L’écosystème technologique à l’origine de toute transformation numérique se distingue par les nombreuses technologies de base qui le composent et par sa capacité à évoluer en permanence. Ce chapitre examine les caractéristiques de deux des avancées technologiques actuelles les plus prometteuses (ainsi que les opportunités et les défis qu’elles représentent) : les machines dotées de fonctions cognitives imitant le comportement humain, autrement dit l’« intelligence artificielle », et les chaînes de blocs, une technologie de base de données distribuée et inviolable.
Perspectives de l'économie numérique de l'OCDE 2017
OECD Digital Economy Outlook

Abstract
Si l’on se réfère aux 30 ou 40 dernières années d’innovation dans le secteur des technologies de l’information et des communications (TIC), il apparaît que chaque décennie fut marquée par une nouvelle forme de transformation technologique : les ordinateurs personnels dans les années 80, l’internet dans les années 90, l’informatique mobile et les smartphones dans les années 2000, et l’internet des objets (IdO) aujourd’hui. Les technologies informatiques et de réseau de base ne cessent de se développer, notamment par une miniaturisation continue des appareils, une augmentation de la puissance de calcul et des capacités de stockage pour un coût toujours plus faible, et un accès à des débits plus élevés sur les réseaux fixes et mobiles.
Les éventuels bienfaits économiques et sociaux à venir dépendent néanmoins de plus en plus de technologies particulièrement récentes qui à leur tour s’appuient sur des composantes fondamentales existantes et plus avancées, comme l’IdO, l’infonuagique, l’analytique des données massives, l’intelligence artificielle (IA) et les chaînes de blocs. Cet ensemble de technologies constitue un écosystème dans lequel chacune d’elles tire parti du développement des autres et y contribue. L’infonuagique repose sur une connectivité internet continue, disponible en permanence et à haut débit, et s’avère essentielle à l’analytique des données massives, laquelle nécessite une puissance de calcul et une capacité de stockage à la fois importantes et bon marché. Les données massives dépendent quant à elles principalement d’algorithmes complexes, sur lesquels est fondée l’IA. Pour appréhender leur environnement, qu’il soit virtuel ou physique, et prendre les décisions adaptées, les machines telles que les robots et les drones s’appuient sur une IA qui exploite souvent les données massives pour identifier les formes. Les caractéristiques de chacune de ces technologies constituent un ensemble spécifique d’opportunités et de défis qui doivent être abordés de manière séparée. Cependant, il s’avère de plus en plus nécessaire d’analyser également ces technologies dans le contexte plus large de l’écosystème numérique, sans lequel elles ne pourraient prospérer et au développement duquel elles participent.
Ce chapitre examine les caractéristiques de deux des avancées technologiques actuelles les plus prometteuses (ainsi que les opportunités et les défis qu’elles représentent) : les machines dotées de fonctions cognitives imitant le comportement humain (autrement dit l’IA) et les chaînes de blocs, une technologie de base de données distribuée et inviolable qui peut être utilisée pour conserver n’importe quel type de données, dont les transactions financières, et qui permet d’instaurer un climat de confiance dans un environnement pourtant peu fiable. Les principales conclusions de ce chapitre sont les suivantes :
L’IA se démocratise sous l’influence de l’apprentissage automatique, des données massives et de l’infonuagique, lesquels permettent aux algorithmes d’identifier des formes d’une complexité croissante dans de grands ensembles de données et parfois de surpasser les capacités humaines dans certaines fonctions cognitives. Au-delà de la promesse qu’elle offre en termes d’amélioration de l’efficacité, d’affectation des ressources et donc de stimulation des gains de productivité, l’IA a pour vocation d’aider à relever des défis complexes dans des domaines aussi divers que la santé, les transports et la sécurité.
La technologie de chaîne de blocs ne nécessite aucun opérateur intermédiaire ou autorité centrale pour être opérante. C’est notamment le cas du Bitcoin, une devise virtuelle qui constitue l’une des premières applications réussies des chaînes de blocs et fonctionne de manière indépendante de toute banque centrale. Outre le Bitcoin, les chaînes de blocs offrent de nombreuses applications possibles, y compris dans le secteur financier, le secteur public (éducation) et l’IdO, en particulier par leur capacité à atténuer les frictions sur les marchés, réduire les coûts de transaction, encourager la transparence et la responsabilisation, et garantir l’exécution des échanges par le biais de contrats intelligents.
Ce chapitre aborde également les enjeux stratégiques qui pourraient être amplifiés par le développement rapide de l’IA et des chaînes de blocs, ainsi que les nouveaux défis que pourrait engendrer l’utilisation de ces technologies. Les décideurs doivent prendre conscience de l’impact potentiel de l’IA, notamment sur l’avenir du travail et le développement des compétences, et des implications possibles en termes de transparence, de surveillance, de responsabilité, d’obligations, ainsi qu’en matière de protection et de sécurité. Parmi les défis posés par certaines applications de chaînes de blocs, citons par exemple la difficulté à neutraliser l’une de ces applications si son réseau est transnational ou encore à appliquer la législation en l’absence d’un intermédiaire principal. Cela soulève par ailleurs une question essentielle : comment et à qui imputer la responsabilité juridique des préjudices causés par les systèmes de chaînes de blocs ?
Cette section décrit en premier lieu les caractéristiques propres de l’IA et comment elle s’est démocratisée au cours des dernières années, imprégnant et transformant rapidement nos économies et nos sociétés. Par comparaison avec d’autres développements technologiques, nombreux sont surpris par la rapidité avec laquelle l’IA s’est propagée. Les avis divergent toutefois grandement quant à la faisabilité et à l’échéance de réalisation de développements tels que l’intelligence artificielle forte (IAF) et la singularité technologique.
La sous-section suivante présente les avantages et opportunités potentiels offerts par l’IA, accompagnés d’exemples d’application dans différents secteurs. L’IA offre la perspective de gains de productivité, d’une amélioration du processus décisionnel et d’une réduction des coûts, en permettant un traitement des données à très grande échelle et une découverte accélérée des formes. En aidant les chercheurs à identifier les relations complexes de cause à effet, l’IA devrait contribuer à relever des défis majeurs à l’échelle mondiale, notamment liés à l’environnement, aux transports ou à la santé. Elle pourrait améliorer de manière significative la qualité de vie par ses implications dans des domaines aussi divers que les soins de santé, les transports, l’éducation, la sécurité, la justice, l’agriculture, le commerce de détail, la finance, l’assurance ou les services bancaires. L’IA pourrait en effet trouver des applications utiles partout où l’intelligence joue un rôle essentiel.
La dernière sous-section présente quelques-unes des principales questions stratégiques posées par le développement de l’IA. Cette technologie devrait remplacer et/ou compléter certaines composantes du travail humain, qu’il soit qualifié ou non. Cela nécessite la mise en place de politiques visant à faciliter cette transition pour les professionnels et à aider les travailleurs à développer des compétences qui leur permettront à la fois de tirer parti de l’IA et de renforcer ses applications. L’IA pourrait également avoir un impact sur la concentration économique et la répartition des revenus. Un autre enjeu consiste à assurer la transparence et la surveillance des décisions basées sur l’IA qui pourraient affecter des personnes, mais aussi à empêcher une utilisation biaisée ou discriminatoire des algorithmes, ainsi que toute violation de la confidentialité. L’IA soulève également de nouvelles problématiques en termes d’obligations, de responsabilité, de protection et de sécurité.
Il n’existe aucune définition de l’IA qui soit admise de manière universelle. Marvin Minsky, pionnier dans ce domaine, la définissait comme « la science de doter les machines de la capacité à accomplir des tâches pour lesquelles les hommes utiliseraient leurs intelligence ». Le présent rapport se base sur la définition de Nils J. Nilsson (2010) : « L’intelligence artificielle est l’activité consacrée à rendre les machines intelligentes ; l’intelligence étant cette qualité qui permet à une entité d’agir de manière appropriée et avisée dans son environnement. » Les machines comprenant le langage humain, participant à des compétitions de jeux stratégiques, pilotant des voitures de manière autonome ou interprétant des données complexes sont actuellement toutes considérées comme des applications de l’IA. Dans cette acception, l’intelligence intègre l’idée d’autonomie et d’adaptabilité par la faculté de l’IA d’apprendre dans un environnement dynamique.
Il convient de noter que les frontières de l’IA ne sont pas toujours claires et qu’elles évoluent avec le temps. Par exemple, les techniques développées par les chercheurs en IA pour analyser d’importants volumes de données sont dans certains cas considérées comme des algorithmes et systèmes de « données massives » (Maison Blanche, 2016a). La reconnaissance optique de caractères est quant à elle devenue une technologie courante, ne relevant plus de l’IA. L’un des principaux objectifs de la recherche et des applications en IA est aujourd’hui devenu l’automatisation ou la reproduction d’un comportement intelligent.
Malgré une visibilité fluctuante auprès du grand public, l’IA s’est développée de manière significative depuis ses prémices dans les années 50. Son principe a été conceptualisé par John McCarthy, Alan Newell, Arthur Samuel, Herbert Simon et Marvin Minsky à l’occasion du Dartmouth Summer Research Project, un séminaire de recherche organisé durant l’été 1956 et considéré par beaucoup comme signant la naissance de l’IA. Bien que la recherche en IA ait fait des progrès constants au cours des 60 dernières années, les promesses des premiers promoteurs de cette technologie se sont révélées bien trop optimistes, donnant lieu à un grand « hiver de l’IA » caractérisé par une baisse des financements et de l’intérêt pour la recherche en IA pendant les années 70. Plus récemment, la disponibilité des données massives et l’infonuagique ont permis de réelles avancées dans une composante de l’IA appelée l’« apprentissage automatique » (Chen et al., 2012), augmentant de façon spectaculaire la puissance, la disponibilité, la croissance et l’impact de l’IA. En 2016, un programme d’IA a remporté une partie de go face à l’un des meilleurs joueurs mondiaux, un exploit que les experts ne pensaient pas possible avant au moins une dizaine d’années. La disponibilité de capacités évolutives de calcul intensif dans le nuage, et des flux et stocks de données de plus en plus importants produits par les hommes et les machines connectés ont permis des percées majeures dans l’apprentissage automatique.
Grâce à l’apprentissage automatique, les algorithmes parviennent à détecter des formes complexes dans des ensembles de données importants. Par exemple, l’IA de Google apprend à traduire des contenus vers différentes langues à l’aide des documents traduits disponibles en ligne, et l’IA de Facebook apprend à identifier les personnes figurant sur des photographies en utilisant son immense base de données d’utilisateurs connus. Les avancées dans les domaines de l’apprentissage profond et de l’apprentissage par renforcement, deux branches de l’apprentissage automatique, ont donné des résultats impressionnants depuis 2011-12.
L’efficacité des systèmes d’IA dépend également de l’utilisation de microprocesseurs spécifiques, souvent directement dans le nuage. La phase d’apprentissage des réseaux de neurones profonds s’appuie sur des processeurs graphiques à l’origine conçus pour les jeux vidéo, comme ceux développés par Nvidia. Pour la phase de réponse, les grandes entreprises spécialisées en IA développent généralement des processeurs dédiés, à l’instar de l’« unité de traitement de tenseurs » (tensor processing unit ou TPU) de Google ou du « réseau de portes programmables in situ » (field-programmable gate array ou FGPA) Altera d’Intel.
L’apprentissage automatique est notamment utilisé pour les recherches sur le web, le filtrage de contenu sur les réseaux sociaux ou les recommandations sur les sites de commerce électronique. Cette technologie est par ailleurs de plus en plus présente dans les produits de consommation, comme les appareils photo ou les smartphones. Les systèmes d’apprentissage automatique permettent d’identifier des objets dans des images, de retranscrire des paroles, de faire le lien entre des produits, publications ou actualités et les centres d’intérêt des utilisateurs, ou encore de sélectionner les résultats les plus pertinents d’une recherche.
L’apprentissage non supervisé consiste à soumettre à un algorithme d’apprentissage un ensemble de données non caractérisées (c’est-à-dire sans « bonnes » ou « mauvaises » réponses prédéterminées) afin qu’il identifie une structure dans ces données. Cela peut se traduire par le regroupement de certains types d’éléments, par exemple en examinant un lot de portraits et en apprenant à déterminer le nombre de sujets différents qui apparaissent sur ces photographies. Le service Actualités de Google utilise cette technique pour regrouper des actualités du même type, à la manière d’experts en génomique qui cherchent à identifier les différences de degré d’apparition d’un gène particulier dans une population donnée, ou de professionnels du marketing qui ciblent un public précis.
L’apprentissage supervisé consiste à exploiter un ensemble de données caractérisées pour programmer un modèle qui sera ensuite utilisé pour classer ou trier un nouvel ensemble de données inconnues (par exemple, pour apprendre à identifier une personne déterminée dans un lot de photographies). Cette technique permet de détecter des éléments précis dans des données (comme des mots-clés ou des attributs physiques), de prédire des résultats probables ou de déceler d’éventuelles anomalies ou aberrations. Pour résumer, cette approche soumet à l’ordinateur un ensemble de « bonnes réponses » et le charge d’en trouver d’autres du même type. L’apprentissage profond est une forme d’apprentissage supervisé.
Source: UK Government Office for Science (2016), « Artificial intelligence: Opportunities and implications for the future of decision-making », https://www.gov.uk/government/publications/artificial-intelligence-an-overview-for-policy-makers.
L’IA se manifeste principalement de manière immatérielle. La robotique, qui constitue un point de convergence entre le génie mécanique, le génie électrique et l’informatique, a principalement des expressions physiques. Dans une « machine autonome », l’IA assure les fonctions cognitives, alors que la robotique se charge des fonctions motrices. La frontière entre fonctions cognitives et fonctions motrices est toutefois poreuse et ne cesse d’évoluer dans la mesure où la mobilité suppose une capacité à percevoir et à analyser l’environnement. À titre d’exemple, l’apprentissage automatique joue un rôle essentiel dans la vision par ordinateur. La nature physique de la robotique la distingue toutefois de l’IA et a même des conséquences industrielles dans le cas des machines autonomes. En effet, le développement de fonctions motrices complexes est généralement plus difficile, plus cher et plus long que pour les fonctions cognitives complexes. Les véhicules autonomes et les robots humanoïdes sont des exemples bien connus de la convergence entre IA et robotique. Il est important de noter que les machines autonomes associant des techniques avancées d’IA et de robotique peinent encore à reproduire une grande partie des fonctions motrices non cognitives élémentaires.
Les neurosciences s’avèrent essentielles pour comprendre la situation actuelle de l’IA, ainsi que ses évolutions futures. Le renouveau de l’IA observé autour de l’année 2011 est en grande partie dû au succès d’une branche de l’apprentissage automatique appelée les « réseaux de neurones profonds artificiels », également connus sous le nom d’« apprentissage profond », lequel est soutenu par l’« apprentissage par renforcement », une autre branche de l’IA. L’apprentissage profond et l’apprentissage par renforcement ont pour objet d’imiter en substance les couches neuronales utilisées par le cerveau pour traiter les informations et apprendre à travers la reconnaissance des formes, même si l’apprentissage automatique reste actuellement principalement exploité dans le domaine des statistiques. L’IA et les neurosciences devraient à l’avenir converger sous une forme plus significative à mesure que la compréhension du cerveau humain s’améliore et que les technologies s’entremêlent (OCDE, à paraître).
Les algorithmes d’IA sont capables de réaliser en parallèle des calculs complexes à partir d’ensembles de données volumineux, et sont par conséquent plus rapides que l’intelligence humaine biologique. L’IA offre en outre des résultats toujours supérieurs aux capacités humaines pour certaines fonctions cognitives complexes, comme la reconnaissance d’images en radiologie (Wang et al., 2016 ; Lake et al., 2016).
L’intelligence artificielle faible ou « appliquée » actuelle est conçue pour accomplir des tâches précises de raisonnement ou de résolution de problèmes. Et ce sont là ses applications les plus avancées. Les systèmes d’IA qui sont aujourd’hui à la pointe de la technologie, comme le programme Watson d’IBM ou AlphaGo de Google, restent néanmoins des systèmes « faibles ». Bien qu’ils soient capables de généraliser dans une certaine mesure la reconnaissance de formes, notamment en transférant les connaissances acquises dans le domaine de la reconnaissance d’images vers la reconnaissance de la parole, la souplesse de l’esprit humain est incomparable.
L’IA appliquée est souvent opposée à une IA forte (hypothétique), grâce à laquelle les machines autonomes deviendraient capables de réaliser des actions intelligentes générales, comme tout être humain, et notamment d’acquérir des connaissances par généralisation ou abstraction en combinant différentes fonctions cognitives. L’IA forte serait dotée d’une puissante mémoire associative et de capacités de discernement, de décision, de résolution de problèmes multidimensionnels, d’apprentissage empirique ou par la lecture, de création de concepts, de perception du monde, de conscience de soi, d’inventivité, de créativité, de réaction à des événements inattendus dans des environnements complexes et d’anticipation.
Les avis divergent grandement face à cette potentielle IA forte et les experts invitent à la prudence : ces débats doivent rester réalistes sur sa faisabilité dans le temps. D’après les projections réalisées par les rares informaticiens engagés dans la recherche en IA forte, cette technologie devrait apparaître à l’échéance d’une dizaine d’années à un siècle ou plus (Goertzel et Pennachin, 2006). Certains mettent en avant que l’IA, à l’image de l’intelligence biologique, reste par nature contrainte par ce que les experts en informatique appellent la « combinatoire », soit le nombre incalculable de choses auxquelles un système intelligent peut penser ou qu’il peut réaliser (OCDE, 2016). Par ailleurs, l’IA étant une construction artificielle, les systèmes d’IA se basent sur des architectures qui en limitent de fait les connaissances et les actions potentielles en fonction de leur pertinence pour une application donnée. La convergence de l’apprentissage automatique et des neurosciences au cours des prochaines décennies devrait avoir des répercussions majeures.
Dans leur grande majorité, les experts s’accordent à dire que l’IA faible sera source de nouveaux risques, défis et opportunités notables, et que l’avènement possible d’une IA forte, peut-être avant la fin du XXIe siècle, devrait encore amplifier ces répercussions.
L’expression « singularité technologique » se rapporte à un scénario à long terme, théorique mais cohérent, popularisé par Ray Kurzweil, un inventeur et futurologue devenu directeur de l’ingénierie chez Google. Dans ce scénario, l’émergence d’une IA forte entraînerait une « explosion d’intelligence » et, à l’horizon de quelques décennies ou moins, donnerait lieu à la naissance d’une superintelligence artificielle (SIA). Une telle SIA serait capable d’améliorer ses propres capacités de manière exponentielle et représenterait alors une menace pour l’humanité.
Ces deux scénarios d’IA forte et de SIA ne seront pas pris en considération dans les sections suivantes. L’expression « intelligence artificielle » se rapporte ici à l’association d’algorithmes d’apprentissage automatique avec des capteurs et autres programmes informatiques afin de percevoir, comprendre et agir sur l’environnement, apprendre par expérience et s’adapter sur la durée. Les algorithmes de vision par ordinateur et de traitement audio par exemple, perçoivent le monde de manière active par l’acquisition et le traitement d’images, de sons et de langage parlé. Ils sont généralement utilisés pour des applications de type reconnaissance faciale ou de la parole. La traduction est une application caractéristique du traitement automatique du langage naturel et des moteurs d’inférence. Les systèmes d’IA peuvent également réaliser des actions cognitives comme la prise de décision (pour accepter ou refuser une demande de crédit, par exemple) ou l’exécution d’actions dans le monde physique (pour l’assistance au freinage d’un véhicule notamment).
L’IA suscite aussi bien l’intérêt des géants du numérique que des start-ups. Les entreprises multinationales réorientent leur modèle économique vers l’analyse prédictive et des données afin d’accroître leur productivité grâce à l’IA, notamment en République populaire de Chine (ci-après, la « Chine »), en France, en Israël, au Japon, en Corée, en Fédération de Russie, au Royaume-Uni et aux États-Unis. Le marché de l’IA est dominé par une douzaine d’entreprises multinationales américaines, regroupées sous le sigle GAFAMI (Google, Apple, Facebook, Amazon, Microsoft et IBM), et chinoises, surnommées BATX (Baidu, Alibaba, Tencent et Xiaomi) (OCDE, 2017). La commercialisation des technologies d’IA sous la forme de « logiciels-services » ou SaaS (software-as-a-service) semble connaître une certaine popularité. Google et IBM par exemple ont adopté ce modèle économique en fournissant un accès par abonnement à leur IA centralisée.
Le volume de données auquel les entreprises ont accès constitue un facteur clé de réussite dans la concurrence mondiale que se livrent ces plateformes. Les algorithmes d’apprentissage automatique nécessitent actuellement d’importants volumes de données pour permettre une reconnaissance efficace des formes. À titre d’exemple, la reconnaissance d’images suppose de disposer de millions d’images d’un animal ou d’un véhicule spécifique. Les données générées par les utilisateurs, les consommateurs et les entreprises contribuent à éduquer les systèmes d’IA. Facebook tire parti de près de 10 milliards d’images publiées chaque jour par ses utilisateurs pour améliorer en permanence ses algorithmes de reconnaissance visuelle. De la même manière, Google DeepMind utilise les séquences vidéo chargées par les utilisateurs de YouTube pour éduquer son logiciel d’IA à reconnaître les images vidéo.
De leur côté, les start-ups ne sont pas moins dynamiques. Une étude de CB Insights (2017) montre que les fonds soulevés par les start-ups spécialisées en IA sont passés de 589 millions USD en 2012 à plus de 5 milliards USD en 2016. Cette même année, près de 62 % des contrats étaient confiés à des start-ups américaines, contre 79 % quatre ans auparavant. Viennent ensuite les start-ups situées au Royaume-Uni, en Israël et en Inde. On estime que d’ici à 2020 le « marché de l’IA » représentera jusqu’à 70 milliards USD.
L’IA devrait améliorer de manière significative l’efficacité des processus décisionnels, engendrer des réductions de dépenses et permettre une meilleure affectation des ressources dans tous les secteurs de l’économie grâce à ses capacités de détection des formes dans d’immenses volumes de données. Les algorithmes spécialisés dans l’exploration des données liées aux opérations de systèmes complexes favorisent l’optimisation dans des secteurs aussi variés que l’énergie, l’agriculture, la finance, les transports, les soins de santé, la construction, la défense et le commerce. Grâce à l’IA, les acteurs privés ou publics ont la possibilité d’exploiter plus efficacement leurs différents facteurs de production (ressources naturelles, main-d’œuvre, capitaux ou informations) et d’optimiser leur consommation de ressources (énergie ou eau, par exemple). Ses algorithmes d’IA ont permis à Google de réduire la consommation d’énergie de ses centres de données selon des modalités que l’intuition humaine et l’ingénierie n’avaient jusque-là jamais envisagées (Evans et Gao, 2016). Au cours d’une expérience menée sur une période de deux ans, le réseau de neurones profonds artificiel de Google, DeepMind, a analysé le fonctionnement d’un centre de données sur la base de plus de 120 paramètres et identifié une méthode globale de refroidissement et de consommation électrique à la fois plus efficace et plus flexible. Cette méthode a permis à l’entreprise de réduire la consommation d’énergie de ses centres de données (déjà à haute efficacité énergétique) de 15 % supplémentaires (Evans et Gao, 2016). DeepMind laisse entrevoir des applications destinées à améliorer l’efficacité de la conversion des centrales électriques ou à réduire les quantités d’énergie et d’eau nécessaires pour les semi-conducteurs.
L’IA permet une réduction des dépenses liées à l’élaboration de prévisions par l’évaluation du profil de risques, la gestion des inventaires et l’anticipation de la demande. Les prévisions assistées par IA dans les domaines de la banque, de l’assurance, des soins préventifs, de la maintenance, de la logistique ou encore de la météorologie s’avèrent de plus en plus fiables et abordables. Des entreprises telles qu’Ocado et Amazon s’appuient sur l’IA pour tirer le meilleur parti de leurs réseaux de distribution et d’entreposage, déterminer les itinéraires de livraison les plus efficaces et exploiter au mieux leurs entrepôts. Dans le secteur des soins de santé, les données issues de smartphones et de bracelets d’activité peuvent être analysées dans l’optique d’améliorer le suivi d’affections chroniques, mais aussi d’anticiper et de prévenir les crises potentielles. IBM envisage d’utiliser son programme Watson pour détecter plus rapidement l’apparition de maladies de type Huntington, Alzheimer ou Parkinson en exploitant les outils d’analyse automatique de la parole disponibles sur les appareils mobiles.
L’apprentissage automatique est actuellement utilisé pour identifier des comportements criminels ou frauduleux et assurer le respect de la conformité par le biais de méthodes innovantes. La détection des fraudes est en réalité l’une des premières applications de l’IA dans le secteur bancaire. L’activité des comptes est surveillée afin de détecter d’éventuels comportements suspects et un contrôle est déclenché en cas d’anomalie. Grâce aux progrès de l’apprentissage automatique, cette surveillance commence à être possible en temps quasi réel. Les banques sont particulièrement attentives à cette problématique. En 2016, le Credit Suisse Group AG s’est associé sous la forme d’une entreprise commune spécialisée en IA avec une société de surveillance de sécurité de la Silicon Valley dont les solutions aident les banques à détecter les échanges commerciaux non autorisés (Voegeli, 2016).
Les technologies d’IA interviennent également de plus en plus dans les opérations de police et de lutte antiterroriste. L’organisation américaine IARPA (Intelligence Advanced Research Projects Activity) travaille sur plusieurs programmes visant à traiter d’importants volumes de données multidimensionnelles (photos et vidéos) provenant de tous les appareils disponibles, afin d’identifier des personnes recherchées. Ces programmes s’appuient sur l’IA pour dépasser les méthodes courantes de reconnaissance d’images bidimensionnelles, ou encore pour identifier des individus et géolocaliser automatiquement des vidéos suspectes non marquées publiées en ligne.
La véracité des actualités et donc des « fake news » (informations truquées) est un autre sujet sur lequel l’IA peut démontrer son utilité en analysant les données des milliers de milliards de messages d’utilisateurs. Facebook, le géant des réseaux sociaux, développerait actuellement un système visant à identifier les fake news en fonction des types d’articles signalés par le passé comme relevant de la désinformation par les utilisateurs.
L’IA devrait participer à la génération de gains de productivité dans de nombreux secteurs, à la fois par l’automatisation d’opérations auparavant manuelles et par l’autonomisation des machines, autrement dit par la capacité des systèmes à fonctionner et à s’adapter aux variations contextuelles avec une intervention humaine réduite, voire nulle (OCDE, 2017). L’exemple le plus connu de machines autonomes est celui des voitures sans conducteur, mais leurs applications sont multiples : opérations financières automatisées, systèmes de curation de contenu automatisés ou encore systèmes capables de détecter et corriger les failles de sécurité.
Parce qu’elle permet l’automatisation de tâches cognitives et physiques complexes, l’IA offrirait des gains de productivité aussi bien dans les usines que dans les centres de service ou les bureaux. L’IA peut automatiser et hiérarchiser les tâches opérationnelles et administratives répétitives en éduquant des logiciels robots conversationnels (ou « bots »). Le programme Smart Reply de Google génère des propositions de réponse en fonction des réponses précédemment envoyées à des courriels similaires. Les rédactions utilisent de plus en plus l’apprentissage automatique pour créer des rapports et préparer des ébauches d’article. Ces applications s’appuient sur une intervention humaine limitée à une approbation finale, ce qui se traduit par une augmentation de la productivité des personnes concernées. Les robots équipés de capteurs lasers et de profondeur 3D, et de réseaux de neurones profonds avancés de vision par ordinateur, peuvent désormais œuvrer en toute sécurité au milieu du personnel d’une usine ou d’un entrepôt. L’IA permet également d’augmenter la productivité en réduisant les coûts associés au traitement de grands ensembles de données. Dans le secteur juridique, des entreprises telles que ROSS, Lex Machina, H5 ou CaseText utilisent le traitement automatique du langage naturel pour rechercher des informations spécifiques dans un corpus de documents, passant ainsi en revue des milliers de pages en l’espace de quelques jours contre plusieurs mois auparavant.
Différents instituts de sondages ont récemment cherché à prévoir l’impact de l’IA sur la croissance économique et la productivité. Purdy et Daugherty (2016) ont étudié 12 économies développées et conclu que l’IA pourrait doubler le taux de croissance annuel de ces pays et augmenter la productivité de leur main-d’œuvre jusqu’à 40 % d’ici à 2035. Le McKinsey Global Institute a estimé que l’automatisation, à la fois par le biais de l’IA et de la robotique, pourrait améliorer la productivité mondiale de 0.8 % à 1.4 % par an.
Les progrès de l’IA dans le domaine des soins de santé devraient améliorer le traitement de maladies et la délivrance de médicaments, non seulement en participant à la détection rapide des affections, mais aussi (associés aux flux de données médicales disponibles en constante augmentation) en contribuant au développement de traitements médicaux préventifs et de précision. L’IA permet un dépistage précoce des maladies, notamment grâce à la reconnaissance d’images dans des spécialités comme la radiographie, l’échographie, la tomographie par ordinateur et l’imagerie par résonance magnétique. Grâce au programme Watson d’IBM, une équipe de médecins de l’Université de Tokyo a réussi à diagnostiquer chez un patient japonais une forme rare de leucémie qu’aucun médecin n’avait jusque-là détectée. Dans le cas des mammographies de dépistage du cancer du sein, les algorithmes d’apprentissage profond associés à une intervention de médecins pathologistes ont permis de faire baisser le taux d’erreur à 0.5 % par rapport au taux atteint par les pathologistes seuls (3.5 %, soit une réduction de 85 %) ou par les machines seules (7.5 %) (Nikkei, 2015).
De nouvelles avancées en apprentissage automatique devraient également stimuler la découverte et le développement de nouveaux médicaments par l’exploration de données et de publications scientifiques. Les services de santé personnalisés et les outils d’accompagnement individualisé disponibles sur les smartphones commencent déjà à comprendre et intégrer différents ensembles de données sur la santé des utilisateurs. Dans le secteur des soins aux personnes âgées, les applications du traitement automatique du langage naturel et des dispositifs d’assistance visuelle et auditive (comme les exosquelettes ou les déambulateurs intelligents) devraient jouer un rôle prépondérant.
L’intégration de l’IA a déjà un impact majeur sur les transports avec l’apparition des dispositifs de conduite autonome et du calcul d’itinéraires en fonction des données de circulation. Le développement des réseaux de neurones profonds est l’un des principaux facteurs qui ont favorisé les avancées impressionnantes réalisées sur le front des véhicules autonomes au cours des dix dernières années, notamment grâce à la vision par ordinateur. Associés à de nombreux autres types d’algorithmes, les réseaux de neurones profonds ont la capacité de tirer pleinement parti des capteurs sophistiqués utilisés pour la navigation et d’apprendre à piloter dans des environnements complexes. Cela se traduit par une baisse du nombre d’accidents de la route et par une meilleure utilisation des temps de trajet à des fins productives, de divertissement ou de repos pour les utilisateurs. Bien que l’on ignore encore quelle forme prendra l’industrie automobile après sa restructuration et à quelle échéance, beaucoup estiment que les véhicules autonomes et connectés pourraient permettre d’éviter une grande partie des 1.3 million de victimes de la route dénombrées chaque année dans le monde. Bousculés par l’arrivée de nouveaux acteurs comme Google, Baidu, Tesla et Uber, les géants de l’automobile, comme Ford Motors ou Honda, se sont mis à investir dans des start-ups prometteuses spécialisées dans l’IA, à nouer des alliances ou à développer des solutions en interne.
L’IA se révèle particulièrement efficace contre les cyber-attaques et l’usurpation d’identité par le biais de l’analyse des tendances et des anomalies. Elle est également utilisée dans le secteur de la défense contre les pirates, ainsi que dans l’élaboration de réponses proactives et immédiates aux tentatives de piratage. Le concours Cyber Grand Challenge organisé en août 2016 par l’organisation DARPA (Defense Advanced Research Projects Agency), consistant à utiliser des systèmes d’IA pour porter des attaques et se défendre en temps réel, fut une étape importante pour la cyberdéfense automatisée puisque d’après la DARPA il en aurait défini le concept même. L’IA offre une gamme étendue d’applications de sécurité ne se limitant pas à la cybersécurité. Elle constitue en effet un puissant outil d’identification pour les services de police (notamment grâce à la reconnaissance faciale qui exploite d’importants réseaux de caméras de surveillance), mais permet aussi de plus en plus d’anticiper les lieux et moments où des crimes se produiront. Certaines start-ups créées dans le but de tirer parti des résultats de la recherche universitaire utilisent notamment l’IA pour détecter les tentatives de tromperie dans des écrits. Ce type de technologie pourrait avoir de nombreuses applications, comme le renforcement de la protection des mineurs sur le web (Dutton, 2011). Dans le cas de la gestion des crises et des catastrophes, l’IA pourrait permettre une optimisation de la planification et du déploiement des ressources par les organismes de secours, les agences internationales et les organisations non gouvernementales.
De plus en plus, les pays développent des stratégies nationales d’IA ou font de cette technologie un composant majeur de plans numériques nationaux plus larges. L’Allemagne, la Chine, la Corée, les États-Unis, la France, le Japon, et le Royaume-Uni ont élaboré ou développent actuellement des initiatives et des programmes relevant de l’IA qui intègrent la robotique et autres secteurs complémentaires. Néanmoins, de manière générale, les décideurs et le grand public commencent seulement à envisager les répercussions possibles de l’IA dans les années à venir, et la vitesse à laquelle l’IA pénètre nos économies et la société peut parfois être sous-estimée.
À l’occasion de la réunion des ministres des TIC du G7 à Takamatsu (Japon) en 2016, les pays participants ont validé une proposition de Mme Takaichi, ministre japonaise de l’Intérieur et des Communications, visant à réunir toutes les parties prenantes afin d’aborder les problèmes sociaux, économiques, éthiques et juridiques relatifs à l’IA, et d’établir des principes généraux pour son développement (Encadré 7.2).
Au cours du premier semestre 2016, le ministère japonais de l’Intérieur et des Communications a réuni des experts des domaines de la science et des technologies, et des sciences humaines et sociales, afin de débattre des problèmes liés au développement des « réseaux d’intelligence artificielle », autrement dit de systèmes d’IA interconnectés coopérant les uns avec les autres.
Ces échanges défendaient la notion de « société des réseaux de savoir » (wisdom network society), une société axée sur l’humain et fondée autour de l’IA dans laquelle chacun pourrait créer, diffuser et connecter des données, des informations et des connaissances, librement et en toute sécurité. Ces réseaux de savoir constitueraient une intégration harmonieuse entre intelligence artificielle et intelligence humaine par une mise en réseau de l’IA, et permettraient de relever les défis les plus complexes. Lors de ces débats, les experts ont examiné les répercussions et défis sociaux et économiques entraînés par les réseaux d’IA dans 16 secteurs différents à l’horizon des années 2040.
Depuis octobre 2016, le ministère coordonne les discussions au Japon en vue d’établir les principes fondateurs de la recherche et du développement (R-D) dans le domaine de l’IA, et d’étudier les répercussions et les risques de cette technologie. Le ministère incite aujourd’hui activement à une coopération internationale en matière d’IA et sollicite l’intervention de toutes les parties prenantes.
Sur le front de la R-D en IA, le ministère a souligné l’importance des facteurs suivants : 1) la transparence, soit la capacité à expliquer et contrôler le fonctionnement des réseaux d’IA ; 2) l’assistance aux utilisateurs, soit la garantie que les réseaux d’IA aident réellement les utilisateurs et leur offrent les moyens opportuns de faire des choix avisés ; 3) le contrôle humain, soit la possibilité pour les personnes de vérifier la bonne utilisation de l’IA, d’en prendre le contrôle rapidement en cas de besoin (notamment en cas d’urgence) et de déterminer la part de l’IA dans la prise de décision et l’exécution d’actions ; 4) la sécurité, soit la capacité à assurer la résistance et la fiabilité des réseaux d’IA ; 5) la protection, soit la garantie que les réseaux d’IA ne présentent aucun danger pour la vie ou l’intégrité physique des utilisateurs ou des tiers ; 6) la confidentialité, soit l’assurance du respect de la vie privée des utilisateurs ou des tiers ; 7) l’éthique, soit le respect de la dignité et de l’autonomie des personnes ; 8) la responsabilisation ; et 9) l’interopérabilité ou l’interconnexion, soit la garantie de la compatibilité entre les systèmes d’IA ou les réseaux d’IA.
Sur la base de ces échanges, le gouvernement japonais réfléchit à la nécessité de directives spécifiques sur l’utilisation et les applications de l’IA.
Source: OCDE (2016), « Summary of the CDEP Technology Foresight Forum: Economic and Social Implications of Artificial Intelligence », http://oe.cd/ai2016.
Par ailleurs, le Conseil ministériel japonais pour la Science, la Technologie et l’Innovation a contribué à la coordination de la politique de la « Société 5.0 » lancée en mars 2017. Cette politique axée sur l’humain est destinée à aider le Japon à tirer profit des opportunités créées par l’IA tout en limitant les risques et en définissant les limites des processus de prise de décision automatisés.
À la suite d’une initiative inter-agences menée aux États-Unis, un rapport intitulé « Preparing for the future of artificial intelligence » (Se préparer à l’avenir de l’intelligence artificielle) a été publié en 2016, accompagné d’un plan stratégique national de développement et de recherche en intelligence artificielle. Ces documents décrivent en détail les mesures qui permettraient au gouvernement fédéral américain d’utiliser l’IA pour stimuler le bien-être social et améliorer les activités gouvernementales, adapter la législation de sorte à promouvoir l’innovation tout en protégeant le public, garantir que les applications de l’IA (même non réglementées) sont régulières, sécurisées et maîtrisables, développer une main-d’œuvre qualifiée et polyvalente, et s’attaquer à la question de l’IA dans l’armement.
En mai 2016, le gouvernement chinois a dévoilé un plan national d’IA sur trois ans, élaboré en collaboration avec la Commission nationale pour le développement et la réforme, le ministère des Sciences et des Technologies, le ministère de l’Industrie et des Technologies de l’information, et l’Administration chinoise du cyberespace. Le gouvernement espère parvenir à la création d’un marché de 15 milliards USD d’ici à 2018 en investissant dans la recherche et en soutenant le développement d’une industrie nationale de l’IA. En 2016, le nombre de publications annuelles sur l’« apprentissage profond » comptées en Chine a dépassé celui des États-Unis, ce qui reflète bien la priorité que donne de plus en plus ce pays à la recherche sur l’IA.
Différents partenariats et initiatives voient le jour dans l’optique de promouvoir une IA éthique et tenter de prévenir de potentiels effets négatifs. À titre d’exemple, OpenAI est une association de recherche à but non lucratif en intelligence artificielle fondée fin 2015 qui emploie aujourd’hui 60 chercheurs à temps complet, avec pour mission de « concevoir une IA forte sécurisée et garantir que ses bienfaits sont répartis de manière aussi large et équitable que possible »2 . En avril 2016, l’organisation de normalisation IEEE Standards Association a lancé son initiative pour l’éthique des systèmes autonomes (Global Initiative for Ethical Considerations in the Design of Autonomous Systems) afin de réunir différents acteurs des communautés de l’IA et des systèmes autonomes, et « faire en sorte que ces technologies soient en phase avec les valeurs morales et les principes éthiques des humains ». En septembre 2016, Amazon, DeepMind/Google, Facebook, IBM et Microsoft se sont associés pour lancer un partenariat pour une intelligence artificielle au service des individus et de la société (Partnership on Artificial Intelligence to Benefit People and Society) visant à permettre au public de mieux comprendre les technologies d’IA et à élaborer les meilleures pratiques face aux défis et opportunités qu’elles représentent3 .
Les répercussions de l’IA sur l’emploi représentent un enjeu stratégique très largement débattu. L’IA devrait amplifier de manière significative les tendances de restructuration du marché du travail dues à l’automatisation, tel qu’abordé au Chapitre 5, dans la mesure où les machines dotées de fonctions d’IA sont capables de remplacer ou de démultiplier les capacités humaines à de très nombreux postes et dans différents secteurs et chaînes de valeur. Il est difficile de savoir si cela se traduira par une augmentation des revenus et la création de nouveaux types d’emplois venant remplacer les postes automatisés, ou si cela entraînera une vague de licenciements. Différentes études menées au cours des cinq dernières années sur les conséquences générales de l’automatisation du travail présentent des résultats contrastés dans leurs évaluations et dans leurs prévisions (Arntz, Gregory et Zierahn, 2016 ; Frey et Osborne, 2013 ; Citibank, 2016).
L’impact de l’IA dépendra également de la vitesse du développement et de la pénétration des technologies d’IA dans les différents secteurs d’activité au cours des prochaines décennies. D’après le Forum international des transports (FIT) par exemple, la présence de camions autonomes sur le réseau routier pourrait se banaliser dans les dix ans à venir, provoquant de fait la suppression à grande échelle de postes de chauffeur routier en cas de déploiement rapide des camions autonomes. La mise en circulation de ces véhicules autonomes pourraient contribuer à l’amélioration de la sécurité routière, la réduction des émissions et la baisse des dépenses opérationnelles du transport routier à hauteur de 30 %. Cette baisse serait principalement due aux économies réalisées sur les coûts de main-d’œuvre qui représentent actuellement une part de 35 % à 45 % des coûts totaux, mais aussi à une exploitation plus intense du parc de véhicules (FIT, 2017). En 2016, la Maison Blanche a estimé à entre 2.2 et 3.1 millions le nombre d’emplois à temps partiel ou complet qui pourraient être menacés aux États-Unis par les véhicules autonomes dans les 20 prochaines années (Maison Blanche, 2016b).
Les emplois potentiellement menacés ne se limitent pas aux postes peu qualifiés ou de production. En effet, de nombreux emplois requérant des compétences cognitives de moyen à haut niveau pourraient également disparaître. Des recherches préliminaires laissent présager que l’IA pourrait affecter les emplois basés sur des compétences cognitives comme la lecture, l’écriture et le calcul, autrement dit les savoirs fondamentaux au cœur de l’éducation obligatoire (Elliot, 2014). Les technologies d’apprentissage automatique représenteraient la menace la plus sérieuse pour les professions nécessitant de hauts niveaux de qualifications (Encadré 5.1). Ainsi, les algorithmes de traitement des images et de reconnaissance des formes commenceraient à avoir des répercussions sur l’activité des radiologues. Comme décrit précédemment, les applications de reconnaissance des formes offrent des résultats de plus en plus probants dans la détection des problèmes de santé par l’identification des anomalies sur les radiographies, les échographies ou les images obtenues par résonance magnétique. Les applications de l’apprentissage automatique dans les domaines de la reconnaissance de la parole, du traitement automatique du langage naturel ou de la traduction automatique devraient avoir des répercussions sur la demande de prestations comme la traduction ou les services juridiques et de comptabilité.
Parmi les questions stratégiques à l’étude concernant l’impact de l’IA sur l’emploi, figurent les avantages d’une adaptation des politiques fiscales visant à rééquilibrer le basculement du travail vers le capital et à protéger les personnes vulnérables des risques d’exclusion socio-économiques (une taxation des robots serait même envisagée par certains), l’ajustement des mécanismes de redistribution et de protection sociale, le développement des systèmes éducatifs et de formation simplifiant les transitions professionnelles répétées et durables, et la nécessité d’assurer un accès équitable au crédit, aux soins de santé et aux prestations de retraite à une main-d’œuvre plus mobile et plus exposée aux risques.
Paradoxalement, l’IA et autres technologies numériques favorisent aussi les approches innovantes et personnalisées des processus de recrutement et de recherche d’emploi, et améliorent l’efficacité de la mise en adéquation de l’offre et de la demande de main-d’œuvre. La plateforme LinkedIn s’appuie par exemple sur l’IA pour aider les recruteurs à identifier les meilleurs candidats et présenter aux utilisateurs des offres qui leur correspondent en fonction des données de profil et de l’activité des 470 millions d’inscrits sur la plateforme (Wong, 2017). Les outils d’IA peuvent bénéficier au développement de compétences et aux reconversions par le biais de dispositifs personnalisés assurant une formation de qualité à grande échelle.
À l’instar des TIC de manière plus générale (Chapitre 4), l’IA devrait accroître les besoins en compétences nouvelles sur trois axes différents : 1) les compétences spécialisées, pour développer et programmer les applications d’IA (par exemple, via l’ingénierie et la recherche fondamentale en IA, la science des données ou la pensée computationnelle) ; 2) les compétences génériques, pour tirer parti des capacités de l’IA ; et 3) les compétences complémentaires, pour accompagner par exemple la pensée critique, la créativité, l’innovation, l’entrepreneuriat, ou encore le développement de facultés humaines comme l’empathie.
La dynamique des entreprises que devrait favoriser l’IA soulève des questions en termes de répartition des richesses et d’équilibre des forces, mais aussi de concurrence et d’accès aux marchés. Par son essor rapide, l’IA pourrait en effet entrer en conflit avec les politiques de concurrence existantes et soulever des interrogations sur ses répercussions potentielles sur la répartition des revenus et le contrôle réel des technologies d’IA. Sur le plan économique, il existe une possibilité que quelques entreprises spécialisées disposant d’un accès à d’importants volumes de données et aux sources de financement nécessaires finissent par avoir la mainmise sur l’IA. Elles bénéficieraient ainsi d’un accès direct à une intelligence surhumaine et récolteraient une très grande partie des bienfaits de cette technologie. Un autre effet de l’IA serait que les entreprises risquent à terme de moins dépendre de leur main-d’œuvre humaine.
Comme ce fut le cas sur d’autres marchés de l’économie numérique et des données, l’IA pourrait créer une dynamique de type « presque tout au gagnant » en raison d’effets de réseau et d’échelle. Alors que des entreprises multinationales hautement innovantes parviennent à exporter leurs modèles économiques originaux au-delà des frontières, l’accumulation de richesses et de pouvoir par un nombre limité d’acteurs privés de l’IA pourrait susciter des tensions sur un plan national et entre les pays. Certaines parties prenantes s’inquiètent de la possibilité que des géants du numérique fassent l’acquisition de start-ups avant que celles-ci ne puissent représenter une éventuelle concurrence et du risque de concentration des ressources qui en découlerait dans le domaine de l’IA.
La gouvernance des systèmes d’IA constitue un autre ensemble de questions en matière de politiques liées à l’IA. À quels mécanismes de surveillance et de responsabilisation doivent être soumis les algorithmes d’apprentissage automatique ? Comment trouver un équilibre entre la productivité et l’accès d’un côté, et les valeurs comme la justice, l’équité et la responsabilité de l’autre ? Ces questions se posent déjà sur des enjeux critiques comme l’établissement des priorités de prise en charge à l’hôpital, les procédures d’intervention d’urgence pour les véhicules autonomes, la définition des profils de risque dans les procédures pénales, la prévention policière ou encore l’accès au crédit et à l’assurance.
La difficulté de contrôler l’utilisation des algorithmes d’IA est étroitement liée aux techniques avancées d’apprentissage automatique, en ce sens qu’il est de plus en plus complexe de suivre et de comprendre les mécanismes décisionnels des algorithmes d’IA, en raison de leur sophistication croissante, et ce, même pour les professionnels qui les conçoivent et les programment (OCDE, 2016). Les chercheurs ont commencé à travailler sur une éventuelle solution, mais les résultats restent précaires et ne sont pas assez fiables. Il convient de noter que les articles 13-15 du nouveau Règlement général sur la protection des données de l’Union européenne (UE) prévoient que les personnes dont les données sont recueillies doivent recevoir des informations suffisantes sur la logique sous-jacente, ainsi que sur l’importance et les conséquences prévues du traitement des données par les systèmes automatisés de prise de décision. Est également établi à l’article 22 le « droit de ne pas faire l’objet d’une décision fondée (…) sur un traitement automatisé ». Les protections assurées pour les personnes concernées dans le cadre de la réglementation et leurs implications pour les chercheurs et spécialistes de l’IA sont encore sujettes à discussion (Wachter, Mittelstadt et Floridi, 2016).
Le développement et la mise en œuvre à grande échelle de solutions algorithmiques de responsabilisation devraient s’avérer aussi complexes qu’onéreux. La question se pose alors de savoir qui devra en supporter le coût. Si les différents acteurs optent pour une solution à moindre coût, il faudrait alors faire face à des risques d’abus. Les décideurs devront œuvrer en étroite collaboration avec des chercheurs et des ingénieurs spécialistes de l’IA afin de développer des mécanismes permettant de trouver un équilibre entre le besoin de transparence et le secret des affaires admissible. Il peut arriver que certains concepts techniques et modèles économiques soient déjà en adéquation avec les échelles de valeur socialement acceptées. Dans ce cas, les autorités indépendantes et les organismes de normalisation technique ont un rôle essentiel à jouer. L’IEEE (Institute of Electronical and Electronics Engineers) est à l’origine d’une initiative pour l’éthique appliquée à l’intelligence artificielle et aux systèmes autonomes (Global Initiative for Ethical Considerations in Artificial Intelligence and Autonomous Systems), dont l’objectif est de garantir que la technologie et les professionnels du secteur œuvrent dans l’intérêt de l’humanité selon des principes établis. Cette initiative s’appuie sur l’expérience de l’institut dans les processus complexes de normalisation et sur ses capacités à toucher et mobiliser une communauté mondiale de plus de 400 000 spécialistes et experts répartis dans 160 pays.
Dans la mesure où l’apprentissage automatique nécessite de disposer d’importants volumes de données, les questions de gouvernance de l’IA s’étendent également à la réglementation de la collecte, du stockage, du traitement, de la propriété et de la monétisation des données. Pour libérer le potentiel de l’IA en faveur de la croissance, du développement et de l’intérêt public, il faudra s’accorder sur des normes techniques et des mécanismes de gouvernance capables d’optimiser la libre circulation des données et de promouvoir les investissements dans les services à forte intensité de données (OCDE, 2015). La difficulté de régir l’utilisation des données s’avère d’autant plus grande qu’elle est accentuée par l’impossibilité de déterminer avec certitude dans quelle mesure les technologies d’IA actuelles et futures pourront aider à la création, à l’analyse et à l’exploitation des données selon des procédés totalement nouveaux et encore jamais imaginés par les consommateurs, les entreprises et les pouvoirs publics.
Les applications comme la reconnaissance faciale et les services personnalisés offrent une plus grande commodité et une meilleure protection, mais pourraient présenter un risque pour les libertés publiques si les utilisateurs sont surveillés et si les interventions des machines ne sont pas transparentes, ou encore si chacun n’a pas accès à ses informations personnelles.
Les inquiétudes qu’inspire la possibilité d’une amplification des préjugés sociaux et des discriminations due aux algorithmes d’apprentissage automatique se renforcent à mesure que les algorithmes tirant parti des données massives deviennent plus complexes, plus autonomes et plus puissants. L’IA s’enrichit des données, mais si ces données sont incomplètes ou partiales, certains préjugés pourraient s’en trouver accentués. L’affaire « Tay » illustre parfaitement ces risques. Ce bot conversationnel d’IA développé par Microsoft fut lancé sur Twitter en mars 2016 dans le cadre d’une expérimentation ayant pour objet d’améliorer la compréhension du langage en ligne des 18-24 ans. En l’espace de quelques heures, ce bot dut être désactivé après avoir commencé à proférer des injures raciales, prôné le suprématisme blanc et affiché son soutien pour le génocide. Un autre exemple régulièrement cité d’une discrimination potentielle due à l’IA est celui des préjugés raciaux identifiés dans certains outils de « prévision des risques » utilisés par les juges dans la prise de décisions de justice ou dans le cadre d’audiences de mise en liberté sous caution. D’aucuns s’interrogent sur l’équité et l’efficacité des outils de prévision policière, d’évaluation de la solvabilité ou de recrutement, et sur la garantie réelle de protection de la diversité et de l’égalité qu’offrent ces algorithmes.
Le concept de prise de décision automatisée assistée par l’IA soulève des questions de responsabilité et d’obligations, par exemple en cas d’accident impliquant des véhicules autonomes. La nature même de l’IA, entre machine et programme créé par l’homme, rend difficile toute reconnaissance d’un statut de personne morale potentiellement responsable de ses décisions. Quant aux conducteurs humains, les assurances sont perçues comme un moyen de gérer les risques probabilistes éventuels. De nouvelles problématiques de sécurité commencent également à apparaître, comme la possibilité que des logiciels malveillants parviennent à détourner de leur utilisation première des réseaux d’IA ou des robots tueurs.
Une chaîne de blocs est une technologie de base de données distribuée et inviolable qui peut être utilisée pour conserver n’importe quel type de données, dont les transactions financières, et qui permet d’instaurer un climat de confiance dans un environnement pourtant peu fiable.
Cette section s’attache d’abord à décrire les caractéristiques propres de la technologie de chaîne de blocs et comment celle-ci contribue à instaurer un environnement technique de confiance pour les interactions sociales et économiques marquées par leur manque de fiabilité. À partir de l’exemple du Bitcoin, le premier et le plus populaire des réseaux de chaînes de blocs du secteur financier, cette section aborde également les fonctionnalités techniques et les limites des chaînes de blocs existantes. La sous-section suivante présente les principaux avantages et opportunités offerts par les chaînes de blocs, accompagnés d’exemples d’applications dans différents secteurs. Enfin, nous terminerons par une description des défis stratégiques posés par la technologie de chaîne de blocs, et notamment de la possibilité que l’utilisation des chaînes de blocs échappe à tout contrôle légal si aucune réglementation adaptée n’est prévue.
Une chaîne de blocs est une base de données distribuée inviolable capable de conserver n’importe quel type de données, et notamment des transactions financières. En raison de ses caractéristiques particulières (décrites ci-après), une chaîne de blocs peut être considérée comme une source de « confiance indirecte » (Werbach, 2016). La notion de confiance n’est plus garantie par des intermédiaires centralisés, mais par les développeurs d’une infrastructure technique sous-jacente, laquelle permet de réaliser des transactions fiables entre des nœuds qui ne seraient pas nécessairement dignes de confiance. Les nœuds d’un réseau de chaînes de blocs se coordonnent selon un protocole défini, régissant les règles d’enregistrement des informations dans une base de données distribuée. Les chaînes de blocs sont généralement mises en œuvre de telle sorte qu’aucun intervenant ne puisse contrôler l’infrastructure sous-jacente ou mettre en péril le système (Brakeville et Perepa, 2016).
Le fonctionnement des bases de données traditionnelles est assuré par des opérateurs centralisés, responsables de l’hébergement des données sur leurs propres serveurs ou dans des centres de données. À l’inverse, les chaînes de blocs s’appuient à la fois sur une infrastructure réseau distribuée de pair à pair (peer-to-peer ou P2P) pour stocker et gérer les données, et sur un réseau de pairs pour tenir et conserver un registre distribué. Le caractère distribué des chaînes de blocs laisse apparaître de nouvelles difficultés en termes de politiques et de législation. En l’absence d’un opérateur centralisé responsable de la gestion du réseau, il s’avère en effet difficile pour les régulateurs et autres autorités gouvernementales d’influencer le fonctionnement d’une grande partie de ces réseaux de chaînes de blocs.
Comparées aux bases de données traditionnelles, les chaînes de blocs présentent plusieurs caractéristiques uniques qui les rendent particulièrement adaptées à l’enregistrement de transactions et au transfert de valeurs dans des situations où les utilisateurs ne peuvent pas, ou ne souhaitent pas, avoir recours à une tierce partie de confiance :
Les chaînes de blocs jouissent d’une résistance élevée et fonctionnent indépendamment de tout opérateur intermédiaire ou autorité centrale. De ce fait, elles se démarquent par leur haut niveau de désintermédiation.
Les chaînes de blocs sont des bases de données inviolables fonctionnant uniquement par ajout. Elles s’appuient sur des primitives cryptographiques et des principes de la théorie des jeux afin de garantir qu’une fois les données enregistrées de manière décentralisée, celles-ci ne peuvent être supprimées ou modifiées de manière unilatérale.
Les données enregistrées dans une chaîne de blocs sont signées par la partie d’origine et conservées par ordre chronologique dans un nouveau bloc de transactions, dont les informations d’horodatage sont consignées par le réseau sous-jacent.
Certaines chaînes de blocs disposent également de la capacité à exécuter des logiques logicielles de manière décentralisée. En l’absence d’opérateur central responsable de l’exécution du code, ces applications en chaînes de blocs peuvent opérer selon des modalités précises et prédéterminées, garantissant aux utilisateurs un niveau de sécurité non négligeable.
Le Bitcoin est l’une des premières applications de la technologie de chaîne de blocs dans le domaine financier. Il s’agit d’une devise virtuelle (ou « crypto-monnaie »), doublée d’un système de paiement décentralisé fonctionnant indépendamment de toute banque centrale. Lancé en 2009 par une entité connue sous le nom d’emprunt Satoshi Nakamoto, la chaîne de blocs Bitcoin s’appuie sur un ensemble de technologies préexistantes dont l’association permet la création d’une base de données décentralisée et hautement sécurisée destinée à répertorier toutes les transactions réalisées sur le réseau concerné.
En seulement quelques années, le réseau Bitcoin a enregistré un taux d’adoption spectaculaire. Alors qu’il ne traitait que 100 transactions par jour en 2009, le réseau est passé à plus de 250 000 transactions confirmées par jour au 1er trimestre 2017 (Graphique 7.1). Malgré sa volatilité, la valeur du Bitcoin a également connu une forte croissance. De quelques transactions d’1 dollar en 2009, le prix du Bitcoin a atteint en mars 2017 plus de 1 200 USD.
Moyennes mobiles
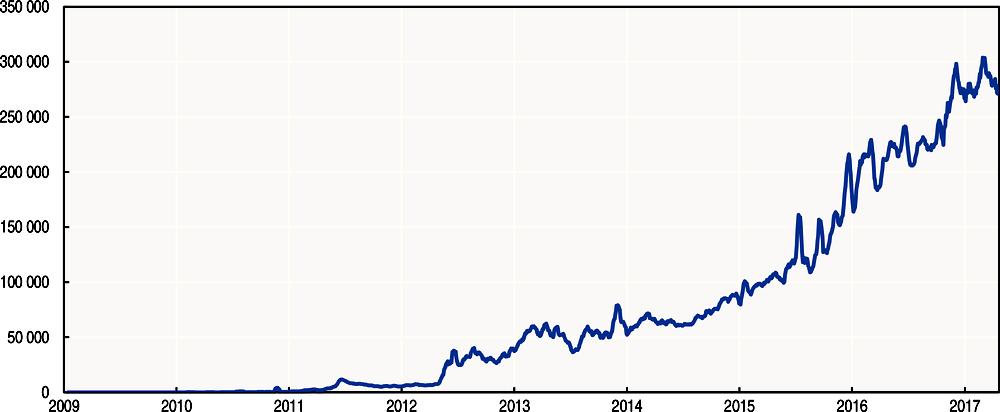
Source: Blockchain.info, https://blockchain.info/charts/n-transactions?timespan=all (consulté le 24 avril 2017).
Le Bitcoin est essentiellement une base de données décentralisée répliquée sur un réseau P2P (Nakamoto, 2008). Un réseau P2P est un ensemble d’ordinateurs (ou nœuds) œuvrant de concert pour atteindre un objectif commun, qu’il s’agisse d’échanger des fichiers, comme le réseau BitTorrent, ou d’établir des communications anonymes, à l’instar du réseau The Onion Router (Tor). Contrairement aux infrastructures client-serveur traditionnelles, ces réseaux ne sont pas gérés par un opérateur centralisé, mais s’appuient sur un réseau distribué de pairs qui interagissent et se coordonnent grâce à un protocole informatique commun.
Dans le cas du Bitcoin, les nœuds assurent la gestion et la mise à jour de l’état de la base de données selon un protocole spécifique, surnommé « preuve de travail ». L’objectif premier de ce protocole est de permettre aux nœuds de s’accorder sur l’état de la chaîne de blocs à intervalles réguliers, tout en protégeant la base de données décentralisée d’agents malveillants souhaitant altérer les données ou y insérer de fausses informations.
Ces nœuds mettent volontairement à disposition du réseau P2P leur puissance de calcul pour valider les transactions et assurer la conformité au protocole sous-jacent. Les transactions validées sont ainsi conservées dans un bloc de transactions qui est alors ajouté, en respectant l’ordre chronologique, aux chaînes de blocs précédentes.
La chaîne de blocs du Bitcoin s’appuie sur une cryptographie asymétrique4 pour garantir que seules les transactions autorisées sont prises en compte. Chaque compte Bitcoin est identifié par une adresse fixe (ou « clé publique »), à laquelle est associé un mot de passe unique (ou « clé privée ») généré de manière automatique. Pour être considérée comme valide, une transaction Bitcoin doit être signée par le titulaire du compte concerné par le biais de sa clé privée. Le système évalue ensuite la légitimité de cette transaction en vérifiant son bien-fondé (autrement dit, si le compte dispose des fonds suffisants pour honorer la transaction) et si les fonds n’ont pas été affectés plus d’une fois (en soumettant la transaction à un contrôle de « double dépense »).
La question de la « double dépense » est un problème récurrent des monnaies virtuelles décentralisées. En l’absence d’une chambre de compensation centralisée, les parties malintentionnées peuvent tenter de dépenser deux fois une même unité de monnaie virtuelle en initiant en même temps deux transactions différentes et pourtant incompatibles, comptant sur une synchronisation trop lente du réseau pour qu’aucune de ces transactions ne soit bloquée. Cette problématique a été globalement résolue par l’introduction d’un intermédiaire centralisé responsable de la compensation des transactions.
Le Bitcoin a donné lieu à l’apparition d’une solution innovante au problème de double dépense par le biais du protocole de preuve de travail. Avant qu’un bloc de transactions ne soit ajouté à la chaîne de blocs du Bitcoin, les nœuds du réseau (généralement désignés par l’appellation « mineurs ») doivent avant tout trouver une solution au puzzle mathématique inhérent à ce bloc. Ce puzzle se base sur une fonction de hachage (SHA-256) difficile à résoudre d’un point de vue informatique mais simple à vérifier une fois la solution trouvée (Bonneau et al., 2015). Cette solution est alors diffusée sur l’ensemble du réseau afin que les autres intervenants puissent vérifier sa conformité. Ce n’est qu’une fois cette étape validée que le bloc de transactions intègre enfin la chaîne de blocs du Bitcoin.
Le protocole Bitcoin adapte le niveau de difficulté du puzzle mathématique au nombre de resources actuellement mobilisables sur le réseau (soit à la puissance de hachage disponible). Plus le nombre de ressources mobilisables est important, plus le problème devient complexe, de sorte qu’un nouveau bloc de transactions ne soit ajouté que toutes les dix minutes en moyenne. Le réseau Bitcoin prévoit des incitations pour les mineurs assurant l’important travail de calcul dans le contrôle des preuves de travail. Le premier mineur qui parvient à résoudre le puzzle informatique de chaque bloc reçoit ainsi un montant donné de bitcoins, accompagné du droit de percevoir tous les frais de transaction associés au bloc concerné. Le système Bitcoin a été conçu pour que le nombre total de bitcoins en circulation soit limité à 21 millions. Par conséquent, les mineurs ne pourront à terme plus être rémunérés pour leur participation à la vérification des preuves de travail. Au vu du nombre d’utilisateurs estimé lorsque cette limite sera atteinte, les frais de transaction devraient représenter une rémunération suffisante pour l’effort consenti.
Contrairement à d’autres types de bases de données, une chaîne de blocs fonctionne uniquement par ajout. Il est donc possible d’ajouter des données à une chaîne de blocs, mais une fois enregistrées, celles-ci ne peuvent plus être supprimées ou modifiées de manière unilatérale (Narayanan et al., 2016). Dans le cas du Bitcoin, les informations enregistrées dans la chaîne de blocs ne peuvent être éditées que si une ou plusieurs parties parviennent à prendre en charge plus de la moitié de la puissance de calcul mobilisée sur le réseau. Il s’agit de ce que l’on appelle une « attaque des 51 % ». Bien que possible5 , une telle attaque serait extrêmement difficile et coûteuse à mettre en œuvre, eu égard à la taille actuelle du réseau Bitcoin.
La chaîne de blocs du Bitcoin peut ainsi être considérée comme un journal certifié de transactions chronologiques, dont l’authenticité et l’intégrité sont garanties par des primitives cryptographiques. Dans la mesure où chaque transaction doit être signée numériquement à l’aide de la clé privée du titulaire du compte, la chaîne de blocs offre une preuve vérifiable qu’un utilisateur a transféré un montant précis de bitcoins à un autre utilisateur, et ce, à un moment déterminé. Chaque bloc intégrant une référence (hachage cryptographique) à un bloc précédent, toute tentative d’altération des données enregistrées dans un bloc sera immédiatement détectée par le réseau. En réalité, la modification d’une transaction invalidera la référence au bloc précédent, ce qui entraînerait alors la rupture de la chaîne, et par la suite une détection automatique par tous les autres membres du réseau.
Toutes les chaînes de blocs n’appliquent pas les mêmes mécanismes de gouvernance. En théorie, elles peuvent toutes être placées sur une même ligne continue, allant de chaînes de blocs publiques et intégralement ouvertes, comme le Bitcoin, à des chaînes de blocs privées et accessibles uniquement sur autorisation. Les chaînes de blocs publiques et ouvertes n’appliquent aucune restriction en termes de lecture ou d’écriture sur la base de données décentralisée. Les utilisateurs ont généralement recours à des pseudonymes dans la mesure où les nœuds du réseau ne requièrent pas qu’ils dévoilent leur véritable identité. Dans leur majorité, les premiers réseaux basés sur des chaînes de blocs qui ont vu le jour après Bitcoin (dont Litecoin, Namecoin, Peercoin et Ethereum) fonctionnent sur un modèle public.
À l’inverse, une chaîne de blocs privée et accessible sur autorisation intègre un mécanisme de contrôle d’accès capable de limiter le nombre d’intervenants autorisés à exécuter certaines tâches de base sur la chaîne de blocs. Ces chaînes de blocs privées s’appuient sur des réseaux fermés gérés de manière plus étroite. Leur accès peut être réservé à des individus pré-autorisés, et le droit de valider une transaction peut n’être accordé qu’à des intervenants sélectionnés.
Les chaînes de blocs accessibles sur autorisation comme Ripple et Corda (voir ci-après) ont été développées spécifiquement pour les services financiers. Seuls les membres d’un groupe défini sont ainsi habilités à prendre part au processus de validation et à exécuter les transactions sur ces chaînes de blocs.
Le recours à une chaîne de blocs ouverte ou uniquement accessible sur autorisation se résume à une question de confiance, d’échelle et de transparence. D’un côté, les chaînes de blocs publiques et ouvertes mettent plus l’accent sur la notion de confiance. Elles la répartissent en effet sur un grand nombre de nœuds individuels et s’appuient sur des preuves de travail pour faire en sorte qu’il soit matériellement difficile et coûteux d’exploiter le réseau à des fins malveillantes. Par nature, les chaînes de blocs publiques peuvent toutefois nécessiter un investissement financier important en termes de gestion, offrent des performances limitées et, malgré le respect de l’anonymat des utilisateurs, la transparence inhérente à ces réseaux peut affecter la confidentialité des parties concernées. D’un autre côté, les chaînes de blocs privées et accessibles sur autorisation offrent une plus grande flexibilité car elles ont recours à des protocoles moins gourmands en ressources informatiques pour valider les transactions, mais aussi parce qu’un certain niveau de confiance est déjà assuré par les intervenants impliqués. Elles permettent également la création d’un environnement plus contrôlé en octroyant un accès différencié à ses parties prenantes et en privatisant une partie des transactions. Un groupement de banques peut par exemple choisir de partager un même écosystème de chaîne de blocs accessible sur autorisation, sans pour autant avoir à rendre publiques l’ensemble des transactions entre ses différents établissements. Les chaînes de blocs privées et accessibles sur autorisation requièrent malgré tout un haut niveau de confiance dans les parties assurant la gestion du réseau, et peuvent par conséquent être plus facilement manipulées en cas de piratage ou de corruption d’une de ces parties.
Des outils sont par ailleurs en cours de développement afin de permettre l’interaction de différentes chaînes de blocs et garantir leur interopérabilité. Par exemple, la société Blockstream crée des outils spécifiques à la chaîne de blocs du Bitcoin pouvant servir de base à un grand nombre de chaînes de blocs plus spécialisées, qu’elles soient ouvertes ou accessibles sur autorisation.
Malgré leur robustesse et leur inviolabilité, de nombreuses chaînes de blocs publiques et ouvertes souffrent des limites inhérentes à leur protocole de validation par consensus. Le modèle de la preuve de travail est fondé sur le principe qu’aucune partie ne doit contrôler plus de 50 % de la puissance de calcul mobilisée sur le réseau. Une fois ce seuil atteint, la partie majoritaire peut manipuler le réseau à sa guise et ainsi créer des entrées contradictoires (voir la partie relative au problème de la « double dépense ») ou encore empêcher l’ajout de certaines transactions à la base de données (Narayanan et al., 2016).
Même si l’attaque des 51 % est un problème qui affecte tous les types de chaînes de blocs, il est d’autant plus sérieux dans le cas des chaînes ouvertes, puisqu’il est particulièrement difficile de déterminer qui contrôle réellement la puissance de hachage mobilisée sur ces réseaux. Alors qu’une situation de collusion entre plusieurs nœuds d’une même chaîne de blocs privée pourrait facilement être identifiée, et même donner lieu à des poursuites judiciaires, la prise de contrôle potentielle d’une chaîne de blocs publique par un groupe d’individus non identifiés serait bien plus complexe à détecter. Cette menace n’en reste pas moins réelle. En 2017, après huit ans de fonctionnement, plus de 50 % de la puissance de hachage du réseau Bitcoin est contrôlée par seulement cinq groupements de mineurs (Blockchain, s.d., a). Il est toutefois arrivé à quelques rares occasions qu’un seul et unique groupement de mineurs contrôle plus de la moitié de la puissance de calcul du réseau.
Outre ces problématiques de sécurité, et dans la mesure où les chaînes de blocs se basent sur une cryptographie asymétrique, l’un des principaux obstacles à l’adoption généralisée de la technologie de chaîne de blocs est l’absence d’un système standard de gestion des clés doté d’un mécanisme de récupération et de révocation. Sans récupération possible, la perte d’une clé privée empêche de fait le titulaire du compte de réaliser quelque opération que ce soit sur son compte. De la même manière, sans système de révocation, si une clé privée se trouve compromise, quiconque la détient peut exécuter des transactions non autorisées à la place du titulaire du compte.
Les performances constituent une autre limite importante de la technologie de chaîne de blocs, et plus particulièrement dans le cas des chaînes de blocs publiques et ouvertes. Les chaînes de blocs publiques ne peuvent prendre en charge qu’un nombre limité de transactions. À titre d’exemple, le réseau Bitcoin enregistre moins de 300 000 transactions par jour (Blockchain, s. d., b), contre 150 millions de transactions quotidiennes traitées par Visa. La validation des transactions Bitcoin prend environ dix minutes (Blockchain, s. d., c), soit une durée bien supérieure au temps normalement nécessaire pour l’enregistrement d’informations dans une base de données.
L’adoption généralisée de la technologie de chaîne de blocs ne sera possible que lorsque ces systèmes se seront suffisamment développés pour être en capacité de gérer un nombre quasiment illimité de transactions. Résoudre ces problèmes d’évolutivité n’est toutefois pas une mince affaire. Dans la mesure où une chaîne de blocs est une base de données fonctionnant uniquement par ajout, elle grandit à chaque nouvelle transaction. Plus une chaîne de blocs est étendue, plus les besoins en termes de puissance de calcul, de stockage et de bande passante sont importants, entraînant par là même une forte consommation d’énergie. Le coût croissant de ces besoins risque de faire baisser le nombre d’acteurs prêts à soutenir le réseau, et d’augmenter ainsi les risques qu’une poignée de groupements de mineurs en prennent le contrôle (James-Lubin, 2015). Il existe déjà de nombreux projets visant à adapter les chaînes de blocs pour une utilisation à grande échelle, mais ils ne sont encore pour la plupart qu’à un stade expérimental. Citons par exemple l’application de protocoles de consensus de validation alternatifs, comme la « preuve de participation » (Buterin, 2015 ; Iddo et al., 2014)6 . Des initiatives internationales visant à établir des normes spécifiques pour la technologie de chaîne de blocs (comme la création en 2016 du Comité technique 307 de l’Organisation internationale de normalisation sur les technologies de chaîne de blocs et de registre distribué) pourraient stimuler le développement de ces technologies, notamment en encourageant une meilleure interopérabilité, une adhésion plus rapide et un plus grand effort d’innovation dans leur utilisation et dans leurs applications.
Le Bitcoin fut la première application à tirer parti des nouvelles opportunités offertes par la technologie de chaîne de blocs dans le secteur de la finance, mais les applications sont multiples, et ce, dans de nombreux secteurs. La sous-section suivante présente les principaux avantages de cette technologie, accompagnés d’exemples illustrant les expériences menées actuellement dans différents secteurs d’activité. La technologie de chaîne de blocs étant une technologie encore récente et manquant de maturité, il convient de noter que les exemples présentés ci-dessous correspondent en grande partie à des projets pilotes ou à des démonstrations de faisabilité mis en œuvre par des start-ups ou des entreprises en phase de démarrage.
La technologie de chaîne de blocs permet de réduire les frictions sur les marchés et les coûts de transaction dans certains secteurs d’activité. Malgré les coûts importants qu’implique la gestion d’une infrastructure de chaîne de blocs, cette technologie dispose d’un énorme potentiel, dont le meilleur exemple est sa capacité à augmenter l’efficacité des systèmes d’information existants en éliminant les tâches administratives et en réduisant les frais indirects inhérents aux interactions entre différents niveaux d’intermédiaires.
L’activité des envois de fonds, par exemple, fait partie des secteurs les plus affectés par les frictions sur les marchés et les coûts de transaction. Un envoi de fonds peut aujourd’hui nécessiter jusqu’à sept jours pour être validé. Les frais peuvent quant à eux représenter jusqu’à 10 % de la somme transférée. L’utilisation de chaînes de blocs peut entraîner une réduction du coût des envois de fonds en permettant à quiconque de transférer de l’argent à l’étranger, rapidement et à moindre frais depuis un appareil mobile. Lancée en novembre 2013 à Nairobi, BitPesa fut la première entreprise d’envoi de fonds à utiliser la chaîne de blocs du Bitcoin pour assurer des transferts d’argent entre pays africains. Depuis lors, de nombreuses autres start-ups ont réalisé des essais pour intégrer cette technologie. Abra semble aujourd’hui être devenu le principal acteur du secteur. Créée début 2017, cette société est la seule à avoir pris en compte les deux extrémités de la chaîne de distribution, autrement dit les étapes de conversion de monnaie fiduciaire en bitcoins et inversement.
Sur un plan plus général, les chaînes de blocs peuvent faire office d’infrastructure de base permettant aux établissements de dépôt de réaliser des transferts interbancaires et de convertir des fonds en devises. En 2012 par exemple, la société Ripple a lancé un protocole de paiement qui permet aux banques de convertir des fonds dans différentes devises en quelques secondes et à très faible coût. Le principe du protocole Ripple est de créer une série d’opérations entre des agents de change qui ont accepté d’intégrer le réseau Ripple et de déterminer la manière la plus rapide et efficace de convertir des fonds d’une devise vers une autre. Il exécute enfin ces opérations de manière instantanée grâce à une chaîne de blocs. Santander a récemment adopté ce système à titre expérimental pour l’envoi de fonds à l’international et les règlements transfrontaliers.
La technologie de chaîne de blocs peut également participer à la réduction des coûts de transaction en aidant les banques à finaliser les échanges plus rapidement et plus efficacement. Alors que chaque banque doit normalement gérer seule la consignation de ses transactions, un système de chaîne de blocs est capable de mettre à jour simultanément l’ensemble des enregistrements ; il n’est ainsi plus nécessaire d’effectuer des rapprochements bancaires entre les différents établissements concernés. Cette évolution est ce qui a inspiré la formation du consortium R3 en 2014. Comptant parmi ses membres plus de 70 banques et institutions financières, ce consortium œuvre actuellement au développement d’une technologie de registre distribué, appelée Corda, conçue pour prendre en charge et simplifier les transactions interbancaires.
La technologie de chaîne de blocs permet également d’accélérer le négoce de titres, en combinant compensation et règlement dans une seule et même opération. Plusieurs expérimentations de ce type sont actuellement en cours. En octobre 2015 par exemple, la société Nasdaq s’est associée à Chain pour travailler sur l’utilisation de la technologie de chaîne de blocs pour l’achat et la vente de parts dans des entreprises privées. Quelques mois plus tard, la société cotée Overstock, première grande boutique en ligne à accepter les règlements en bitcoins, mettait en vente ses propres actions sur une plateforme boursière (t0) basée sur la technologie de chaîne de blocs et spécialement conçue dans ce but.
Sur le marché des produits dérivés, les chaînes de blocs signent l’avènement d’une nouvelle ère d’ingénierie financière qui pourrait entraîner un gain important de sécurité, d’efficacité et de précision dans la gestion des risques. Grâce aux chaînes de blocs, il est possible d’intégrer les conditions relatives à un produit dérivé directement dans le code, afin qu’elles puissent être traitées et automatiquement exécutées par le réseau de chaînes de blocs sous-jacent. Un essai concluant a été mené en 2016 par la Depository Trust & Clearing Corporation et cinq autres sociétés cotées à Wall Street (Bank of America, Merrill Lynch, Citi, Credit Suisse et JPMorgan), consistant à coder les conditions des contrats d’échange sur le risque de défaillance directement dans un système de chaîne de blocs afin de faciliter la gestion de tous les événements ultérieurs aux transactions. Quelque temps après, début 2017, la Depository Trust & Clearing Corporation annonçait son intention de transférer l’équivalent de 11 000 milliards USD de dérivés de crédit vers une infrastructure de chaîne de blocs développée spécifiquement à ces fins. L’objectif de cette opération est d’améliorer le traitement des produits dérivés par une automatisation de la tenue du registre et de réduire les coûts de rapprochement.
Parce qu’elles constituent des bases de données transparentes, inviolables et capables d’enregistrer des informations horodatées, les chaînes de blocs peuvent faire office de registre mondial de transactions certifiées et authentifiées. Il est possible d’enregistrer des données importantes sur une chaîne de blocs, de sorte à les rendre immédiatement disponibles à l’ensemble des utilisateurs, et à en empêcher toute modification ou suppression a posteriori par la partie responsable de leur enregistrement.
Dans de nombreuses situations toutefois, il est important de préserver la confidentialité des informations. Plutôt que de conserver les données directement dans une chaîne de blocs, celles-ci peuvent être soumises à un processus de hachage7 . Elles sont ainsi divisées en courtes chaînes (appelées « empreintes ») faisant office d’identifiant unique pour les données concernées. Cette opération aide à la certification de la source et de l’intégrité d’enregistrements spécifiques sans pour autant divulguer publiquement d’informations sensibles. Bien qu’il soit en effet impossible d’extraire des informations par simple consultation d’une empreinte, quiconque dispose des données d’origine peut vérifier qu’elles n’ont pas été altérées en comparant cette empreinte avec celle qui a été enregistrée dans la chaîne de blocs.
Plusieurs gouvernements étudient la possibilité d’utiliser les chaînes de blocs pour assurer la transparence et la fiabilité des archives publiques. En 2015, le gouvernement estonien annonçait un partenariat avec la start-up Bitnation visant à proposer à tous ses ressortissants disposant d’un compte en ligne des services de notariat basés sur des chaînes de blocs (actes de mariage, extraits de naissance, contrats commerciaux, etc.). En 2016, l’agence Estonian eHealth Authority s’est associée avec Guardtime, une société de sécurité informatique, afin de créer une infrastructure de chaîne de blocs ayant pour objectif de préserver l’intégrité des dossiers médicaux et autres données sensibles, et d’en améliorer l’auditabilité. En mai 2016, le Ghana s’alliait à l’organisation Bitland pour constituer un cadastre basé sur des chaînes de blocs afin de venir compléter le registre foncier officiel du gouvernement. En janvier 2017, c’est la Géorgie qui s’associait à la société Bitfury pour conserver ses informations de propriété foncière dans un système de chaînes de blocs. Enfin, en avril 2017, la start-up Civic Ledger bénéficiait d’un financement du gouvernement australien afin d’améliorer la transparence et la fiabilité des informations du marché des ressources en eau grâce aux chaînes de blocs.
De nouvelles opportunités sont également apparues dans les secteurs de l’éducation et de la culture. Citons par exemple l’initiative Digital Certificates Project du Massachusetts Institute of Technology (MIT). Lancé en octobre 2016, ce projet s’appuie sur la chaîne de blocs du Bitcoin pour la délivrance de certificats ou d’attestations indiquant qu’un étudiant a suivi une formation spécifique ou réussi un examen. Une initiative du même ordre a vu le jour en France, à l’École supérieure d’ingénieurs Léonard-de-Vinci, laquelle s’est associée avec Paymium, une start-up française spécialisée dans le Bitcoin, afin d’utiliser la chaîne de blocs du Bitcoin pour certifier les diplômes. La société Verisart, fondée en 2015, utilise par ailleurs une chaîne de blocs pour permettre aux artistes et aux collectionneurs d’établir des certificats d’authenticité pour leurs œuvres. Lorsqu’une œuvre est vendue, la transaction est enregistrée sur une chaîne de blocs, de sorte à permettre à chacun de vérifier l’existence d’un titre de propriété valide. Cette initiative a pour objectif la création d’un registre mondial simplifiant l’authentification et la traçabilité des œuvres d’art au niveau mondial.
Pour les entreprises, la technologie de chaîne de blocs représente également un nouveau moyen d’établir la source et l’authenticité des produits. Différentes initiatives ont déjà été mises en place pour lutter contre la contrefaçon de produits de luxe. La société Blockverify exploite ainsi les technologies de chaîne de blocs et de registre distribué pour proposer des solutions de transparence de la chaîne de l’offre et de lutte anti-contrefaçon pour les applications spécifiques aux produits pharmaceutiques, articles de luxe, diamants et équipements électroniques. De même, la société Everledger utilise depuis 2015 une chaîne de blocs pour affecter aux diamants un identifiant unique afin d’en assurer le suivi sur le marché secondaire. Cette technologie peut également aider dans la lutte contre la fraude, le marché clandestin et le trafic, notamment dans le cas des diamants de conflit provenant de zones de guerre.
Le même principe s’applique à d’autres types de produits. Sur le marché du commerce équitable, l’entreprise sociale Provenance, fondée en 2013, met à profit la technologie de chaîne de blocs pour contrôler la provenance des denrées alimentaires, et assurer leur traçabilité à chaque étape, et ce, jusqu’au consommateur final. À ce jour, la société est parvenue à mener une expérimentation concluante basée sur la technologie de chaîne de blocs et l’étiquetage intelligent pour contrôler la provenance de thon en Indonésie, dans le respect des exigences de durabilité sociale. D’autres start-ups ont mis en place des expérimentations du même ordre, notamment pour suivre l’acheminement de produits par transport maritime (TBSx3) ou aider les entreprises agricoles à mieux gérer leur chaîne d’approvisionnement et vérifier la provenance des produits qu’ils utilisent (Agridigital).
Une chaîne de blocs peut également contenir des programmes logiciels, généralement appelés « contrats intelligents » (Szabo, 1997)8 , exécutés par des mineurs de manière distribuée sur un réseau de chaîne de blocs. Ces contrats intelligents se distinguent de programmes existants du fait de leur capacité à s’exécuter de façon autonome, c’est-à-dire indépendamment de tout opérateur centralisé ou tierce partie de confiance. On les décrit ainsi souvent comme étant auto-exécutables et à exécution garantie (Buterin, 2013). Ils fonctionnent selon plusieurs étapes de traitement et appliquent des conditions de type « si x, alors y », dont quiconque sur le réseau peut vérifier l’exécution. Parce qu’ils se basent sur un réseau décentralisé qui n’est contrôlé par aucun opérateur unique, les contrats intelligents offrent l’assurance d’une exécution prédéfinie et déterministe, sans nécessiter d’intervention extérieure.
Lancée en août 2015, Ethereum est de loin la plus importante plateforme de déploiement de codes pour contrats intelligents. Il s’agit également du deuxième plus grand réseau de chaînes de blocs après Bitcoin, puisqu’elle totalise une capitalisation boursière de plus de 4 milliards USD et enregistre un volume de transactions quotidien supérieur à 100 millions USD. La chaîne de blocs d’Ethereum exploite un langage de programmation complet au sens de Turing9 , appelé Solidity, associé à une machine virtuelle partagée. Ce langage est de fait devenu une norme pour le développement d’un grand nombre d’applications de chaînes de blocs. Une fois déployé, le code d’un contrat intelligent est conservé, sous une forme précompilée, dans la chaîne de blocs d’Ethereum, puis une adresse lui est affectée. Pour interagir avec un contrat intelligent, les parties doivent envoyer une transaction à l’adresse correspondante, ce qui déclenche automatiquement l’exécution du code sous-jacent. La plateforme Ethereum peut ainsi être considérée comme une couche de traitement mondiale et distribuée, servant de base pour des applications et systèmes décentralisés. Même si Ethereum fait figure de précurseur, d’autres plateformes ont depuis mis en place des fonctionnalités similaires, comme Rootstock, Monax, Lisk et Tezos.
Les contrats intelligents ne permettent généralement la mise en œuvre que de fonctionnalités de base, comme l’exécution d’une transaction conditionnelle en fonction d’un ensemble de paramètres prédéfinis. Ils sont également utilisés pour l’application de systèmes de séquestre, dont le principe vise à lancer une transaction dès qu’une condition précise est remplie. Grâce à un contrat intelligent, il est possible de transférer un actif vers un programme qui s’exécutera automatiquement de manière périodique afin de valider automatiquement certaines conditions et déterminer si cet actif doit être transmis à un tiers, renvoyé à la personne qui en est à l’origine, ou les deux. Ces contrats intelligents peuvent également servir à automatiser des paiements récurrents. Un contrat de location peut ainsi être appliqué à l’aide d’un contrat intelligent stipulant par exemple les dispositions sur lesquelles un locataire et un propriétaire se sont accordés (montant de la location, date de remise des clés, date de libération des lieux, etc.). En combinant et en interconnectant plusieurs contrats intelligents, il est possible de créer des systèmes sophistiqués capables de proposer des fonctionnalités avancées.
Il est important de noter qu’aucun logiciel n’est jamais dénué de défauts, et il en va de même pour les contrats intelligents. L’exécution garantie du code d’un contrat intelligent, associée à l’interdépendance de nombreuses transactions, peut représenter un risque majeur, notamment lorsque ce code est déployé dans un environnement sans système formalisé d’arbitrage ou de résolution des conflits. Le piratage de la plateforme TheDAO illustre parfaitement ce risque (Encadré 7.3), puisqu’une vulnérabilité présente dans le code d’un contrat intelligent aurait pu entraîner une perte potentielle de plus 150 millions USD.
Malgré le déploiement d’un nombre important de contrats intelligents sur des chaînes de blocs, il n’existait jusqu’alors que peu d’applications décentralisées réellement exploitables. Même si la plupart ne sont encore qu’à un stade expérimental, elles témoignent clairement du potentiel de la technologie de chaîne de blocs. Par exemple, Akasha et Steem.it sont deux réseaux sociaux distribués qui contrairement à Facebook fonctionnent sans plateforme centrale. Plutôt que de s’appuyer sur un organe principal pour gérer le réseau, ces plateformes sont exécutées de manière décentralisée. Elles rassemblent en effet les contributions des nombreux pairs d’un réseau distribué, lesquels se coordonnent conformément à un ensemble de règles codées directement dans une plateforme de chaîne de blocs.
OpenBazaar est un réseau décentralisé, comparable à eBay, à la différence qu’il fonctionne indépendamment de tout opérateur intermédiaire. Cette plateforme exploite la technologie de chaîne de blocs pour permettre aux vendeurs et aux acheteurs d’interagir directement, sans entremise extérieure. Dès qu’un acheteur sollicite un produit auprès d’un vendeur, un compte de séquestre est créé sur la chaîne de blocs du Bitcoin afin de garantir que les fonds ne seront débloqués qu’une fois le produit reçu par l’acheteur.
Plusieurs plateformes décentralisées de covoiturage ont également vu le jour, comme Lazooz ou ArcadeCity. Celles-ci ne sont pas gérées par une tierce partie de confiance (de type Uber), mais sont régies par le code déployé dans une infrastructure de chaîne de blocs qui assure les interactions de pair à pair entre chauffeurs et clients.
TheDAO est certainement l’exemple plus célèbre des applications décentralisées. Ce fonds de placement, mis en œuvre sur la chaîne de blocs Ethereum en avril 2016, permettait aux investisseurs de voter pour les propositions à soutenir. De ce fait, il fut décrit comme la première organisation décentralisée tirant parti de la technologie de chaîne de blocs pour coordonner l’activité de personnes qui ne se connaissent pas et n’ont donc aucune raison de se faire confiance. Un mois après son lancement, TheDAO avait levé l’équivalent de plus de 150 millions USD d’Ethers (devise numérique d’Ethereum). Cette expérimentation fut malheureusement de courte durée. TheDAO fut contraint de mettre un terme à ses opérations après qu’un pirate eut exploité une vulnérabilité présente dans son code et détourné plus d’un tiers de ses fonds. Face à l’ampleur de cette attaque et à ses conséquences potentielles sur l’écosystème global d’Ethereum, la communauté des utilisateurs se mobilisa pour annuler la transaction et récupérer les fonds détournés. Cette opération nécessita une division du réseau Ethereum en deux chaînes distinctes, une décision vivement critiquée par certains membres de la communauté car elle allait à l’encontre des garanties d’immuabilité de la chaîne de blocs Ethereum. Cet incident a permis une meilleure sensibilisation sur les questions de responsabilité afférentes à ces applications intégralement décentralisées.
Les opportunités que représente la technologie de chaîne de blocs ne se limitent pas au monde numérique. Elles s’étendent en effet au monde physique par l’amélioration des capacités des objets qui nous entourent. L’avènement de l’IdO marque l’émergence d’appareils connectés capables de communiquer entre eux et d’interagir avec les personnes à proximité afin de mieux s’adapter à leurs besoins spécifiques. Ces appareils présentent des caractéristiques propres aux technologies numériques : la connectivité et la programmabilité.
Une fois ces appareils connectés à une chaîne de blocs, ils bénéficient de fonctionnalités complémentaires du simple fait qu’ils peuvent directement interagir les uns avec les autres, sans l’intervention d’un opérateur intermédiaire, et ainsi échanger des données de manière décentralisée.
Samsung s’est ainsi récemment associé à IBM pour tester la faisabilité d’un appareil IdO doté de fonctionnalités de chaîne de blocs : un lave-linge capable, après avoir détecté un faible niveau de lessive, de déclencher une transaction sur la base d’un contrat intelligent avec un détaillant afin de commander et payer une nouvelle recharge de lessive (IBM, 2015). Outre une réduction des coûts de transaction, ce modèle a pour avantage de ne pas nécessiter du consommateur qu’il communique ses coordonnées bancaires à Samsung ou à un autre opérateur de confiance. Il lui suffit en effet d’approvisionner le compte de son appareil chaque fois que son solde devient insuffisant.
Il s’agit ici d’un exemple d’application très simple, mais ce modèle pourrait être déployé sur de nombreux types d’appareils connectés différents. L’intégration de la technologie de chaîne de blocs avec l’IdO permet l’activation ou la désactivation d’appareils connectés par le biais de simples transactions de chaîne de blocs. À l’instar des lignes téléphoniques mobiles prépayées qui ne peuvent être utilisées que si l’utilisateur dispose d’un crédit suffisant sur son compte, on pourrait imaginer une voiture qu’il n’est possible de démarrer que si le conducteur a acheté un stock suffisant de kilomètres. On pourrait également envisager un véhicule de location dont les droits d’utilisation seraient représentés par un jeton sur une chaîne de blocs et qui pourraient ainsi être transférés à tout moment par le biais d’une simple transaction, sans recourir à un quelconque opérateur centralisé.
Bien que ces exemples ne soient actuellement que théoriques, différentes initiatives de ce type sont d’ores et déjà à l’œuvre. La société allemande Slock.it développe par exemple depuis 2015 des serrures connectées qu’il est possible de contrôler à l’aide de contrats intelligents. Le propriétaire d’une telle serrure exploitant la technologie de chaîne de blocs peut ainsi définir le tarif dont devra s’acquitter un tiers pour avoir le droit d’ouvrir cette serrure pendant une durée déterminée. Une fois la somme versée, un contrat intelligent octroiera au tiers à l’origine de la transaction le droit d’utiliser cette serrure pendant la période complète de la location. Bien que le développement de ce produit ne soit qu’à ses prémices, la société Slock.it a pour ambition de voir sa technologie s’appliquer à la location de bicyclettes, de garde-meubles, d’habitations et même de véhicules. Une autre société, Filament, travaille depuis 2012 sur la mise au point d’un réseau sans fil sécurisé pour appareils connectés, et se penche actuellement sur l’adoption d’une chaîne de blocs pour l’échange de données de capteurs et autres informations, ainsi que pour l’établissement de transactions entre ces appareils dans le cadre de contrats intelligents.
Les défis stratégiques les plus couramment associés à la technologie de chaîne de blocs ont trait aux problématiques de l’évasion fiscale, du blanchiment de capitaux, du financement d’activités terroristes et du soutien de la criminalité (trafic d’armes ou de stupéfiants, par exemple), comme illustré par la plateforme décentralisée de marché noir Silk Road10 .
La plupart de ces défis sont en partie liés au caractère transnational des réseaux de chaînes de blocs existants. Parce qu’elles sont déployées sur un réseau P2P décentralisé, la grande majorité des applications de chaînes de blocs mises en œuvre jusqu’à maintenant posent des difficultés d’application des législations nationales. Réguler ou interdire ces applications présente une réelle difficulté, dans la mesure où les utilisateurs peuvent facilement contourner les contraintes réglementaires prévues par un gouvernement ou un État particulier. De par leur nature décentralisée, les réseaux de chaînes de blocs s’avèrent difficiles à neutraliser, puisque cela nécessiterait de neutraliser chacun des nœuds constituant le réseau. D’autres technologies décentralisées ont par le passé soulevé des défis du même ordre, comme le système de communication P2P anonymisé Tor, ou encore des technologies de partage de fichier P2P comme BitTorrent ou eMule.
Ce qui fait la particularité principale des défis soulevés par la technologie de chaîne de blocs et les distingue des problématiques liées aux technologies de l’internet existantes est le fait que les applications basées sur les chaînes de blocs fonctionnent généralement de manière indépendante de tout intermédiaire centralisé ou autorité de confiance. Elles peuvent par conséquent susciter des inquiétudes semblables à celles associées à l’IA sur le marché de l’emploi, même si leur effet potentiel sur le travail est extrêmement difficile à évaluer en raison du déploiement encore trop sommaire des chaînes de blocs. Elles privent également les gouvernements du recours à un opérateur ou intermédiaire centralisé pour veiller au respect des législations nationales applicables à l’internet.
Comme décrit précédemment, les chaînes de blocs ouvertes simplifient la création de systèmes de paiement décentralisés (Bitcoin, par exemple) fonctionnant sans organisme central de compensation, augmentant ainsi les craintes d’une éventuelle perte du contrôle monétaire (Blundell-Wignall, 2014). Elles permettent aussi l’émergence de marchés décentralisés, sur lesquels des titres peuvent être émis et échangés sans recourir à un quelconque intermédiaire réglementé, ou encore l’apparition d’applications décentralisées fonctionnant indépendamment de toute autorité centrale. Contrairement aux applications existantes (exécutées depuis un serveur, détenues et contrôlées par un opérateur défini), les applications basées sur des chaînes de blocs sont exécutées de manière distribuée sur un réseau décentralisé de pairs. Elles évoluent ainsi en dehors du contrôle de tout opérateur extérieur.
Cela peut s’avérer problématique dans le cas des systèmes anonymisés où toutes les parties ne sont identifiables que par leur clé privée. Dans un modèle centralisé, l’intermédiaire exécutant une transaction a également la capacité de l’annuler. À l’inverse, si une transaction a été exécutée par inadvertance ou à des fins malveillantes dans une chaîne de blocs ouverte, aucune partie ne peut l’annuler de manière unilatérale. Le vol ou la perte d’une clé privée pourrait ainsi avoir de graves conséquences pour le titulaire du compte.
Par ailleurs, dans la mesure où elles sont anonymisées, les chaînes de blocs ouvertes compliquent sensiblement (voire rendent impossibles) l’application de législations prévues pour lutter contre les pratiques illicites. Cela soulève plusieurs questions essentielles : comment et à qui imputer les préjudices causés par les systèmes de chaînes de blocs ? Qui doit endosser la responsabilité juridique de ces préjudices et comment assurer la réparation des dommages liés à un système basé sur des chaînes de blocs si sa gestion n’est assurée par aucune autorité centrale ?
La nature décentralisée des chaînes de blocs, associée à la capacité d’exécution automatique des contrats intelligents, implique qu’il devient possible de concevoir des systèmes de chaînes de blocs quasiment invulnérables aux mesures coercitives de l’État. Le cas échéant, ces systèmes peuvent passer outre une ordonnance judiciaire, dans la mesure où ils peuvent être programmés pour empêcher quiconque de saisir leurs actifs.
De toute évidence, les pouvoirs publics pourraient en théorie poursuivre les parties concernées au titre de la création et du déploiement de systèmes de chaînes de blocs, au motif que ces systèmes sont utilisés pour des activités dangereuses ou illégales. Les développeurs d’une chaîne de blocs pourraient par exemple se voir imputer la responsabilité de tout dommage prévisible que ces systèmes sont susceptibles de causer à un tiers, en vertu du droit de la responsabilité du fait des produits. L’invocation de ces dispositions législatives risquerait néanmoins de décourager tout effort d’innovation dans ce domaine et, même dans l’éventualité où les développeurs d’un système basé sur des chaînes de blocs illicite étaient poursuivis pour leurs travaux, cela n’affecterait en rien la manière dont ce système fonctionne.
En raison de la robustesse et de l’inviolabilité des contrats intelligents, une fois qu’une transaction a été exécutée puis validée par le réseau de chaînes de blocs sous-jacent, elle ne peut être supprimée a posteriori de manière unilatérale. Et dans la mesure où l’exécution garantie fait partie des principaux avantages de ces systèmes une fois qu’ils ont été déployés, il devient extrêmement difficile de modifier le code et le fonctionnement d’une application basée sur des chaînes de blocs, et plus encore de neutraliser celle-ci complètement. Le seul moyen d’annuler une transaction de chaîne de blocs ou de suspendre l’application d’un contrat intelligent est de recourir à une action coordonnée du réseau dans sa globalité, à l’instar du réseau Ethereum suite à l’attaque dont fut victime TheDAO. Bien qu’une telle opération puisse facilement être mise en œuvre dans le cas des chaînes de blocs accessibles sur autorisation (puisqu’elles ne requièrent qu’un nombre restreint d’intervenants identifiés pour atteindre un consensus), cela s’avère bien plus délicat pour les chaînes de blocs ouvertes en raison des coûts importants de coordination nécessaires pour établir un consensus auprès d’un grand nombre de parties non identifiées.
La transparence et la quasi-immunité de ces systèmes à tout contrôle sont également source de défis importants. Même si l’anonymat garanti par les environnements de chaîne de blocs ouverts peut encourager la liberté d’expression et améliorer à terme la disponibilité des informations, il peut également entraver l’application des législations visant à contrôler les flux d’informations, comme les lois sur les droits d’auteur, les propos haineux ou la diffamation. Par exemple, associée aux réseaux décentralisés de partage de fichiers, la capacité à enregistrer des informations dans une base de données inviolable pourrait faciliter l’échange de contenus illicites ou contraires aux bonnes mœurs (pédopornographie, vengeance pornographique ou humiliation publique notamment). Certains experts considèrent néanmoins qu’il est peu probable que de telles activités criminelles soient hébergées sur des chaînes de blocs dans la mesure où les transactions laissent trop de traces qui permettraient d’identifier leurs auteurs. Ces risques restent limités dans le cas des chaînes de blocs accessibles sur autorisation, puisqu’il est possible de relier directement l’identité physique d’un individu à son identité numérique. Le fait qu’une donnée ne puisse être supprimée de manière unilatérale une fois intégrée à une chaîne de blocs augmente toutefois considérablement la difficulté d’une application efficace de certaines réglementations, comme le droit à l’oubli garanti par la législation de l’Union européenne.
Aucun système de chaînes de blocs, même conçu spécifiquement pour contourner la loi, n’est jamais totalement isolé et autonome. Il existe en effet un certain nombre d’intermédiaires incontournables assurant l’interfaçage de ces systèmes avec le reste de la société. Citons notamment les mineurs responsables du contrôle et de la validation des transactions, les agents de change assurant la conversion de devises virtuelles basées sur des chaînes de blocs en monnaie fiduciaire (et inversement) ou encore les divers opérateurs commerciaux ou non commerciaux qui interagissent avec ces systèmes. Ces points de contact constituent la meilleure chance pour les autorités législatives d’exercer leur influence afin de réguler ces systèmes, même indirectement.
Références
Arntz, M., T. Gregory et U. Zierahn (2016), « The Risk of Automation for Jobs in OECD Countries: A Comparative Analysis », OECD Social, Employment and Migration Working Papers, n° 189, Éditions OCDE, Paris, http://dx.doi.org/10.1787/5jlz9h56dvq7-en.
Blockchain (s.d., a), « Répartition du hashrate : Une estimation de la répartition du hashrate parmi les pools minières les plus importantes », page web, https://blockchain.info/fr/pools.
Blockchain (s.d., b), « Confirmed transactions per day », page web, https://blockchain.info/fr/charts/n-transactions.
Blockchain (s.d., c), « Median confirmation time », page web, https://blockchain.info/fr/charts/median-confirmation-time.
Blundell-Wignall, A. (2014), « The Bitcoin Question: Currency versus Trust-less Transfer Technology », OECD Working Papers on Finance, Insurance and Private Pensions, n° 37, Éditions OCDE, Paris, http://dx.doi.org/10.1787/5jz2pwjd9t20-en.
Bonneau, J. et al. (2015), « Research perspectives and challenges for Bitcoin and cryptocurrencies », Proceedings of IEEE Symposium on Security and Privacy, 17-21 mai 2015.
Brakeville, S. et B. Perepa (2016), « Blockchain basics: Introduction to distributed ledgers », IBM, 9 mai, www.ibm.com/developerworks/cloud/library/cl-blockchain-basics-intro-bluemix-trs.
Buterin, V. (2015), « Slasher: A punitive proof-of-stake algorithm », blog Ethereum, 14 août.
Buterin, V. (2013), « Livre Blanc », Ethereum, www.asseth.fr/2016/11/09/traduction-whitepaper-ethereum/.
CB Insights (2017), « The 2016 AI Recap: Startups See Record High In Deals And Funding », Research Briefs, www.cbinsights.com/research/artificial-intelligence-startup-funding/ (consulté le 16 août 2017)
Chen, K. et al. (2012), « Building high-level features using large scale unsupervised learning », juillet, v5, https://arxiv.org/abs/1112.6209.
Citibank (2016), Technology at Work v2.0: The Future is Not What it Used to Be, Citigroup, www.oxfordmartin.ox.ac.uk/downloads/reports/Citi_GPS_Technology_Work_2.pdf.
Dutton, J. (2011), « Raging Bull: The Lie Catcher! », Mental Floss, http://mentalfloss.com/article/28568/raging-bull-lie-catcher.
Elliot, S.W. (2014), « Anticipating a Luddite revival », Issues in Science and Technology, vol. XXX/3, printemps, http://issues.org/30-3/stuart.
Evans, R. et J. Gao (2016), « DeepMind AI reduces Google Data Centre cooling bill by 40% », blog DeepMind, 20 juillet, https://deepmind.com/blog/deepmind-ai-reduces-google-data-centre-cooling-bill-40.
FIT (Forum international des transports) (2017), « Managing the Transition to Driverless Road Freight Transport », International Transport Forum Policy Papers, n° 32, Éditions OCDE, Paris, http://dx.doi.org/10.1787/0f240722-en.
Frey, C.B. et M.A. Osborne (2013), « The future of employment: How susceptible are jobs to computerisation? », Oxford Martin School, 17 septembre, www.oxfordmartin.ox.ac.uk/downloads/academic/The_Future_of_Employment.pdf.
Goertzel, B. et C. Pennachin (2006), Artificial General Intelligence, Springer, Berin, Heidelberg, http://dx.doi.org/10.1007/978-3-540-68677-4.
IBM (2015), « Empowering the edge: Practical insights on a decentralized Internet of Things », IBM Institute for Business Value, Somers, New York, https://www-935.ibm.com/services/multimedia/GBE03662USEN.pdf.
Iddo, B. et al. (2014), « Proof of activity: Extending Bitcoin’s proof of work via proof of stake », ACM SIGMETRICS Performance Evaluation Review, vol. 42, n° 3, pp. 34-37.
James-Lubin, K. (2015), « Blockchain scalability », O’Reilly Media, 21 janvier, www.oreilly.com/ideas/blockchain-scalability.
Lake, B. et al. (2016), « Building machines that learn and think like people », Behavioral and Brain Sciences, 2 novembre, http://cims.nyu.edu/~brenden/1604.00289v3.pdf.
Maison Blanche (2016a), « Preparing for the future of AI », Executive Office of the President, National Science and Technology Council, Washington, DC, octobre, https://obamawhitehouse.archives.gov/sites/default/files/whitehouse_files/microsites/ostp/NSTC/preparing_for_the_future_of_ai.pdf.
Maison Blanche (2016b), « Artificial intelligence, automation, and the economy », Executive Office of the President, Washington, DC, décembre, https://obamawhitehouse.archives.gov/sites/whitehouse.gov/files/documents/Artificial-Intelligence-Automation-Economy.PDF.
Nakamoto, S. (2008), « Bitcoin: A peer-to-peer electronic cash system », https://bitcoin.org/bitcoin.pdf.
Narayanan, A. et al. (2016), Bitcoin and Cryptocurrency Technologies, Princeton University Press, Princeton, NJ.
Nikkei (2015), « IBM’s Watson to help doctors devise optimal cancer treatment », Asian Review, 30 juillet, http://asia.nikkei.com/Tech-Science/Science/IBM-s-Watson-to-help-doctors-devise-optimal-cancer-treatment.
Nilsson, N. (2010), The Quest for Artificial Intelligence: A History of Ideas and Achievements, Cambridge University Press, Cambridge, Royaume-Uni.
OCDE (Organisation de coopération et de développement économiques) (à paraître), « Neurotechnology and Society: Strengthening Responsible Innovation in Brain Science », Science, Technology and Industry Policy Papers, OCDE, Paris.
OCDE (2017), The Next Production Revolution: Implications for Governments and Business, Éditions OCDE, Paris, http://dx.doi.org/10.1787/9789264271036-en.
OCDE (2016), « Summary of the CDEP Technology Foresight Forum: Economic and Social Implications of Artificial Intelligence », éléments de la communication de MM. Susumu Hirano et Tatsuya Kurosaka, OCDE, Paris, http://oe.cd/ai2016.
OCDE (2015), Data-Driven Innovation: Big Data for Growth and Well-Being, Éditions OCDE, Paris, http://dx.doi.org/10.1787/9789264229358-en.
Poon, J. et T. Dryja (2016), « The Bitcoin Lightning Network: Scalable off-chain instant payments ».
Purdy, M. et P. Daugherty (2016), « Why artificial intelligence is the future of growth », Accenture, octobre, www.accenture.com/futureofAI.
Szabo, N. (1997), « The idea of smart contracts », www.fon.hum.uva.nl/rob/Courses/InformationInSpeech/CDROM/Literature/LOTwinterschool2006/szabo.best.vwh.net/idea.html.
UK Government Office for Science (2016), « Artificial intelligence: Opportunities and implications for the future of decision-making », Government Office for Science, Londres, https://www.gov.uk/government/publications/artificial-intelligence-an-overview-for-policy-makers.
Voegeli, J. (2016), « CIA-funded Palantir to target rogue bankers », Bloomberg, 22 mars, https://www.bloomberg.com/news/articles/2016-03-22/credit-suisse-cia-funded-palantir-build-joint-compliance-firm.
Wachter, S., B. Mittelstadt et L. Floridi (2016), « Why a right to explanation of automated decision-making does not exist in the general data protection regulation », International Data Privacy Law, 28 décembre, https://ssrn.com/abstract=2903469.
Wang, D. et al. (2016), « Deep Learning for Identifying Metastatic Breast Cancer », 18 juin, Cornell University Library, https://arxiv.org/pdf/1606.05718v1.pdf.
Werbach, K.D. (2016), « Trustless trust », https://ssrn.com/abstract=2844409.
Wong, Q. (2017), « At LinkedIn, artificial intelligence is like “oxygen” », The Mercury News, 6 janvier, www.mercurynews.com/2017/01/06/at-linkedin-artificial-intelligence-is-like-oxygen.
← 1. Les données statistiques concernant Israël sont fournies par et sous la responsabilité des autorités israéliennes compétentes. L’utilisation de ces données par l’OCDE est sans préjudice du statut des hauteurs du Golan, de Jérusalem-Est et des colonies de peuplement israéliennes en Cisjordanie aux termes du droit international.
← 2. OpenAI est dirigé sous la présidence conjointe de Sam Altman et d’Elon Musk, et compte parmi ses soutiens financiers Amazon Web Services (AWS), Infosys et YC Research.
← 3. Depuis lors, de nouveaux partenaires se sont associés à cette initiative, parmi lesquels des entreprises commerciales (eBay, Intel, McKinsey & Company, Salesforce, SAP, Sony, Zalando et Cogitai) et des organisations à but non lucratif (Allen Institute for Artificial Intelligence, AI Forum of New Zealand, Center for Democracy & Technology, Centre for Internet and Society – India, Data & Society Research Institute, Digital Asia Hub, Electronic Frontier Foundation, Future of Humanity Institute, Future of Privacy Forum, Human Rights Watch, Leverhulme Centre for the Future of Intelligence, l’UNICEF, Upturn et la Fondation XPRIZE). Elles rejoignent ainsi les sociétés fondatrices et les partenaires à but non lucratif existants (AAAI, ACLU et OpenAI). Dans le cadre de ce partenariat, chaque organisation s’engage à promouvoir la science ouverte et à débattre des implications éthiques, sociales, économiques et juridiques de l’IA, mais aussi à développer la recherche en IA pour des technologies stables, fiables, dignes de confiance et fonctionnant dans un environnement sécurisé.
← 4. La cryptographie asymétrique permet un échange d’informations chiffrées sans nécessiter d’échange de clé. Tout utilisateur souhaitant envoyer des données à un autre utilisateur utilisera alors sa clé privée et la clé publique du destinataire pour coder les informations. Ce destinataire sera par la suite en mesure de décoder les informations reçues à l’aide de sa clé privée et de la clé publique de l’expéditeur.
← 5. Malgré les faibles probabilités, il convient de noter qu’un tel scénario s’est déjà produit en 2014. Un groupement de mineurs (Ghash.io) est ainsi parvenu à prendre en charge 55 % des besoins de calcul du réseau Bitcoin. Plutôt que d’exploiter cette situation à des fins malveillantes, Ghash.io a immédiatement réduit sa capacité de calcul pour éviter de compromettre la crédibilité du réseau.
← 6. La « preuve de participation » est une méthode selon laquelle un réseau de chaînes de blocs cherche à établir un consensus distribué en demandant aux utilisateurs de prouver la possession d’une certaine quantité d’une ressource définie. Cette méthode présente de nombreux avantages, puisqu’elle augmente notamment de manière importante le nombre de transactions possibles lorsqu’elle est appliquée conjointement avec le protocole Casper. Des canaux de paiement comme le réseau Bitcoin Lightning (Poon et Dryja, 2016) et des mécanismes de type partitionnement (ou sharding) (Iddo et al., 2014) constituent d’autres approches possibles.
← 7. Le hachage consiste en la génération d’une courte chaîne (ou empreinte) à partir d’un élément spécifique de contenu. Cette empreinte est générée par l’application d’une formule mathématique conçue de telle sorte que la moindre modification du contenu, même minime, produirait une chaîne totalement différente. Une empreinte est souvent utilisée comme l’identifiant unique du contenu à partir duquel elle a été générée, car les probabilités qu’un autre élément de contenu donne lieu à la même valeur d’empreinte sont extrêmement faibles. Parce qu’elles permettent de garantir qu’un message n’a pas été altéré, les empreintes jouent un rôle essentiel dans les systèmes de sécurité.
← 8. Szabo (1997) décrivait les contrats intelligents comme « un ensemble d’engagements, définis sous forme numérique, incluant des protocoles selon lesquels les parties accomplissent d’autres engagements ».
← 9. Un langage de programmation est considéré comme complet au sens de Turing si l’on peut démontrer qu’il présente des capacités de calcul équivalentes à celles d’une machine de Turing. Autrement dit, tout problème pouvant être résolu par une machine de Turing à partir d’une quantité limitée de ressources doit également pouvoir être résolu à l’aide de ce langage de programmation à partir d’une quantité limitée de ressources.
← 10. Le marché Silk Road s’appuyait sur le Bitcoin et le réseau Tor pour permettre la création de transactions anonymes entre ses utilisateurs et faciliter le commerce de produits illicites, comme les armes ou les stupéfiants. Cette plateforme a finalement pu être démantelée en raison de l’incapacité de son fondateur, Ross Ulbricht, à masquer les retraits en bitcoins qu’il effectuait lui-même depuis le site.