Les statistiques basées sur des modèles multiniveaux comportent les composantes de la variance (variance inter-établissements et intra-établissement), la corrélation intra-classe dérivée de ces composantes, et les coefficients de régression (lorsque indiqué). Les modèles multiniveaux du présent rapport sont des régressions à deux niveaux (le niveau « enseignant » et le niveau « établissement ») et sont estimés à l’aide de la méthode du maximum de vraisemblance.
Des pondérations sont utilisées à la fois au niveau « enseignant » et « établissement ». Le but de ces pondérations est de tenir compte des différences de probabilité de sélection des enseignants dans l'échantillon. Les pondérations finales des enseignants (TCHWGT) ont été utilisées comme pondération d’échantillonnage au niveau des enseignants. Les pondérations intra-établissement des enseignants correspondent aux pondérations finales des enseignants, rééchelonnées pour correspondre à la taille de l'échantillon dans chaque établissement. Les pondérations finales des établissements (SCHWGT) ont été utilisées comme pondération d’échantillonnage au niveau des établissements.
Les estimations basées sur les modèles multiniveaux dépendent de la manière dont les établissements sont définis et organisés au sein des pays et territoires, ainsi que des modalités de leur sélection à des fins d'échantillonnage. Dans l’échantillon TALIS, selon le pays/territoire, les établissements peuvent ainsi être définis comme : des unités administratives (même s’ils comptent plusieurs implantations géographiques différentes) ; des composantes de groupes scolaires plus larges qui accueillent des élèves au niveau CITE concerné ; des bâtiments scolaires ; ou encore des entités administratives (gérées par un chef d’établissement). L’annexe E du rapport TALIS 2018 Technical Report fournit des informations sur la manière dont les pays et territoires définissent les établissements dans leurs systèmes respectifs (OCDE, 2019[1]). En particulier, les estimations de la variance inter-établissements peuvent être affectées si les variables utilisées pour la stratification (processus visant à réduire la variation au sein des strates) sont associées à des différences entre établissements.
Les modèles logistiques multiniveaux peuvent être considérés comme des modèles à réponse latente (Gelman et Hill, 2007[6] ; Goldstein, Browne et Rasbash, 2002[7] ; Rabe-Hesketh et Skrondal, 2012[8]). Dans le présent rapport, la réponse dichotomique observée (c’est-à-dire le fait que les enseignants utilisent régulièrement ou non les technologies de l’information et de la communication [TIC] dans le cadre de leur enseignement) est supposée découler d’une réponse continue non observée ou latente qui représente la propension à utiliser les TIC à des fins pédagogiques. Si cette réponse latente est supérieure à 0, alors la réponse observée est 1 ; sinon, la réponse observée est 0 :
Les modèles linéaires multiniveaux ont été estimés à l’aide du module « mixte » de Stata (version 17.0), tandis que les modèles logistiques multiniveaux ont été estimés avec le module « melogit ».
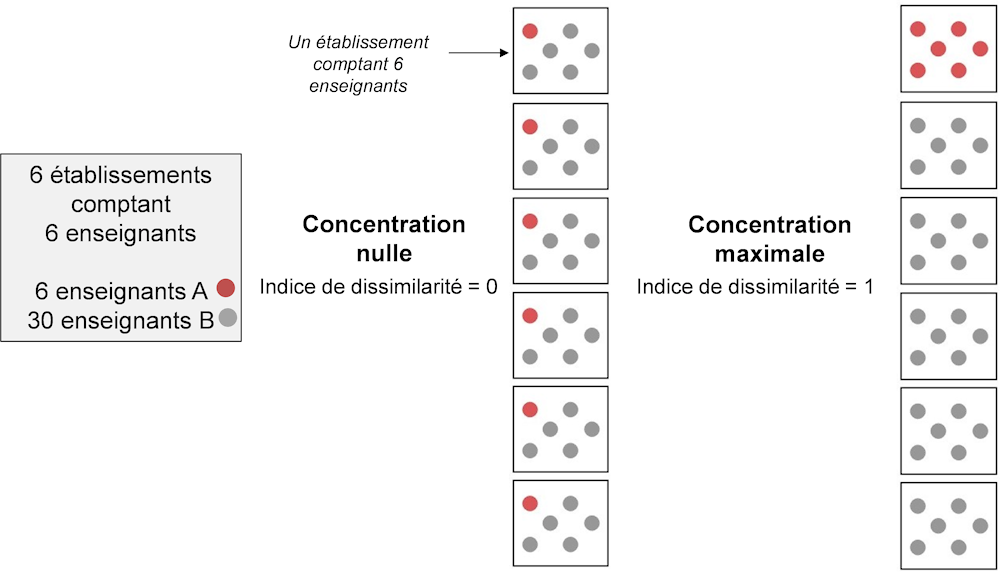
Corrélation intra-classe
L’indice de corrélation intra-classe correspond à la part de la variance située dans les établissements ; il se définit et s’estime comme suit :
où et sont respectivement la variance inter-établissements et intra-établissement estimée. Dans le cas des modèles logistiques multiniveaux, la composante de variance intra-établissement supposée (est la distribution logistique standard, c’est-à-dire . Par conséquent, l’indice de corrélation intra-classe est estimé comme suit :
Erreurs-types dans les estimations dérivées de modèles multiniveaux
Dans les statistiques dérivées de modèles multiniveaux, telles que les estimations des composantes de la variance et des coefficients de régression des modèles de régression à deux niveaux, les erreurs-types ne sont pas calculées à l’aide de la méthode habituelle de réplication, qui tient compte des taux d’échantillonnage et de la stratification des populations finies. Les erreurs-types sont en fait calculées sur la base des modèles dans l’hypothèse que l’échantillon d’établissements et d’enseignants parmi ceux qui y sont en poste est sélectionné de manière aléatoire (les probabilités d’échantillonnage étant indiquées dans le coefficient de pondération des établissements et des enseignants) dans une population infinie, théorique, d’établissements et d’enseignants, qui correspond aux hypothèses paramétriques des modèles. L’erreur-type de la corrélation intra-classe estimée est dérivée d’une distribution approximative des erreurs-types (basées sur les modèles) des composantes de la variance selon la méthode delta.