: 1) task format, or the kinds of problems that test takers engage with; 2) test features, or the affordances and features that can be enabled and overlaid with any of the task formats; and 3) sources of evidence, or the different kinds of observations that can be generated and captured as potential evidence. These elements are represented in Figure 7.1. We discuss the different possibilities enabled by technology in each of these three elements as well as the implications on validity of different design choices. In doing so we discuss a number of illustrative examples though by no means exhaustively cover the emerging possibilities from each cluster.
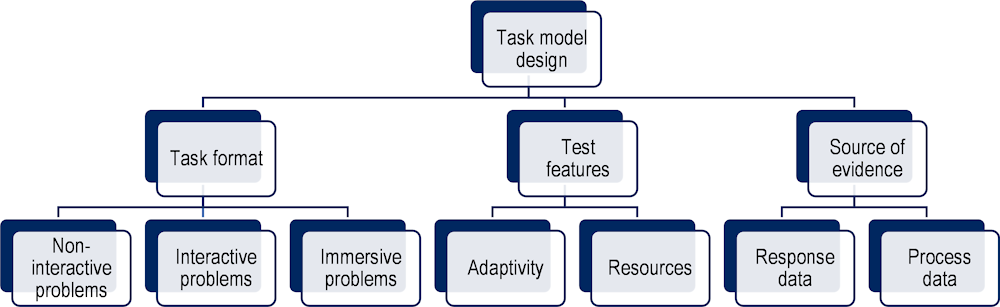
The discussion of the elements in the framework focuses on those possibilities now enhanced or enabled by TEA. That is not to say that all of the techniques cultivated in the paper-based testing era should be abandoned; rather, we contend that these types of items and test features are insufficient alone for measuring the types of complex competences advocated for in contemporary visions of education and assessment (including those in Part I of this report). The goal here is to highlight TEA task design possibilities for constructing more authentic tasks and producing potential evidence that can yield more valid inferences of what individuals know and can do, especially in more complex learning and problem-solving contexts. While several of the task design innovations we describe have been applied or researched to some extent in assessment design, to-date most have more extensively been researched in learning contexts as part of web- or software-based instructional designs.
Technology-enhanced assessments significantly expand the types of task formats that can be presented to students. By “task format” we refer to the presentation of the main task content to test takers (i.e. the task stimuli) as well as the nature of the task problem with which students are asked to engage. In this typology we acknowledge a continuum from static, non-interactive task formats to interactive problem-solving formats with (computational) tools to dynamic and immersive testing environments (see Figure 7.2). While we identify these three classes of task format made possible through TEA, we acknowledge that these are broad generalisations and that it is possible to combine features of the three classes within a single task – particularly when moving towards the more innovative end of the continuum (e.g. combining non-interactive stimuli like written text or audio recordings within immersive games).
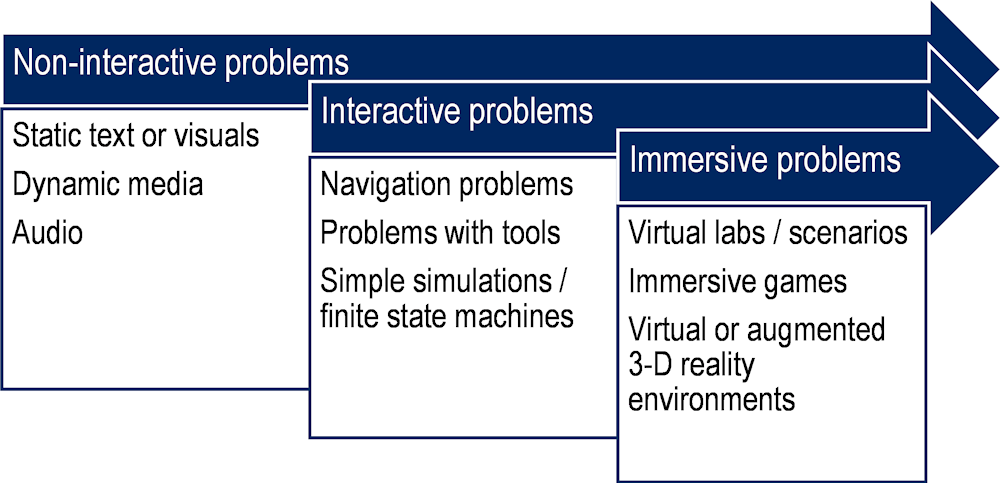
Anchoring one end of the task format continuum are non-interactive problems. The types of fixed tasks used in traditional paper-based assessments presenting static written text or visual stimuli (e.g. photos, drawings, tables, maps, graphs or charts) to examinees can be found in this class of task format. Non-interactive task formats can also include more dynamic stimuli including audio, animations, video, and other dynamic multimedia content that are now relatively easy to produce in TEA. While both static and dynamic stimuli are possible in this task format class, the defining characteristics of non-interactive problems are that the stimulus material usually provides students with all the information they need to solve the task, responses often take the form of written or close-ended items with little to no test taker interactivity possible (beyond perhaps selecting amongst multiple-choice items or drag-and-drop functionality), and the test environment does not evolve as the test taker interacts with it.
Despite falling towards the “less innovative” end of the task format continuum, dynamic stimuli can nonetheless provide critical capabilities for enhancing the delivery of test content and therefore for enhancing validity. For example, well-designed animations or videos can increase engagement, help examinees to understand sequences of steps or actions when forming a mental model in domains such as science, and replace long written texts to reduce cognitive load and the dependency of test performance on reading skills. However, using richer media representations compounds the validity implications that should be considered. For example, there is a rich literature on the limitations and challenges students have in interpreting media, how/whether the media relate to textual descriptions, and generally skills in comprehension and interpretation of non-written stimuli (Mayer, Heiser and Lonn, 2001[9]).
Related, the TEA framework encompasses a vast range of assistive technologies including tools for magnification, guidelines for labelling visuals for text-to-speech capabilities, or the converse for speech-to-text functions. Deciding whether the examinee should have control over assistive technologies also has potential validity implications in terms of altering the cognitive demands of the task or creating unequal test conditions depending on whether the examinee chooses to use them. For example, text-to-speech may benefit a struggling reader in a writing task but if the ability to read text is considered a pre-requisite proficiency to writing skills, then it can bias inferences of ability. Thus, while new task formats may provide new opportunities to enhance task presentation and accessibility, increase engagement and reduce cognitive load, these issues need to be investigated as part of any test validation processes.
While non-interactive task formats may ensure a more uniform experience for test takers, these task formats can ultimately lack face validity especially when trying to replicate and assess behaviours in real-life problem situations. One major advantage of TEA is the ability to create or simulate interactive problem-solving scenarios that characterise more complex types of performances. These types of task format are more open and responsive to test taker actions and behaviours. They are typically multi-step, involve the use of computer applications, tools or search engines, and usually require navigation within and across screen displays.
The types of applications or tools now enabled in TEA environments are numerous and varied. As a simple example, consider word processing applications: they enable users to make notes and highlight text but can also assist with complex writing tasks beyond simply typing and formatting by correcting spelling, anticipating word selection, making recommendations to improve grammar, and providing tools like a thesaurus and dictionary. Similarly, spreadsheet or calculator applications aid in performing a variety of numerical and logical operations. Other more complex tools might include information repositories and search engines or those that enable modelling and simulations. These tools are increasingly used by students for solving problems in these domains; thus, it could be argued that they should become part of the assessment environment if we want to capture evidence that reflects real-life performance. In other words, although including such tools in assessment can scaffold the very skills we have traditionally assessed without their availability, it makes sense to incorporate them as natural supports in testing environments in the same way that pencil-and-paper maths tests allowed for the use of calculators.
In addition to providing tools and environments that better reflect contemporary contexts of practice, interactive problem task formats are necessary for assessing more complex performances. As argued in Chapter 1 of this report, complex constructs are defined at least in part by behaviours or processes meaning that tasks targeting their assessment need to generate evidence of how individuals behave in certain situations and iterate towards a solution (i.e. not only focus on eventual outcomes). Tasks therefore need to elicit target processes and behaviours in authentic ways – through open-ended and multi-step problems – and make those behaviours and thinking processes visible by providing students with tools to make choices and iterate upon their ideas. These task conditions cannot be provided by non-interactive task formats. In contrast, interactive problems allow students to engage actively in the processes of making and doing. For example, finite state machines (simple simulations involving fixed inputs, outputs and states) allow test takers to directly explore relationships and control systems, which can be contextualised in order to provide evidence about different kinds of problem solving (see the PISA 2012 creative problem solving assessment (OECD, 2017[10]) for examples in different contexts).
However, greater task openness and interactivity needs to be balanced with construct and practical considerations such as coverage of the domain or comparability. In other words, tasks that evolve as test takers interact with them may result in less uniform task experiences and therefore uneven coverage of the target constructs. This creates challenges in drawing inferences across student populations. Authentic and interactive tasks might also take more time to complete than simpler static tasks. Therefore, optimal task design for interactive problem types often involves optimising the trade-off between task authenticity and constraints, guided by the student model and practical considerations. Highly interactive and open tasks might adversely influence engagement by increasing the cognitive load for test takers especially if not carefully scaffolded and designed in collaboration with user interface and user experience experts (Mayer, Heiser and Lonn, 2001[9]; Sireci and Zenisky, 2016[11]).
Interactive task formats will likely create new challenges for conventional approaches to establishing valid inferences from test scores. The inclusion of applications or tools might unfairly advantage some test takers over others based on individual differences like digital literacy or familiarity with certain software. Artificially created simulation environments will likely require some pre-training for test takers to fully understand how to operate them. Similarly, TEA tasks that require navigation and interaction inherently demand a certain pre-requisite level of familiarity with digital tools. These are all complex problems that will require new thinking about how to construct and gather evidence for interpretive and validity arguments. In general, decisions to include any tools and interactivity in tasks require test designers to examine possible sources of construct-irrelevant variance and consider how pre-requisite knowledge and skills for interacting with such TEA environments are reflected (or not) in the definition of the target construct.
Anchoring the opposite end of the continuum (for now) from non-interactive problems are truly immersive problems. These include simulated lab, immersive games, or 3D modelling and virtual reality environments. These types of immersive problems allow examinees to navigate through a two- or three-dimensional rendition of a virtual world, on a screen or via virtual reality (VR) headsets, which give the illusion of moving through space. The virtual world can be imaginary or real – one can interact with realistic simulated agents, such as teachers or peer students, or with fictional avatars or animals.
Immersive problems frequently employ game-based elements to enhance motivation as well as scaffold or control learner experience (Pellas et al., 2018[12]). One example of this paradigm is the virtual escape room, where an individual or group navigate a 3D-rendition of a space (room), solving large and small problems until they acquire the keys (i.e. meet criteria) to escape the room (Fotaris and Mastoras, 2019[13]). Shute (2011[14]) embedded an assessment of creative problem solving of this type in the 3D fantasy videogame Oblivion, where players have to solve quests such as locating a person or retrieving a magical object. Other examples of these types of assessment problems include simulations used most often for professional training, such as virtual aviation or medical intervention simulations. These types of tasks are becoming feasible to design, implement and scale, and one can imagine their increasing integration in more educational settings.
In addition to concerns about how to investigate validity as discussed for interactive tasks, research also does not yet show that immersive task formats always improve the measurement characteristics of a task. Indeed, Harris et al. (2020[15]) argue that virtual environments can often confuse the goals of presentation and function, relying on superficial visual features to “achieve” fidelity that are not the key determinants of validity. For example, face validity also requires that the structural and functional features of virtual simulations (e.g. how user inputs and behaviours relate to simulation outcomes) replicate those of real-life situations. It remains paramount that tasks in the virtual world are sensitive to variations in performance between individuals (e.g. real world novices and experts), that they truly reflect and capture the use of knowledge and skills targeted in the student model (i.e. that they have construct validity), and that gamification or virtual immersion used to increase motivation and authenticity do not adversely distract from the task at hand (both literally for the student and figuratively speaking in terms of the assessment goal). Studies that demonstrate transfer from the test environment to real life applications of skills are as critical for establishing support for valid claims from immersive outcomes (i.e. predictive validity) as they are for traditional assessment designs.
The second group of considerations relates to test features enabled by TEA. Here we discuss two specific features: 1) adaptivity; and 2) the provision of feedback and resources (Figure 7.3). Test features refer to affordances or characteristics that can be overlaid with any of the task formats described in the previous section, in more or less transformative ways depending on explicit choices of assessment designers.
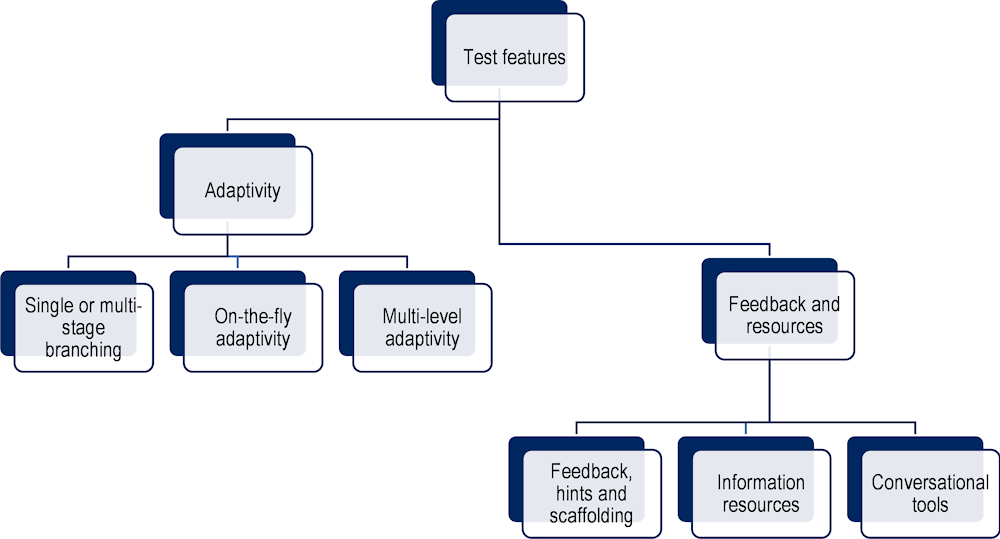
Digital test delivery provides significant opportunities for integrating computer adaptive testing (CAT). In CAT designs, decision rules or algorithms select test items from an item pool for individual examinees. Techniques for implementing psychometrically viable adaptive designs have been established and refined for several decades; indeed, CAT (in its various formats) is one of the most researched innovations in test design since seminal work by Wainer and colleagues (2000[16]). CAT requirements often demand large item pools that are pre-calibrated using models such as item response theory (IRT) and the establishment of appropriate constraints. In this way, different examinees may take different items, but their scores are placed on a common scale. In large-scale testing, this type of adaptivity has been based largely on efficiently estimating the proficiency of an individual on a scale, and the selection of items is based on a set of constraints such as domain sampling and an estimate of ability calculated from performance on previous items.
Various CAT designs, with varying degrees of adaptivity, have been researched and implemented in large-scale assessment. Simpler adaptive designs utilise single or multi-stage branching: in these designs, test items are grouped into modules that differ in test item difficulty. There is typically one module in Stage 1, after which a computer algorithm selects one of the available modules in Stage 2 for examinees to sit next depending on their performance in Stage 1. Several designs are possible: there can be several modules within a stage, and multiple stages in a test (depending on module and test length); and different algorithms can be used to make branching decisions between stages. What these designs share is that adaptivity essentially occurs at the stage-level rather than the item-level. Other designs employ on-the-fly adaptivity, where adaptivity does occur at the item-level (i.e. each item is tailored to the student on the basis of their performance on previous items).
One advantage of single- or multi-stage adaptive testing (MSAT) over item-level adaptive testing is that it allows modules to include larger and more complex task formats that have their own internal naturalistic logic for items contained within the task. Such tasks may not be compatible with on-the-fly CAT designs. The strength of on-the-fly CAT approaches are that they are efficient in the delivery of items for the given constraint set within examinees’ ability range. Consequently, such designs may provide a more precise estimate of ability per unit of test time. The weakness of basing next item decisions solely on performance is that it can result in reduced construct coverage as well as an arbitrary (rather than cohesive or thematic) trajectory through the content domain – thus highlighting the importance of the constraint set in any CAT design. Recent advances in CAT may help to address this issue by integrating hybrid measurement models – in other words, using techniques for modelling embedded construct dimensions such as multiple IRT, q-matrices, diagnostic modelling or knowledge tracing – which hold promise for measuring multiple aspects of performance and manipulating subsequent tasks attempted by the test taker. However, these designs are far less mature than their well-researched counterparts.
Another CAT option is to adapt tasks based on prior choices or actions of the examinee instead of an IRT-based parameter estimation algorithm. This is akin to the adaptivity typically found in videogames where the learner explores an open environment, and the environment adapts to their actions and behaviours within the environment. This design better reflects the reality of contingencies in problem solving environments and its strengths include greater authenticity, interactivity and adaptivity to learner responses – and if designed to give examinees some choice or control, it can also enhance engagement. However, enabling adaptivity fully on the basis of test taker choices can introduce substantial construct-irrelevant variance if choice is not included as part of the student model. Even in cases where choice is explicitly assessed, similar issues can arise as with on-the-fly adaptive models without sufficient constraint mechanisms. Another weakness of internally adaptive tasks is that they may require complex algorithms to deliver. Techniques for developing such designs quickly and efficiently have not yet emerged, rendering this type of adaptivity expensive to develop and pilot as well as more difficult to score for the purpose of standardised assessment. However, innovative assessments might be able to integrate this type of more complex and multi-level adaptivity by adopting some of the technical solutions already used in videogames that are designed to maintain player engagement by alternating states of learning and states of mastery (e.g. presenting a more challenging level or task whenever a simpler one is completed).
Feedback continues to be a frontier concept in assessment despite its prevalence and use in learning systems. Metacognition and self-regulation have become important concepts in psychology and the learning sciences. Metacognition refers to monitoring one's own cognitive processes and progress towards achieving a goal (Azevedo and Aleven, 2013[17]; Hacker, Dunlosky and Graesser, 2009[18]). Self-regulated learning refers to the regulation of one’s cognitive and affective behaviours while executing a task including planning, setting goals, enacting and adapting strategies, and maintaining engagement and motivation (Panadero, 2017[19]). As argued in Chapter 2 of this report, iterative feedback cycles are central to learning and problem-solving processes. In the context of building adequate constructs of proficiency and therefore suitable next-generation assessments of those constructs, tasks need to be able to simulate these iterative feedback loops by creating opportunities for examinees to interact with feedback and resources.
One advantage of TEA is that test taker actions and responses can be immediately registered in the digital platform and algorithms can instantly score that data. The simplest form involves solution feedback mechanisms that inform test takers about the “correctness” of their response(s); these mechanisms could be triggered on-demand via a choice-based mechanism (i.e. explicitly sought by the test taker) or automated following a particular event (e.g. submitting a solution). More detailed feedback could also be provided, for example explaining why a given response is wrong or describing the optimal solution path. In such cases, especially when followed by allowing the respondent to try to answer again, feedback then functions as a type of hint or scaffolding. Hints and scaffolding aim to break tasks down into smaller more manageable steps by giving pointed clues or guidance on what the test taker should do or by simplifying or partially completing the task at hand. In terms of the examinee experience, hint and scaffolding mechanisms can function similarly to solution feedback mechanisms via a choice-based mechanism (e.g. a hint button) or an automated action trigger (e.g. number of failed attempts, time delay, etc.).
Feedback, hints and scaffolds can be more or less “intelligent” in terms of the extent to which the support is tailored to a given student’s needs. Fixed support (i.e. non-adaptive, where every examinee receives the same support regardless of their actions or solution quality) is clearly much simpler and more cost effective to develop and ensures a greater standardisation of test experience. However, the resulting trade-off is that such support is unlikely to be useful for all (or even the majority) of test takers; this may then be counterproductive, adversely impacting test taker engagement or affective regulation (e.g. triggering anxiety) that might jeopardise the validity of test scores. In closed tasks that employ selected response types (like multiple-choice items), “intelligent” feedback can be provided through relatively simple if-then branching based on students’ responses. For example, different explanations might be provided to the test taker based on their selection of incorrect option (where each option reflects a particular or common misconception). However, for more open-ended tasks that involve interactivity and constructed responses, more complex algorithms are required that are capable of discerning solution quality and characteristics in addition to solution correctness. For example, more advanced analytical techniques may take into account sequences of prior responses or actions or may use natural language processing (NLP) to evaluate examinees’ constructed responses, formulate targeted prompts/hints to the examinee, trigger scaffolding mechanisms or identify misconceptions (see Chapter 10 of this report for more on AI-enabled feedback).
Other learning supports can be provided to test takers through information resources. These might take the form of static written resources, such as a list of formulas or an encyclopaedia entry, or could be in any of the multimedia formats now supported by TEA (e.g. videos, animations, audio). More interactive information tools could also be provided to students, for example simulated or real search engines or interactive tutorials. In many cases, information resources function similarly to hints (when sought proactively by students); however, we consider hints as a source of more targeted, task-relevant information whereas information resources and tools may be less structured, more comprehensive and may not be task specific. While information resources are potentially less disruptive than other forms of interventionist scaffolding, hints and feedback, the research on providing optional information resources is mixed with respect to who uses which types and how effectively (Inglis et al., 2011[20]). Enabling choices in the context of providing learning supports in assessment integrates an additional construct in the student model. Choice therefore needs to be reflected in the understanding of the domain and incorporated into inferences being made about examinee performance. Perhaps one way to reason about whether to provide a particular resource is to ask whether a typical individual would have these kinds of resources available when solving this type of problem outside the test environment.
A third variation of feedback and information resources during assessment is to provide examinees with conversational tools through which they can engage with an informed or more-knowledgeable other. These tools can employ scripted or intelligent agents that can serve multiple functions including: 1) providing expert knowledge, instructions or guidelines; 2) modelling responses; 3) presenting alternative or contradictory points of view; or 4) reviewing or summarising content to help test takers’ manage cognitive load. These agents may be personified via names and visuals to give examinees the illusion of interacting with specific individuals throughout the test experience and can be given specific roles within the task context (e.g. a peer student, teacher or content expert). One commonly used example in intelligent tutoring systems (ITS; see also Chapter 10 of this report) is a trialogue design in which a teacher agent and peer student agent interact with the test taker as they learn content and complete tasks, where each potential response to the examinee is scripted and a rule-based branching algorithm is used to decide on the most appropriate response the student receives (Graesser, Forsyth and Lehman, 2017[21]). In more complex ITS environments, agents can interact in more “intelligent” (i.e. non-scripted) ways with students through the AI-based analytical techniques described above. While scripted agents maximise standardisation and scalability and minimise costs, intelligent agents can provide a more authentic experience by providing personalised feedback and enabling students to freely express their ideas (rather than selecting from pre-defined responses).
It is also possible to imagine cases where human agents (e.g. trained experts) or genuine student peers can communicate with one another multi-modally (via chat affordances or videoconferencing tools) or by working collaboratively on shared objects like a simulation; in these cases, genuine interactions can also constitute adaptive individual feedback or hints. However, in the case of peer-to-peer collaborative affordances, particularly in a large-scale context, the lack of standardisation over the feedback available constitutes a key challenge for understanding and making valid inferences from the situation (i.e. the quality of support available may depend on the proficiency level of one’s peer).
With any of these feedback or resource affordances, decisions over the exact type and nature of support provided to students should ultimately be guided by the student model and the goal of assessment. For example, where the use of feedback is considered construct-relevant then assessment designers might consider it important to embed intelligent feedback mechanisms into tasks so that feedback is always useful to students. In other words, if all students receive the same feedback regardless of their solution quality at the time, then there will be some test takers for whom the feedback is not useful and who therefore cannot demonstrate the targeted skill. Similarly, where test taker choice is construct-relevant then perhaps an on-demand mechanism is appropriate; however, enabling choice may then preclude opportunities to observe such behaviours so it may be desirable to also build in some action- or event-triggered feedback mechanisms.
While any of the above elements may be warranted for inclusion in assessments tasks, especially if modelled in the domain, a further challenge comes in what scoring models to apply. As noted, research on these affordances has mostly taken place in the context of instruction. Feedback, learning supports and knowledge resources can potentially change the knowledge state of the examinee as the test proceeds therefore influencing an examinee’s performance on future test items. In contemporary psychological models that incorporate metacognition and self-regulation, and in a world where feedback is a common and likely aspect of real world problem solving, it seems appropriate that authentic test environments incorporate feedback in task design. However, in traditional psychometric thought, these might be seen as violating item independence or interfering with the existing knowledge of the examinee; doing so therefore requires creating and validating new approaches to measurement models. While some progress has been made on this front (Levy, 2019[22]), what remains is for the extensive research that has been conducted on feedback, scaffolding and resources as learning devices to be conducted in psychometric modelling for assessment design. For example, in feedback or hint models where the examinee is given more than one chance to respond, the scoring model might weight answering correctly the first time higher than requiring the hint or feedback; or it may be that reaching a correct answer – even with supports – warrants full credit. Close interaction with a psychometrics team during the assessment development process is therefore critical for understanding how inferences can be made and what inferences can be supported as measurement claims when integrating such affordances in assessment.
The final group of elements in the framework relate to the expanded sources of (potential) evidence in TEA. The palette of potential evidence now goes well beyond traditional multiple choice or constructed (written) responses that have thus far dominated in large-scale assessment: data collected via TEA can include all nature of digitised logged responses and actions that can be generated in the task formats and interactive test design features previously discussed.
One distinction that has entered the conceptual research is between response product data versus response process data (see Table 7.1). Response processes “refer to the thought processes, strategies, approaches, and behaviours of examinees when they read, interpret and formulate solutions to assessment tasks” (Ercikan and Pellegrino, 2017, p. 2[23]). Response processes also go beyond the cognitive realm, encompassing emotions, motivations and behaviours (Hubley and Zumbo, 2017[24]). Data that captures potential evidence of these response processes can therefore be understood as (response) process data; this typically includes data representing actions or sequences of actions, eye-tracking data and timing data, as well as data beyond the specific response format such as in-task chats and dialogues with agents or human collaborators. Any data that might therefore be evaluated in understanding, characterising or evidencing student’s thought processes, strategies, approaches and behaviours can be considered process data. Conversely, response products refer to students’ final responses on an assessment task or a given item. Product data therefore typically refers to data resulting from selected responses (e.g. multiple-choice items), short or extended written responses, or the final product in a simulated or performance demonstration.
The simplest form of product data is generated through selected response formats. Selected responses are typified by multiple-choice or true/false items that typically present students with pre-defined answer options (for which there is one optimal solution). Often the choices presented to students include "distractors" that might appear plausible to (some) students but should not be justifiable as a correct response. When feasible, distractors should be designed to reflect understanding of students' mental models in the content area such that students’ choice of distractors can also provide useful information about their proficiency level. Integrating some form of adaptive branching can also enable more complex selected responses whose answer options change on the basis of students’ previous selections (e.g. asking students to choose an explanation for their previous answer).
TEA designs also have the potential to make selected response type formats more engaging by re-imagining visual formats and introducing elements of test taker interactivity, for example drag-and-drop options for filling in tables or graphic arrays, identifying locations on the screen via visual mapping (hotspots), or highlighting or selecting text or objects in an array. These more interactive variations allow some degree of active response (i.e. actively rearranging elements into the correct order rather than choosing from a pre-defined list). Selected responses can also be combined in stealth ways with more interactive problem types. For example, as part of a simulation-based task a student might be required to set the parameters for conducting an experiment from a range of possible choices (i.e. they can choose all that apply in that situation). While in a real world situation there might be one "best" combination of choices, there are also likely other combinations that are partially correct. In these types of more complex and open task situations it makes sense to use a scoring rubric that rewards different combinations of selected response items with different scores.
Despite being more commonly used to produce scores than other sources of potential evidence – both due to easier interpretation and potential for automation – data generated through selected response types have some significant weaknesses in terms of validity. Because answers are (at least to some extent) pre-defined, test takers may guess the correct answer. These response types also cannot provide direct evidence of production skills. In contrast, constructed response formats necessarily require students to engage in some kind of a production activity and consequently are far less susceptible to unduly rewarding or eliciting guessing behaviours. However, constructed response formats and performance tasks require greater engagement and motivation on the part of test takers as well as generating richer data and potentially less-structured data that can be more complex to score in a reliable and comparable way. A further limitation of constructed responses is imposed by their scoring models which may take the form of rubrics or guidelines. These often restrict task design to elicit the types of responses that can be scored by rubrics or trained scorers, thus reducing the complexity of authentic tasks in order to obtain reliable and consistent expert judgments of quality.
A common constructed response type is written responses, which can range from short written words or sentences to extended essays. Advances in technology and data analytics now mean that it is increasingly possible to score written responses using techniques such as NLP coupled with machine learning, therefore reducing the burden on human scoring. For example, if a given language and region already has a community that offers software or a database for linguistics analysis (e.g. the Linguistic Data Consortium (n.d.[25]) for English, United States), syntactic analytical tools can be used to evaluate the grammaticality of short answers. In the absence of large datasets, machine learning algorithms can also be trained to identify key criteria such as semantic similarity with the answer keys.
Both written and spoken responses have typically been scored against rubrics involving expert human judges. Technological advances including improving the quality and automated transcription of audio recordings, increases in bandwidth and digital storage, and speech recognition software capabilities are converging to remove the barriers for this type of response option to be used in large-scale assessment. This an area of exponential growth stemming from advances in Artificial Intelligence (AI) but scoring any assessments – particularly those with stakes attached – using such techniques is still a work in progress.
Often the users of Machine Learning (ML) or AI-derived test scores remain wary or suspicious of machine scoring approaches, creating an extra burden on test producers to communicate results to users. It is best that any consideration of an AI-based scoring engines should be taken into account during the design stage, and that results from such assessments be properly scrutinised in terms of threats to validity of score inferences such as cross-cultural comparability (see Chapter 11 of this report for an in-depth discussion of this and other issues on cross-cultural validity of test scores from innovative assessments).
As in any assessment design process, a main consideration for test designers is whether a chosen response type (and therefore source of product data) is a valid and appropriate modality for expressing the answer to a particular task or question; and as a corollary, whether that response type would disadvantage any sub-population in comparison to alternative modalities. These considerations are not new and should be applied in the context of all choices regarding response types including the use of more “traditional” formats like multiple-choice or short written responses. What is new, however, are potential alternatives to such formats that may elicit evidence of similar aspects of constructs in different ways.
Finally, TEA enable other types of performance responses that can generate product data and constitute potential evidence of students’ proficiency in learning and problem solving. Interactive problems with tools enable students to produce complex but tangible artefacts or products. For example in specialised fields like architecture, exams have included graphical software tools that are common to the profession so that an examinee can create realistic designs in response to authentic problems. This idea can be generalised to any kind of visual, graphic, audio or computational (e.g. programming, modelling) tools available in a digital format that test takers can use to produce a tangible product for scoring. Other performance responses might include instances where test taker behaviours within an interactive or immersive problem bring about changes in the test environment (e.g. completing a level in a game or changing the state of a simulation). A key validity issue with respect to performance responses becomes one of examinee prior experience and training using the digital tools and environments provided. If one can expect that examinees should have relevant experience or that the use of tools is an inherent part of the construct (i.e. it is construct-relevant), then it is only a matter of including the appropriate tool sets. However, if the tools serve to create an environment in which performance can be demonstrated but they are not inherently a part of the target construct, then familiarity with the tool/environment is not a pre-requisite skill and appropriate tutoring or training may be necessary to ensure fairness and valid results.
One of the most significant breakthroughs of the digital age in the context of assessment is the ability to control and capture fine-grain, real time process data as the examinee completes an assessment. Process data can be exceptionally varied and the same source of data can provide potential evidence for different aspects of validity and performance. As explained in greater detail in Chapter 12 of this report, there are two major complementary challenges when using process data in assessment. First is the matter of interpretation: the sheer report and complexity of the data produced and captured by TEA, not to mention its relationship to the construct, makes valid interpretations of test takers’ behaviours and thinking processes a key concern. For example, action log data can provide information related to content (i.e. which key or affordance is selected), time (start, stop duration) and sequence of actions that may or may not reflect important information about the construct being examined.
Large-scale data analytics may be helpful with the treatment of process data but that leads to the second challenge – the matter of purpose. Process data is most likely to be of value in the design process when generated through intentional task design and in the context of understanding expected responses. Ideally, task designers would plan ahead for applying process data analytics to specific theoretically-derived hypotheses about expected patterns or strategies used by examinees approaching a task. For example, do experts take different strategic pathways from weaker examinees or novices as expected?
Emphasising the importance of theory-driven analysis is not to say that more exploratory analysis is unimportant; practically speaking, expecting a task designer to imagine all potentially valuable process data patterns a priori seems unfair and perhaps unwise. Here, exploratory research can reveal new insights, both practical and theoretical, that can feed forward into better and more efficient task designs that capture relevant interpretable data for use in evidence models. For example, are there multiple pathways to correct answers that were not originally envisaged, including some that bypass use of the target skill or construct that the task intended to measure? How do emotional responses (anxiety, boredom), engagement and motivational factors interact with performance? In closing, we note that the distinction between product and process data is relative to purpose – in other words, how the data will be used in the validation process – which again calls for close consideration of what counts as construct-relevant versus irrelevant.
In this chapter we have presented a framework for how technology can become an integral part of assessment task design. We highlighted how technologies can be applied when creating tasks, capturing new aspects of open and interactive performance environments where students can explore resources, engage in iterative processes of problem solving, and get real-time feedback on their progress. The TEA framework describes the expanded toolkit for assessment designers that stem from technological advances in the field. We organised the framework around three interrelated design issues that assessment designers must simultaneously consider: 1) task problem format (i.e. the kinds of problems and the level of interactivity that tasks present to students); 2) test features (i.e. the affordances and level of adaptivity that the test environment provides); and 3) sources of evidence (i.e. the classes of responses and the types of data that are elicited and used for scoring and interpretation). These design issues represent both a complex and simple challenge to the test designer: they are complex in that there are now many more design possibilities and tools to consider when developing coherent tasks for a given test form; yet the challenge is also simpler, in that the designer can now draw inspiration from how tasks are performed in the real world, replicating them in a measurement environment with a broad palette of technological tools at their disposal to help them enact their vision of task (and evidence) models.
[17] Azevedo, R. and V. Aleven (2013), “Metacognition and learning technologies: An overview of current interdisciplinary research”, in International Handbook of Metacognition and Learning Technologies, Springer, New York, https://doi.org/10.1007/978-1-4419-5546-3_1.
[23] Ercikan, K. and J. Pellegrino (eds.) (2017), Validation of Score Meaning for the Next Generation of Assessments, Routledge, New York, https://doi.org/10.4324/9781315708591.
[13] Fotaris, P. and T. Mastoras (2019), “Escape rooms for learning: A systematic review”, Proceedings of the 13th International Conference on Game Based Learning, https://doi.org/10.34190/GBL.19.179.
[21] Graesser, A., C. Forsyth and B. Lehman (2017), “Two heads may be better than one: Learning from computer agents in conversational trialogues”, Teachers College Record: The Voice of Scholarship in Education, Vol. 119/3, pp. 1-20, https://doi.org/10.1177/016146811711900309.
[18] Hacker, D., J. Dunlosky and A. Graesser (eds.) (2009), Handbook of Metacognition in Education, Routledge, New York, https://doi.org/10.4324/9780203876428.
[15] Harris, D. et al. (2020), “A framework for the testing and validation of simulated environments in experimentation and training”, Frontiers in Psychology, Vol. 11, https://doi.org/10.3389/fpsyg.2020.00605.
[24] Hubley, A. and B. Zumbo (2017), “Response processes in the context of validity: Setting the stage”, in Zumbo, B. and A. Hubley (eds.), Understanding and Investigating Response Processes in Validation Research, Social Indicators Research Series, Springer, Cham, https://doi.org/10.1007/978-3-319-56129-5_1.
[20] Inglis, M. et al. (2011), “Individual differences in students’ use of optional learning resources”, Journal of Computer Assisted Learning, Vol. 27/6, pp. 490-502, https://doi.org/10.1111/j.1365-2729.2011.00417.x.
[22] Levy, R. (2019), “Dynamic Bayesian Network modeling of game-based diagnostic assessments”, Multivariate Behavioral Research, Vol. 54/6, pp. 771-794, https://doi.org/10.1080/00273171.2019.1590794.
[25] Linguistic Data Consortium (n.d.), www.ldc.upenn.edu.
[9] Mayer, R., J. Heiser and S. Lonn (2001), “Cognitive constraints on multimedia learning: When presenting more material results in less understanding.”, Journal of Educational Psychology, Vol. 93/1, pp. 187-198, https://doi.org/10.1037/0022-0663.93.1.187.
[4] Mislevy, R. (2019), “Advances in measurement and cognition”, The ANNALS of the American Academy of Political and Social Science, Vol. 683/1, pp. 164-182, https://doi.org/10.1177/0002716219843816.
[3] Mislevy, R. (2018), Sociocognitive Foundations of Educational Measurement, Routledge, New York, https://doi.org/10.4324/9781315871691.
[5] Mislevy, R. and G. Haertel (2007), “Implications of Evidence-Centered Design for educational testing”, Educational Measurement: Issues and Practice, Vol. 25/4, pp. 6-20, https://doi.org/10.1111/j.1745-3992.2006.00075.x.
[2] National Academies of Science, Engineering and Medicine (2018), How People Learn II: Learners, Contexts and Cultures, National Academies Press, Washington, D.C., https://doi.org/10.17226/24783.
[1] National Research Council (1999), How People Learn: Brain, Mind, Experience and School, National Academies Press, Washington, D.C., https://doi.org/10.17226/9853.
[10] OECD (2017), “PISA 2015 collaborative problem‑solving framework”, in PISA 2015 Assessment and Analytical Framework: Science, Reading, Mathematic, Financial Literacy and Collaborative Problem Solving, OECD Publishing, Paris, https://doi.org/10.1787/9789264281820-8-en.
[8] OECD (2013), Synergies for Better Learning: An International Perspective on Evaluation and Assessment, OECD Publishing, Paris, http://www.oecd-ilibrary.org/docserver/download/9113021e.pdf?expires=1511446761&id=id&accname=guest&checksum=18A9CC493392BE9A918508D9929D29A3.
[19] Panadero, E. (2017), “A review of self-regulated learning: Six models and four directions for research”, Frontiers in Psychology, Vol. 8/422, pp. 1-28, https://doi.org/10.3389/fpsyg.2017.00422.
[12] Pellas, N. et al. (2018), “Augmenting the learning experience in primary and secondary school education: A systematic review of recent trends in augmented reality game-based learning”, Virtual Reality, Vol. 23/4, pp. 329-346, https://doi.org/10.1007/s10055-018-0347-2.
[7] Pellegrino, J., G. Baxter and R. Glaser (1999), “Addressing the “two disciplines” problem: Linking theories of cognition and learning with assessment and instructional practice”, Review of Research in Education, Vol. 24/1, pp. 307-353, https://doi.org/10.3102/0091732x024001307.
[6] Pellegrino, J., N. Chudowsky and R. Glaser (eds.) (2001), Knowing What Students Know: The Science and Design of Educational Assessment, National Academies Press, Washington, D.C.
[14] Shute, V. (2011), “Stealth assessment in computer-based games to support learning”, in Tobias, S. and J. Fletcher (eds.), Computer Games and Instruction, Information Age Publishing.
[11] Sireci, S. and A. Zenisky (2016), “Computerized innovative item formats: Achievement and credentialing”, in Lane, S., M. Raymond and T. Haladyna (eds.), Handbook of Test Development, Routledge, New York.
[16] Wainer, H. et al. (2000), Computerized Adaptive Testing, Routledge, New York, https://doi.org/10.4324/9781410605931.