Kadriye Ercikan
Educational Testing Service
Hongwen Guo
Educational Testing Service
Han-Hui Por
Educational Testing Service

Kadriye Ercikan
Educational Testing Service
Hongwen Guo
Educational Testing Service
Han-Hui Por
Educational Testing Service
Digital assessments and technological advances provide opportunities for significant innovations in assessments, including assessing complex constructs where both the solution and the response processes are important assessment targets. This chapter discusses how technology-rich assessments can capture data representing test takers’ response processes at a large scale that may provide insights on students’ knowledge and abilities and how they interact and engage with assessments. It discusses three key uses of process data captured on digital platforms during the test-taking processes, including for improving assessment design and score quality and validity, for providing evidence of the targeted construct, and for investigating group comparisons and fairness. The chapter describes each of these key uses and appropriate methodologies for optimising the use of process data in digital assessments.
Increasingly, assessment design and development are informed by and provide information about student learning processes. This is motivated by the need to understand how students learn, to align assessments with cognition models, and to provide feedback to learners and teachers. In addition, there is a growing emphasis on the importance of assessing complex constructs such as problem solving and creative thinking, which require capturing response processes in addition to the final solutions to assessment tasks. Technology-rich assessments provide opportunities for presenting items in engaging contexts that may include audio, videos, images, text, interactivity, and include other dynamic displays and digital tools. These opportunities are accompanied by advancements in data capture capabilities that allow for collecting data on response processes including eye-tracking, click streams and time stamps associated with different actions and events (also refer to Table 7.1 and Table 10.1 in Chapters 7 and 10 of this volume, respectively).
Research has demonstrated the benefits of multimedia item formats in increasing engagement as well as their potential negative impact on validity due to a multitude of cognitive demands not targeted by the assessment (McNamara et al., 2011[1]; Popp, Tuzinski and Fetzer, 2015[2]); see also Chapter 11 of this volume. Despite the potential for contributing to incomparability, digital assessment environments provide opportunities for capturing response process data that can advance measurement in significant ways from assessment design, item development, validation of score meaning and use, and for group comparisons and fairness research. Use of response process data requires interpretation of clicks, timing and other action data with respect to what they may indicate in cognitive thinking processes.
In the first section of this chapter, we discuss approaches to creating response process indicators using process data, focusing on timing data and using rapid guessing behaviour indicators as an example. This is followed by three sections highlighting three key, interrelated uses of process data (Figure 12.1): 1) to improve assessment design, quality and validity; 2) as evidence of the targeted construct; and 3) for examining differential engagement in the assessment by different groups, for score comparability and detecting construct-irrelevant variables (CIVs). The chapter ends by highlighting the importance of using process data during the initial design stages of technology-rich assessments.
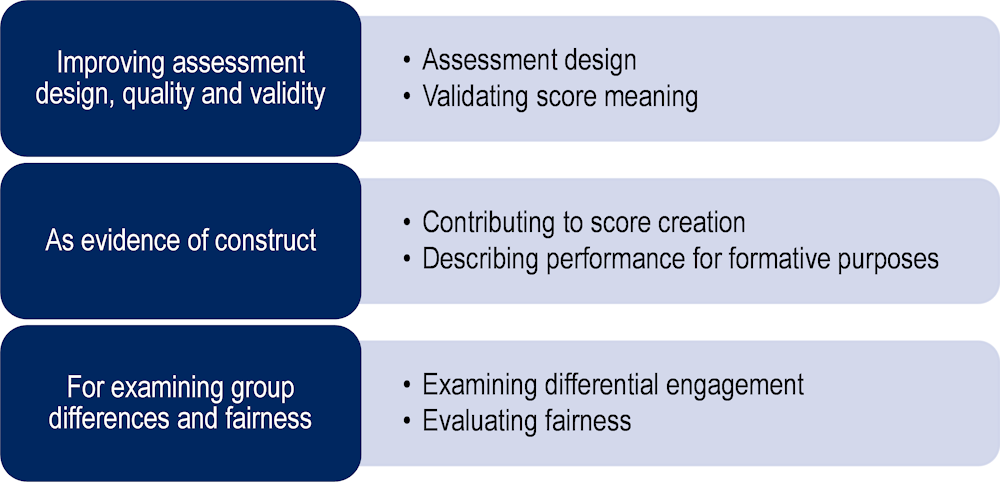
One of the key steps in utilising process data is identifying aspects of data that might be meaningful in reflecting cognitive response processes – that is, creating response process indicators. Descriptions of such indicators, inspired by Intelligent Tutoring Systems (ITS), can be found in Chapter 10 of this volume as well as reviews by Baker et al. (2019[3]) and Sottilare et al. (2013[4]). This section focuses on process indicators extracted from process data captured in educational assessments. We discuss methodologies for creating response process indicators and their uses in analysing whether students are engaging with tasks in intended ways as a valid measure of their ability or exhibiting unintended behaviours such as rapid guessing.
There are two approaches to creating such indicators: top-down and bottom-up. The top-down approach for creating process indicators is theory-guided and uses a known cognitive theory (i.e. one that experts agree upon in the literature and practice) to determine what evidence in the log data reflects students’ cognitive thinking processes and how to extract such evidence. Kroehne and Goldhammer (2018[5]) proposed a generic framework – finite state machines – to analyse log data using a top-down approach. States represent parts of a theoretically defined response process consisting of filtered and/or integrated log data. Theoretical considerations constitute the meaning of states – for example, students are expected to read the question stem and response options before providing the first response to an item set. In this example, the sequence of states decomposes the problem-solving process to provide the theoretical foundation for defining process indicators. Kroehne and Goldhammer (2018[5]) also illustrated how item-level time components, states and indicators (such as time on reading item stem, time on solving question) were extracted from log data for individual questions in an item set presented on one screen and how they could be used to explore the relationship between response times and item responses. In another study, Goldhammer et al. (2021[6]) created the item-level indicator, which reflects the construct allocation of cognitive resources and is presented by the time spent on relevant pages.
Guided by cognitive writing theories, Guo and colleagues (2019[7]; 2020[8]) also used a top-down approach to extract information from log data. They defined a priori finite states (e.g. long pause, editing, text production and global editing) extracted from keystroke data, with time stamps, in essay writing processes. Markov modelling of the state sequences and their duration times showed group differences in the writing processes when given comparable essay score distributions. Writing states can also be aggregated into process measures, such as frequencies in different writing stages, to investigate students’ writing styles (Zhang, Guo and Liu, 2021[9]). Bennett and colleagues (2021[10]) further used writing process features to create higher-level process indicators to investigate different writing styles among students with different writing proficiency.
In contrast, bottom-up or data-driven approaches involve the creation of indicators of behaviour types using exploratory data analysis methods, such as cluster analysis, data visualisation and unsupervised or semi-supervised learning. Researchers identify patterns or clusters in the data and then validate and interpret the findings against cognitive theories or external evidence (Fratamico et al., 2017[11]; Perez et al., 2017[12]). Process indicators can also be created using a combination of top-down and bottom-up approaches. Guided by cognitive theory and the data exploration literature, Greiff and colleagues (2016[13]) examined log files collected from complex problem-solving tasks. They studied three process indicators: time on task, non-interfering observation (time before the first action), and intervention frequency (interaction events with the test environment), and their relationships with performance. Their analysis of the behavioural data helped to understand students' performance.
In the following sub-section, we use the rapid guessing behaviour indicator as a concrete example to explain the creation of a process indicator. As discussed in Chapter 9 in this volume, triangulation between top-down and bottom-up approaches can provide evidence supporting the interpretation of different response processes. A similar approach that strikes a balance between guidance by theory and exploration of data was discussed by Fratamic and colleagues (2017[11]) in an adaptive learning context using interactive simulations.
It is important to highlight that indicators developed through both top-down and bottom-up approaches require validation of their intended interpretation and use, meaning theoretical and/or empirical rationales are needed to support the validity of inferences about (latent) attributes of test takers' response processes (Fratamico et al., 2017[11]; Goldhammer et al., 2021[6]). Validity of interpretation of process indicators was examined by Goldhammer and colleagues (2021[6]) using correlational and experimental validation strategies. The authors explained the process of reasoning from log data to low-level features and then process indicators as the outcome of evidence identification, where contextualising information from log data is essential. Such exploration and validation studies help build process models that can guide test development. Although it is not generally possible to develop formal process models and indicators that will account for the full range of performances and behaviours in the domain, it is often possible to develop such models for specific kinds of test tasks in the target domain in a technology-rich environment (Kane and Mislevy, 2017[14]). Validation of process indicators plays a critical role in evaluating their meaningful application in measurement.
Valid interpretation and uses of assessment results require item responses to be indicators of the targeted constructs. When students engage with items in ways that do not reflect their abilities and competencies, such behaviours may compromise validity. A primary example of such behaviours is rapid guessing. Previous research has commonly used item response time (Buchholz, Cignetti and Piacentini, 2022[15]; Wise, 2017[16]; Wise, 2021[17]) to identify rapid responding behaviours. Rapid guessing behaviour is usually identified as students' lack of meaningful engagement with an assessment situation such that they respond to assessment items rapidly without taking the time to read and fully consider the items. It is also hypothesised that, for a multiple-choice item, rapid guessing responses on average lead to a chance score, which may not reflect students' true knowledge and skills (DeMars and Wise, 2010[18]; Kroehne, Deribo and Goldhammer, 2020[19]; Schnipke and Scrams, 2002[20]; Wise, 2017[16]). In intelligent learning or tutoring systems, such effortless behaviours are relevant to exploiting hints and “gaming the system” and are associated with lower learning gains (see, for example, Baker et al. (2019[3]) and Roll et al. (2005[21])).
Many procedures have been developed to identify rapid guessing responses (Wise, 2017[16]), which use either the theory-guided (top-down) approach, data-driven (bottom-up) approach or a combination of the two (Ercikan, Guo and He, 2020[22]; Guo and Ercikan, 2021a[23]; Guo et al., 2022[24]). For example, the normative threshold (Wise, 2017[16]) method is the most widely used data-driven approach, identifying the time threshold as x% of the average item response time, where x is a numerical value determined by the researchers. Responses with response time less than the normative threshold (NT) will then be classified as rapid guessing. While convenient, when using the NT method researchers need to validate the choice of x; that is, whether flagged item responses, using the selected threshold, lead to the chance score on average.
Another example is the mixture of log normal (MLN) distributions procedure, which is a parametric version of the visual inspection approach and a data-driven approach. It assumes that the item response time distribution is bimodal, where the lower mode distribution represents rapid responding, and the upper mode distribution indicates effortful responding. The lowest point between the two modes is then chosen to be the threshold. As with the NT method, users of the MLN method need to evaluate whether the flagged responses lead to the chance score or whether they reflect responses from highly competent students. Moreover, the MLN procedure cannot be used to identify a threshold in the absence of a bimodal distribution (Guo and Ercikan, 2021a[23]; Rios et al., 2017[25]; Rios and Guo, 2020[26]). In contrast, the cumulative probability method (Guo et al., 2016[27]; Guo and Ercikan, 2021b[28]) identifies the response time threshold at which the cumulative proportion correct rate begins to be consistently above the chance rate for the studied item. By including the item correct rate (theory-guided) simultaneously with the timing distribution (data-driven), the cumulative probability procedure negates the need to separately validate whether flagged responses lead to a chance score on the studied item.
The above procedures produce item-level indicators (response time thresholds) to flag students' rapid responses on individual items on an assessment. Wise and colleagues proposed a test-level indicator for individual test takers, the response time effort (Wise, 2017[16]; Wise and Kong, 2005[29]; Hauser and Kingsbury, 2009[30]), to evaluate the overall effort on an assessment, which can be reframed as the rapid response rate for a test taker. The differential rapid responding measure was discussed with statistical significance in a large-scale assessment context (Guo and Ercikan, 2021a[23]; Rios and Guo, 2020[26]). Note that response time effort is equal to one minus the proportion of the number of rapidly responded items over the total number of items on the assessment.
Even when scores on an assessment rely on responses only (that is, scoring of final solutions to assessment tasks), process data can play an important role in improving assessment design and validating scoring meaning. This section focuses on discussing these uses of process data.
Response process data captured in digital assessments reflect how students interact with the assessment, which are traces of cognitive processes students use as they engage with assessments and "provide clues as to why students think the way they do, how they are learning, as well as reasons for any misunderstandings or gaps in knowledge and skills that may have developed along the way" (Pellegrino, 2020, p. 82[31]). Insights about response processes are particularly important in assessing complex constructs such as (collaborative) problem solving or communication, for which process is central to the construct and where examinees’ sequences of actions provide more direct data on how they reason, collaborate and interact.
Analysing process data from assessments can inform task development with respect to the interfaces, representations, task features and scoring rules, as well as clarify any confusion and the measurement of the targeted construct. Assessment design typically relies on small-scale think aloud protocols (TAP) or cognitive labs to examine how assessment tasks function with students from targeted populations. Even though such studies are necessary and critical to provide valuable information, they tend to be based on small student samples. In technology-enhanced assessments, tasks can be administered to larger samples of students, which are more likely to reveal problems that may not surface with a small sample. For example, process data provide information about how examinees engage with different aspects of the assessment, how they navigate through the test, and if they go about solving problems and responding to questions as expected by content experts and TAP findings (DiBello et al., 2017[32]; He, Borgonovi and Paccagnella, 2021[33]; Nichols and Huff, 2017[34]). Often, unexpected behaviours are revealed in large-scale studies, such as rapid guessing behaviours (Wise, 2021[17]), which are unlikely to be observed in a cognitive lab study. Process data (particularly timing data) are also used in test assembly to manage the distribution of test time across sections and minimise test “speededness” (van der Linden, 2011[35]). In addition, process data can provide important insights about the functionality and use of tools included in assessments such as spell-check, read-aloud or text-to-speech functions, dictionaries, bilingual versions, and applications like a calculator (Wood et al., 2017[36]; Jiang et al., 2023[37]).
In interpreting process data for the purpose of improving task design, it is important to note that the same performance levels may be achieved through different behaviour patterns and test-taking behaviours may have different types of associations with performance for different populations. Test-taking behaviours are associated with students' knowledge, skills and competencies targeted by the assessment, as well as with test-taking strategies and potentially their background and personal learning experiences, such as how they acquired the skills and how they prepared for the assessments (see Chapter 11 in this volume for more on score comparability). In the log data collected from a large-scale, high-stakes language test, distinct clusters were observed in test-taking behaviours regarding where and how long test takers spent their time on the test regardless of their test scores and testing modes (Guo, 2022[38]). In low-stakes assessments, test-taking behaviours are also confounded with students' test-taking motivation, strategies, cultural-language differences and other factors (Ercikan, Guo and He, 2020[22]; Guo and Ercikan, 2021a[23]; Wise, 2021[17]). Therefore, it is necessary to cross-validate different behaviour patterns in the process data with other sources (such as data from TAPs, survey questionnaires, socio-cultural context and results from different assessments) to evaluate possibilities of alternative interpretations, the impact of such differences on performance and ways to mediate or improve assessment designs, and to develop data analysis methods to consider biases introduced by sampling from diverse populations (especially heterogeneous test populations). In particular, assessments administered in multicultural contexts require validation of interpretation and use of process data and process indicators with the relevant diverse populations.
The importance of response processes in validating score meaning has been highlighted by the Standards for Educational and Psychological Testing (AERA, APA, NCME, 2014[39]). In assessments of complex skills, process data can be used to investigate whether students' test-taking behaviours are aligned with the expected cognitive processes and to examine the extent to which items and tasks engage test takers in the intended ways and therefore can provide validity evidence (Ercikan et al., 2010[40]; Kane and Mislevy, 2017[14]; Yaneva et al., 2022[41]).
There is growing research demonstrating the usefulness of process data in validating performance on assessments as indicators of the targeted constructs. Based on experts’ specified features that elicit particular components of knowledge, procedures and strategies, Carpenter, Just and Shell (1990[42]) developed production rules on the Raven’s Progressive Matrices tasks (non-verbal geometric patterns presented in a matrix) to measure analytic intelligence. In addition to response error rates, they tracked students' eye movements and collected verbal protocol data. They found that the eye-fixation data supplemented by verbal protocols distinguished between a higher scorer and a lower scorer in the ability to induce abstract relations and to dynamically manage a large set of problem-solving tasks in working memory; that is, successful solutions were largely consistent with applying the expected or intended production rules in those data and thus reflected higher analytic intelligence. Also, using eye-tracking data collected from test takers responding to multiple-choice questions, Yaneva et al. (2022[41]) investigated alternative score interpretations by applying machine learning methods. The authors evaluated the prediction powers of a machine learning model on various combinations of features and found that different eye movement patterns were associated with correct/incorrect responses. Correct responses were associated with working from the item stem to the item options, spending more time on reading the problem carefully, and a more decisive selection of a response option aligned with the intended score interpretation.
Guo and colleagues (2018[43]) studied pause events (such as inter-key intervals and intra-word duration times) extracted from keystroke log timing data. They found informative and consistent features across different prompts in essay writing processes. These low-level features reflected students' writing fluency and showed added power in predicting writing performance. The findings were consistent with research on writing cognition which showed that keyboarding skills and composition fluency contribute to essay quality, particularly writing fundamentals (Deane, 2014[44]; Deane and Zhang, 2015[45]). Furthermore, using data mining techniques, Sinharay, Zhang and Deane (2019[46]) showed that process features from writing keystroke logs predicted essay scores nearly as well as their natural language processing (NLP) features, which provided validity evidence for process features and which in turn can be used to validate scores. Similarly, Greiff and colleagues (2016[13]) found that process indicators such as time on task, non-interfering observation (observing how the problem environment behaved without any interference/actions) and intervention frequency with the test environment created from computer log files on some dynamic tasks and vary-one-thing-at-a-time (VOTAT) problem-solving strategies predicted performance, and thus enhanced score meaning.
Process data can also be used to provide information on test-taking strategies to offer insights on how test takers engaged with the assessment and the targeted assessment inferences and claims. For example, Greiff and colleagues (2016[13]) showed that time on task derived from complex problem-solving process data and performance had a complex relationship and followed an inverted U-shape relationship. Students who spent too little or too much time on the complex tasks showed overall poor performance on average. Intuitively, too little time may indicate that students were not engaged or had not fully understood the requirements of the tasks, while too much time spent might indicate exerting effort but having difficulty in solving the task, idling without engaging with the tasks or some other unexpected behaviours. He and colleagues (2021[33]) used process data to identify behavioural patterns in problem solving action sequences on interactive tasks (such as navigating through websites to search for a job) in a technology-rich environment. A process indicator was created that measured the distance or (dis)similarity between test takers' action sequences and the optimal strategies that content experts identified as the most efficient solution paths. Their results showed that test takers who followed optimal strategies were likely to obtain high scores, and thus supported score validity.
The second key use of process data is as evidence of the construct for augmenting the scoring of responses, which is particularly important for scoring interactive and simulation-based tasks where response processes are key aspects of assessing the targeted construct. These uses encompass their inclusion in the measurement model along with response data (Bennett et al., 2007[47]; Levy, 2020[48]); see also Chapter 8 of this volume.
Process data have been used in student profiles to augment performance. For example, using an Intelligent Tutoring System (ITS) for science learning, Betty’s Brain, Biswas and co-authors (2015[49]) presented an overview of research on process data. This ITS uses the learning-by-teaching paradigm. Through studying students’ actions and navigation behaviours with the system, video data and other process data, and utilising hidden Markov models, sequence mining and statistical analysis, the researchers were able to differentiate successful and unsuccessful performances and identify the sources of failure (such as lack of pre-knowledge). These results helped to reconceptualise and improve the system design and produce process indicators to cluster students into different profiles (such as frequent researchers and careful editors, strategic experimenters, confused guessers, disengaged, and engaged and efficient learners), which in turn helped to provide more informed scaffolding decisions to improve performance and student learning. Elsewhere, Guo and colleagues (2022[24]) applied several machine learning techniques such as autoencoder, unsupervised, semi-supervised and active learning on students' sequential process data such as response, timing and tool use sequences on a large-scale assessment to provide a holistic view of students’ entire test-taking processes. Without sequential information, an isolated action or event is open to multiple interpretations – for example, rapid guessing behaviours at the beginning of the test may indicate low test motivation while rapid guessing behaviour at the end of the test suggests test speededness. In their study, students were grouped into profiles such as unengaged group, low engagement group, tool play and mixed test-taking strategy group, struggling group with high tool use, high performing with regulated time and tool use, etc. Such profiles helped to contextualise students' performance, augment score reporting and generate actionable feedback for educators.
Previous research examined incorporating process data into multidimensional latent models on digital-based assessments. Response time-based indicators, speed or response time latency measure how fast test takers respond to items and are often jointly modelled with latent ability in a hierarchical model to investigate the speed-and-accuracy trade-off (van der Linden, 2007[50]; van der Linden and Fox, 2016[51]) and to detect aberrant response behaviours (van der Linden and Guo, 2008[52]). The joint model accounts for individual differences in speed when estimating ability and thus improves estimation accuracy (van der Linden, 2009[53]). Pohl and colleagues (2021[54]) extended the joint model to include the item omission propensity and speed-related process data (i.e. how often and fast they omitted items), in addition to latent ability and speed, to evaluate how process data-based indicators help to produce different profiles that reflect different aspects of performance. As Pohl and colleagues discussed, test-taking behaviours are not a nuisance factor that may confound measurement but an aspect providing important information on how test takers approach tasks. Test-taking behaviours have different relationships with performance for test takers with different backgrounds and learning experiences, which may lead to an unfair comparison of performance scores and difficulty in score interpretability. Therefore, researchers may experiment with different score reporting approaches such as reporting performance with supplementary profiles, including test-taking behaviours reflected in process data, to evaluate whether it can increase contextualisation, transparency and the valid use of assessment results.
From studies using process features, states and indicators generated from innovative assessments, new indicators based on process data have emerged to measure test takers' problem-solving processes as well as their knowledge. In particular, process data can be leveraged in technology-rich assessment environments to provide evidence of construct-relevant variables for complex constructs largely defined by processes. For example, using log files collected from an online learning system, Gobert et al. (2013[55]) applied data mining techniques on interaction features to replicate human judgement and measure whether students demonstrated science inquiry skills, which may provide real-time, automated support and feedback to students. Using simulation-based data from Harvard’s Virtual Performance Assessments (VPA), Scalise (2017[56]) applied Bayes Nets to score rich patterns in the log data and then integrated that information into multidimensional Item Response Theory (IRT) models (e.g. mIRT-Bayes) to produce scores and yield inferences (see Box 8.1 in Chapter 8 of this volume for a more detailed discussion).
Andrews and colleagues (2017[57]) used process data and performance outcomes collected from about 500 pairs of test takers on a simulation-based task to analyse interaction patterns. Interaction patterns in chat box messages were annotated manually as categorical data and a multidimensional IRT model was used to analyse test takers’ propensities toward different interaction patterns. Their results showed that different interaction patterns related to different performance outcomes and helped to conceptualise collaborative skills for assessment research. Similarly, Johnson and Liu (2022[58]) also developed a joint model that could simultaneously consider item response and process data, for example the onscreen calculator used on a mathematics assessment. A construct of the propensity of using a calculator was jointly estimated with the latent ability. Chapter 10 of this volume further showed that machine learning and Artificial Intelligence (AI) tools could be used to create features and/or indicators in collaborative tasks to augment score creation.
Note that in any assessment, the use of process data as evidence of the construct(s) critically depends on whether the assessment is designed to evoke the kind of processes that may be indicators of different levels of the targeted construct. Careful consideration of the use of process data in measurement models is necessary and their use should depend on whether their inclusion enhances the interpretation of assessment results.
The third key use of process data is to examine differential engagement and possible construct-irrelevant variation in digitally-based assessments for different student groups (refer also to Chapter 11 in this volume for cross-cultural validity and comparability research using process data). Ercikan and Pellegrino (2017[59]) discussed this type of use for examining the comparability of response processes and patterns for students from different cultural groups, albeit with caution since some aspects of process data might not be directly comparable across different cultural and language groups (Ercikan, Guo and He, 2020[22]; Guo and Ercikan, 2021a[23]; Guo and Ercikan, 2021b[28]; He, Borgonovi and Paccagnella, 2021[33]).
In examining the equivalence of measurement for different groups, response process data can be used to examine whether students are interacting with items in expected ways and whether students engage with items similarly for the comparison groups (Ercikan, Guo and He, 2020[22]; Goldhammer et al., 2014[60]; Pohl, Ulitzsch and von Davier, 2021[54]; Yamamoto, Shin and Khorramdel, 2018[61]). These explorations of how examinees from different cultural and language backgrounds engage with items are particularly important when items involve interactivity and digital tools, such as graphing tools, dictionaries and search capabilities. Response process data such as item response time and the number of actions, which are captured in the Programme for International Student Assessment (PISA) (OECD, 2019[62]), for example, can be particularly important in examining how and the degree to which students from different cultural and language backgrounds interact with the assessment tasks, which in turn can inform inferences about the comparability of measurement across groups (Ercikan, Guo and He, 2020[22]; Goldhammer et al., 2017[63]).
As discussed earlier, response processes are functions of the targeted construct as well as test-taking strategies, the test taker's exposure to curriculum and instruction, their familiarity with the assessment technology, and their cultural and language backgrounds. When responding to a complex task, students need to have both the construct-relevant knowledge, skills and abilities (KSAs) that the assessment intends to measure as well as the construct-irrelevant KSAs (such as the ability to engage with digital interactive tasks effectively) that are necessary to understand, respond to and navigate through the assessments presented (Bennett et al., 2021[10]; Mislevy, 2019[64]; Sireci, 2021[65]; Sireci and Zenisky, 2006[66]). Studies have shown that relationships between item responses, response times or actions, and the construct may vary across different cultural and language groups (Ercikan, Guo and He, 2020[22]; Guo and Ercikan, 2021a[23]; He, Borgonovi and Paccagnella, 2021[33]; Pohl, Ulitzsch and von Davier, 2021[54]). Even for students with comparable performance on assessments in the same language, different test-taking behaviour patterns have been observed in students' keystrokes on essay writing tasks, response time sequences or action sequences in logfiles (Bennett et al., 2021[10]; Guo, 2022[38]; Guo et al., 2019[7]).
Differences in behaviours uncovered by process data may contain evidence on whether score comparability has been compromised, especially when such differences might hinder students' performance on assessments only for some language or cultural groups. For example, differences in input method editors can cause students in some language subgroups to devote much more time to typing. Digital platform features adapted and developed for one language subgroup may lead students in another language group to spend time figuring out task requirements. In these cases, students lose valuable time to work on other items which may adversely impact their performance. These insights highlight the importance of collecting rich process data to examine response processes and understand the potential source of process differences and their impact on the comparability of measurements and score meaning (Ercikan, Guo and He, 2020[22]; Kroehne, Deribo and Goldhammer, 2020[19]).
As mentioned in the previous section on validating score meaning, rapid guessing behaviour has clear relevance to the interpretation of group score comparisons. Rapid response behavioural differences may be attributed to various factors including differences in assessment context and language as well as cultural and motivational factors. In addition, because of cultural and language differences, the relationships between rapid response rates and performance may differ. Recently, a few process indices have been developed to identify differential response patterns for groups of test takers matched on performance on a test, such as differential response time and differential rapid response rate, to assess and evaluate the magnitude of differences in rapid response behaviours among different cultural and language student groups (Ercikan, Guo and He, 2020[22]; Ercikan and Por, 2020[67]; Guo and Ercikan, 2021a[23]; Kroehne, Deribo and Goldhammer, 2020[19]; Rios et al., 2017[25]; Rios and Guo, 2020[26]). These methodologies can be applied to examine differential engagement in assessments by diverse student groups. It is important to note that, in addition to their possible impact on measurement comparability, differences in test-taking behaviours may provide important insights into how test takers approach and respond to assessment tasks. For example, Guo and Ercikan (2021a[23]) observed that student groups from different countries showed differential rapid response rates, even when there was ample testing time left; the lower-performing student groups showed a higher correlation between rapid response rates and performance.
Pohl and colleagues (2021[54]) showed differences in test-taking behaviours in terms of response time and item omission in different language groups. Differences in test takers’ problem solving action sequences or writing state sequences were also observed among groups (Guo et al., 2019[7]; He, Borgonovi and Paccagnella, 2021[33]; Pohl, Ulitzsch and von Davier, 2021[54]), which prompted proposals of reporting test-taking behaviours on large-scale, low-stakes assessments as part of a performance portfolio across groups for fairer comparisons, a deeper understanding of performance and tailored interventions.
Group differences in performance can indicate proficiency level differences on the targeted construct. These differences could also be due to differences in construct-irrelevant factors such as familiarity with assessment technology or cultural relevance. Given their correlation with performance, process indicators like differential engagement, if reported as supplementary information to performance scores and survey results, may help educators and policy makers to identify the source of performance differences within and between groups, such as cultural norms/attitudes toward low-stakes assessments, lack of (pre-) knowledge, learning experiences and time management. When process data are appropriately integrated into measurement models, differential process indicators can provide insights to improve educational systems as has been done in learning systems (Biswas, Segedy and Bunchongchit, 2015[49]; Baker et al., 2019[3]).
In this chapter, we have discussed different uses of process data in technology-rich assessments, from improving assessment design and validating score meaning to their uses as evidence of the targeted construct and for examining comparability and fairness for groups. We have reviewed relevant research that applied various research methodologies, from statistical and psychometric models to data mining and machine learning techniques for analysing process data for these purposes. Guided by cognitive theories, response process data including response time, action data and eye-tracking data collected during test administrations may help uncover differences in cognitive thinking processes and refine definitions of the target constructs, provide insights about sources of measurement variance, and consequently help examine score comparability and validity and improve assessment design. Findings from process data generated by technology-rich assessments can shed light on how students engage with tasks and solve problems and, eventually, help improve teaching and learning.
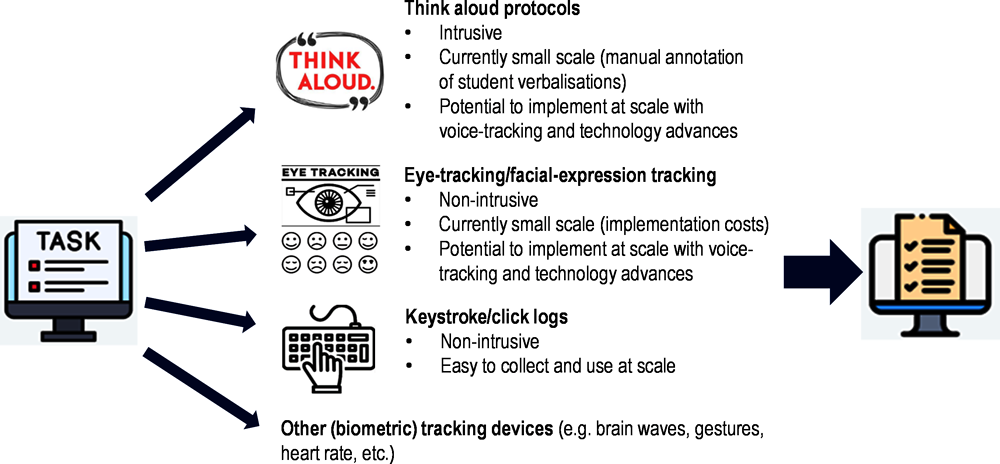
It is important to note two key considerations in using process data. First, process data as indicators of actions are only traces of students' thinking processes and require additional sources of information to help interpret these as evidence of response processes. The additional information that can help with interpretations can include data from think aloud protocols or cognitive labs (Bannert and Mengelkamp, 2008[68]; Benítez et al., 2016[69]; Ercikan et al., 2010[40]). The integration of data from multiple sources to support, validate and complement each other (for example, engagement is less likely to be an issue under watchful eyes in a cognitive lab) and to validate performance in uncovering cognitive thinking processes in mixed qualitative and quantitative methods have been used in some of the reviewed studies in this chapter (see also Table 10.1 in Chapter 10 as well as the discussion of developing the PISA 2025 Learning in the Digital World assessment in Chapter 9 of this volume, respectively). Process data such as think aloud and eye-tracking data can only be analysed at a small scale currently because of technical limitations and cost (see Figure 12.2 below). With advances in technologies and Artificial Intelligence, researchers will be able to analyse multimodal data collected from technology-enriched assessments more efficiently and effectively at large scale.
Another issue to consider in using process data is the critical dependence of response processes on personal qualities and cultural and educational contexts. For example, the sequences and speed of actions in responding to assessment tasks depend on many individual factors such as anxiety levels, pre-knowledge, and learning and testing experiences (besides the actual targeted abilities). These highlight the limitations of interpreting response processes uniformly across student populations. One strategy that can help with such interpretations is to design tasks and task features that guide engagement with tasks in ways that support the interpretation of process data in the intended ways. As highlighted in earlier parts of this chapter, to take full advantage of technology-rich assessments tasks need to be developed and designed in such ways that their characteristics, features and directives can elicit the targeted cognitive processes and problem-solving behaviours so that process indicators can be captured from process data and in turn used as empirical evidence for task design, score creation and validation, and score comparability.
[39] AERA, APA, NCME (2014), The Standards for Educational and Psychological Testing, American Psychological Association, Washington, D.C.
[57] Andrews, J. et al. (2017), “Modeling collaborative interaction patterns in a simulation-based task”, Journal of Educational Measurement, Vol. 54/1, pp. 54-69, https://doi.org/10.1111/jedm.12132.
[3] Baker, R. et al. (2019), “Culture in computer-based learning systems: Challenges and opportunities”, Computer-Based Learning in Context, Vol. 1/1, pp. 1-13, https://doi.org/10.5281/zenodo.4057223.
[68] Bannert, M. and C. Mengelkamp (2008), “Assessment of metacognitive skills by means of instruction to think aloud and reflect when prompted. Does the verbalisation method affect learning?”, Metacognition and Learning, Vol. 3/1, pp. 39-58, https://doi.org/10.1007/s11409-007-9009-6.
[69] Benítez, I. et al. (2016), “Using mixed methods to interpret differential item functioning”, Applied Measurement in Education, Vol. 29/1, pp. 1-16, https://doi.org/10.1080/08957347.2015.1102915.
[47] Bennett, R. et al. (2007), Problem Solving in Technology-Rich Environments: A Report from the NAEP Technology-Based Assessment Project, U.S. Department of Education, National Center for Education Statistics, Washington, D.C.
[10] Bennett, R. et al. (2021), “Are there distinctive profiles in examinee essay‐writing processes?”, Educational Measurement: Issues and Practice, pp. 1-15, https://doi.org/10.1111/emip.12469.
[49] Biswas, G., J. Segedy and K. Bunchongchit (2015), “From design to implementation to practice a learning by teaching system: Betty’s Brain”, International Journal of Artificial Intelligence in Education, Vol. 26/1, pp. 350-364, https://doi.org/10.1007/s40593-015-0057-9.
[15] Buchholz, J., M. Cignetti and M. Piacentini (2022), “Developing measures of engagement in PISA”, OECD Education Working Papers, https://doi.org/10.1787/19939019.
[42] Carpenter, P., M. Just and P. Shell (1990), “What one intelligence test measures: A theoretical account of the processing in the Raven Progressive Matrices Test”, Psychological Review, Vol. 97/3, pp. 404-431, https://doi.org/10.1037/0033-295x.97.3.404.
[44] Deane, P. (2014), “Using writing process and product features to assess writing quality and explore how those features relate to other literacy tasks”, ETS Research Report Series, Vol. 2014/1, pp. 1-23, https://doi.org/10.1002/ets2.12002.
[45] Deane, P. and M. Zhang (2015), “Exploring the feasibility of using writing process features to assess text production skills”, ETS Research Report Series, Vol. 2015/2, pp. 1-16, https://doi.org/10.1002/ets2.12071.
[18] DeMars, C. and S. Wise (2010), “Can differential rapid-guessing behavior lead to differential item functioning?”, International Journal of Testing, Vol. 10/3, pp. 207-229, https://doi.org/10.1080/15305058.2010.496347.
[32] DiBello, L. et al. (2017), “The contribution of student response processes to validity analyses for instructionally supportive assessments”, in Ercikan, K. and J. Pellegrino (eds.), Validation of Score Meaning for the Next Generation of Assessments, Routledge, New York.
[40] Ercikan, K. et al. (2010), “Application of think loud protocols for examining and confirming sources of differential item functioning identified by expert reviews”, Educational Measurement: Issues and Practice, Vol. 29/2, pp. 24-35, https://doi.org/10.1111/j.1745-3992.2010.00173.x.
[22] Ercikan, K., H. Guo and Q. He (2020), “Use of response process data to inform group comparisons and fairness research”, Educational Assessment, Vol. 25/3, pp. 179-197, https://doi.org/10.1080/10627197.2020.1804353.
[59] Ercikan, K. and J. Pellegrino (eds.) (2017), Validation of Score Meaning in the Next Generation of Assessments: The Use of Response Processes, Routledge, New York.
[67] Ercikan, K. and H. Por (2020), “Comparability in multilingual and multicultrual assessment contexts”, in Berman, A., E. Haertel and J. Pellegrino (eds.), Comparability in Large-Scale Assessment: Issues and Recommendations, National Academy of Education, Washington, D.C.
[11] Fratamico, L. et al. (2017), “Applying a framework for student modeling in exploratory learning environments: Comparing data representation granularity to handle environment complexity”, International Journal of Artificial Intelligence in Education, Vol. 27/2, pp. 320-352, https://doi.org/10.1007/s40593-016-0131-y.
[55] Gobert, J. et al. (2013), “From log files to assessment metrics: Measuring students’ science inquiry skills using educational data mining”, Journal of the Learning Sciences, Vol. 22/4, pp. 521-563, https://doi.org/10.1080/10508406.2013.837391.
[6] Goldhammer, F. et al. (2021), “From byproduct to design factor: On validating the interpretation of process indicators based on log data”, Large-Scale Assessments in Education, Vol. 9/1, https://doi.org/10.1186/s40536-021-00113-5.
[63] Goldhammer, F. et al. (2017), “Relating product data to process data from computer-based competency assessment”, in Leutner, D. et al. (eds.), Competence Assessment in Education: Research, Models and Instruments, Springer, Cham, https://doi.org/10.1007/978-3-319-50030-0_24.
[60] Goldhammer, F. et al. (2014), “The time on task effect in reading and problem solving is moderated by task difficulty and skill: Insights from a computer-based large-scale assessment.”, Journal of Educational Psychology, Vol. 106/3, pp. 608-626, https://doi.org/10.1037/a0034716.
[13] Greiff, S. et al. (2016), “Understanding students’ performance in a computer-based assessment of complex problem solving: An analysis of behavioral data from computer-generated log files”, Computers in Human Behavior, Vol. 61, pp. 36-46, https://doi.org/10.1016/j.chb.2016.02.095.
[38] Guo, H. (2022), “How did students engage with a remote educational assessment? A case study”, Educational Measurement: Issues and Practice, Vol. 41/3, pp. 58-68, https://doi.org/10.1111/emip.12476.
[43] Guo, H. et al. (2018), “Modeling basic writing processes from keystroke logs”, Journal of Educational Measurement, Vol. 55/2, pp. 194-216, https://doi.org/10.1111/jedm.12172.
[28] Guo, H. and K. Ercikan (2021b), “Comparing test-taking behaviors of English language learners (ELLs) to non-ELL students: Use of response time in measurement comparability research”, ETS Research Report Series 1, pp. 1-15, https://doi.org/10.1002/ets2.12340.
[23] Guo, H. and K. Ercikan (2021a), “Differential rapid responding across language and cultural groups”, Educational Research and Evaluation, Vol. 26/5-6, pp. 302-327, https://doi.org/10.1080/13803611.2021.1963941.
[27] Guo, H. et al. (2016), “A new procedure for detection of students’ rapid guessing responses using response time”, Applied Measurement in Education, Vol. 29/3, pp. 173-183, https://doi.org/10.1080/08957347.2016.1171766.
[24] Guo, H. et al. (2022), “Influence of selected‐response format variants on test characteristics and test‐taking effort: An empirical study”, ETS Research Report Series, Vol. 2022/1, pp. 1-20, https://doi.org/10.1002/ets2.12345.
[8] Guo, H. et al. (2020), “Effects of scenario-based assessment on students’ writing processes”, Journal of Educational Data Mining, Vol. 12, https://doi.org/10.5281/zenodo.3911797.
[7] Guo, H. et al. (2019), “Writing process differences in subgroups reflected in keystroke logs”, Journal of Educational and Behavioral Statistics, Vol. 44/5, pp. 571-596, https://doi.org/10.3102/1076998619856590.
[30] Hauser, C. and G. Kingsbury (2009), “Individual score validity in a modest-stakes adaptive educational testing setting”, Paper presented at the Annual Meeting of the National Council on Measurement in Education, San Diego.
[33] He, Q., F. Borgonovi and M. Paccagnella (2021), “Leveraging process data to assess adults’ problem-solving skills: Using sequence mining to identify behavioral patterns across digital tasks”, Computers & Education, Vol. 166, https://doi.org/10.1016/j.compedu.2021.104170.
[37] Jiang, Y. et al. (2023), “Using sequence mining to study students’ calculator use, problem solving, and mathematics achievement in the National Assessment of Educational Progress (NAEP)”, Computers & Education, Vol. 193, https://doi.org/10.1016/j.compedu.2022.104680.
[58] Johnson, M. and X. Liu (2022), “Psychometric considerations for the joint modeling of response and process data”, Paper presented at the 2022 IMPS International Meeting of the Psychometric Society.
[14] Kane, M. and R. Mislevy (2017), “Validating score interpretations based on response processes”, in Ercikan, K. and J. Pellegrino (eds.), Validation of Score Meaning for the Next Generation of Assessments, Routledge, New York, https://doi.org/10.4324/9781315708591.
[19] Kroehne, U., T. Deribo and F. Goldhammer (2020), “Rapid guessing rates across administration mode and test setting.”, Psychological Test and Assessment Modeling, Vol. 62/2, pp. 147-177, https://doi.org/10.25656/01:23630.
[5] Kroehne, U. and F. Goldhammer (2018), “How to conceptualize, represent, and analyze log data from technology-based assessments? A generic framework and an application to questionnaire items”, Behaviormetrika, Vol. 45/2, pp. 527-563, https://doi.org/10.1007/s41237-018-0063-y.
[48] Levy, R. (2020), “Implications of considering response process data for greater and lesser psychometrics”, Educational Assessment, Vol. 25/3, pp. 218-235, https://doi.org/10.1080/10627197.2020.1804352.
[1] McNamara, N. et al. (2011), “Citizenship attributes as the basis for intergroup differentiation: Implicit and explicit intergroup evaluations”, Journal of Community and Applied Social Psychology, Vol. 21/3, pp. 243-254, https://doi.org/10.1002/casp.1090.
[64] Mislevy, R. (2019), “Advances in measurement and cognition”, The Annals of the American Academy of Political and Social Science, Vol. 683/1, pp. 164–182.
[34] Nichols, P. and K. Huff (2017), “Assessments of complex thinking”, in Ercikan, K. and J. Pellegrino (eds.), Validation of Score Meaning in Next Generation Assessments, Routledge, New York.
[62] OECD (2019), PISA 2018 Results, https://www.oecd-ilibrary.org/education/pisa_19963777.
[31] Pellegrino, J. (2020), “Important considerations for assessment to function in the service of education”, Educational Measurement: Issues and Practice, Vol. 39/3, pp. 81-85, https://doi.org/10.1111/emip.12372.
[12] Perez, S. et al. (2017), “Identifying productive inquiry in virtual labs using sequence mining”, in André, E. et al. (eds.), Artificial Intelligence in Education. AIED 2017. Lecture Notes in Computer Science, Springer, Cham, https://doi.org/10.1007/978-3-319-61425-0_24.
[54] Pohl, S., E. Ulitzsch and M. von Davier (2021), “Reframing rankings in educational assessments”, Science, Vol. 372/6540, pp. 338-340, https://doi.org/10.1126/science.abd3300.
[2] Popp, E., K. Tuzinski and M. Fetzer (2015), “Actor or avatar? Considerations in selecting appropriate formats for assessment content”, in Drasgow, F. (ed.), Technology and Testing: Improving Educational and Psychological Measurement, Routledge, New York, https://doi.org/10.4324/9781315871493-4.
[26] Rios, J. and H. Guo (2020), “Can culture be a salient predictor of test-taking engagement? An analysis of differential non-effortful responding on an international college-level assessment of critical thinking”, Applied Measurement in Education, Vol. 33/4, pp. 263-279, https://doi.org/10.1080/08957347.2020.1789141.
[25] Rios, J. et al. (2017), “Evaluating the impact of careless responding on aggregated-scores: To filter unmotivated examinees or not?”, International Journal of Testing, Vol. 17/1, pp. 74-104, https://doi.org/10.1080/15305058.2016.1231193.
[21] Roll, I. et al. (2005), “Modeling students’ metacognitive errors in two Intelligent Tutoring Systems”, in Ardissono, L., P. Brna and A. Mitrovic (eds.), User Modeling 2005, Lecture Notes in Computer Science, Springer, Berlin, Heidelberg, https://doi.org/10.1007/11527886_48.
[56] Scalise, K. (2017), “Hybrid measurement models for technology-enhanced assessments through mIRT-bayes”, International Journal of Statistics and Probability, Vol. 6/3, pp. 168-182, https://doi.org/10.5539/ijsp.v6n3p168.
[20] Schnipke, D. and D. Scrams (2002), “Exploring issues of examinee behavior: Insights gained from response-time analyses”, in Computer-Based Testing: Building the Foundation for Future Assessments, Lawrence Erlbaum, Mahwah, https://doi.org/10.4324/9781410612250-20.
[46] Sinharay, S., M. Zhang and P. Deane (2019), “Prediction of essay scores from writing process and product features using data mining methods”, Applied Measurement in Education, Vol. 32/2, pp. 116-137, https://doi.org/10.1080/08957347.2019.1577245.
[65] Sireci, S. (2021), “How psychometricians can affect educational assessment policy: A call to action”, Presentation at the International Test Commission (ITC) Colloquium.
[66] Sireci, S. and A. Zenisky (2006), “Innovative item formats in computer-based testing: In pursuit of improved construct representation”, in Haladyna, T. and S. Downing (eds.), Handbook of Test Development, Erlbaum, Mahwah.
[4] Sottilare, R. et al. (2013), Design Recommendations for Intelligent Tutoring Systems - Volume 1 Learner Modeling, US Army Research Laboratory, Adelphi.
[35] van der Linden, W. (2011), “Test design and speededness”, Journal of Educational Measurement, Vol. 48/1, pp. 44-60, https://doi.org/10.1111/j.1745-3984.2010.00130.x.
[53] van der Linden, W. (2009), “Conceptual issues in response-time modeling”, Journal of Educational Measurement, Vol. 46/3, pp. 247-272, https://doi.org/10.1111/j.1745-3984.2009.00080.x.
[50] van der Linden, W. (2007), “A hierarchical framework for modeling speed and accuracy on test items”, Psychometrika, Vol. 72/3, pp. 287-308, https://doi.org/10.1007/s11336-006-1478-z.
[51] van der Linden, W. and J. Fox (2016), “Joint hierarchical modeling of responses and response times”, in van der Linden, W. (ed.), Handbook of Item Response Theory, CRC Press, New York, https://doi.org/10.1201/9781315374512.
[52] van der Linden, W. and F. Guo (2008), “Bayesian procedures for identifying aberrant response-time patterns in adaptive testing”, Psychometrika, Vol. 73/3, pp. 365-384, https://doi.org/10.1007/s11336-007-9046-8.
[17] Wise, S. (2021), “Six insights regarding test-taking disengagement”, Educational Research and Evaluation, Vol. 26/5-6, pp. 328-338, https://doi.org/10.1080/13803611.2021.1963942.
[16] Wise, S. (2017), “Rapid-guessing behavior: Its identification, interpretation, and implications”, Educational Measurement: Issues and Practice, Vol. 36/4, pp. 52-61, https://doi.org/10.1111/emip.12165.
[29] Wise, S. and X. Kong (2005), “Response time effort: A new measure of examinee motivation in computer-based tests”, Applied Measurement in Education, Vol. 18/2, pp. 163-183, https://doi.org/10.1207/s15324818ame1802_2.
[36] Wood, S. et al. (2017), “Does use of text-to-speech and related read-aloud tools improve reading comprehension for students with reading disabilities? A meta-analysis”, Journal of Learning Disabilities, Vol. 51/1, pp. 73-84, https://doi.org/10.1177/0022219416688170.
[61] Yamamoto, K., H. Shin and L. Khorramdel (2018), “Multistage adaptive testing design in international large-scale assessments”, Educational Measurement: Issues and Practice, Vol. 37/4, pp. 16-27, https://doi.org/10.1111/emip.12226.
[41] Yaneva, V. et al. (2022), “Assessing the validity of test scores using response process data from an eye-tracking study: A new approach”, Advances in Health Sciences Education: Theory and Practice, Vol. 27/5, pp. 1401-1422, https://doi.org/10.1007/s10459-022-10107-9.
[9] Zhang, M., H. Guo and X. Liu (2021), “Using keystroke analytics to understand cognitive processes during writing”, Virtual presentation at the International Conference of Educational Data Mining, https://educationaldatamining.org/EDM2021/virtual/static/pdf/EDM21_paper_167.pdf (accessed on 13 March 2023).