L’analyse de régression linéaire multiple donne un aperçu de la façon dont la valeur de la variable dépendante continue (ou de résultat) change lorsque l’une des variables indépendantes (ou explicatives) varie alors que toutes les autres variables indépendantes restent constantes. En général, et toutes choses étant égales par ailleurs, une augmentation d’une unité de la variable indépendante (Xi) augmente, en moyenne, la variable dépendante (Y) des unités représentées par le coefficient de régression (βi) :
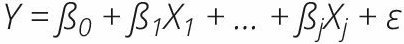
En interprétant les coefficients de régression multiples, il est important de garder à l’esprit que chaque coefficient est influencé par les autres variables indépendantes dans un modèle de régression. L’influence dépend du degré de corrélation entre les variables indépendantes. Par conséquent, chaque coefficient de régression ne rend pas compte de l’effet total des variables indépendantes sur les variables dépendantes. Chaque coefficient représente plutôt l’effet additionnel de l’ajout de cette variable au modèle, si les effets de toutes les autres variables du modèle sont déjà pris en compte. Il est également important de noter que, puisque des données d’enquêtes transversales ont été utilisées dans ces analyses, on ne peut tirer aucune conclusion de type causal.
Les coefficients de régression en gras dans les tableaux de données présentant les résultats de l’analyse de régression sont significativement différents d’un point de vue statistique de 0 à un niveau de confiance de 95 %.
Analyse de régression logistique binaire
L’analyse de régression logistique binaire permet d’estimer la relation entre une ou plusieurs variables indépendantes (ou explicatives) et la variable dépendante (ou de résultat) avec deux catégories. Le coefficient de régression (ß) d’une régression logistique est l’augmentation estimée de la cote logarithmique du résultat par unité d’augmentation de la valeur de la variable prédictive.
De façon plus formelle, soit Y la variable binaire de résultat indiquant non/oui avec 0/1, et p la probabilité que Y soit 1, de sorte que p = prob (Y=1). Soit X1,… Xk est un ensemble de variables explicatives. Alors, la régression logistique de Y sur X1,… Xk estime les valeurs des paramètres pour ß0, ß1,..., ßk par la méthode du maximum de vraisemblance de l’équation suivante :
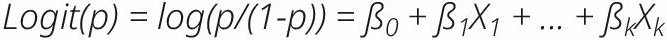
De plus, on obtient la fonction exponentielle du coefficient de régression (exp (ß)), qui est le rapport de cotes (RC) associé à une augmentation d’une unité dans la variable explicative. Ensuite, en termes de probabilités, l’équation ci-dessus se traduit comme suit :
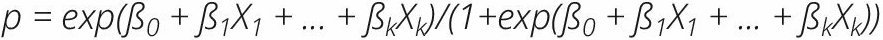
La transformation des cotes logarithmiques (ß) en rapports de cotes (exp (ß) ; RC) permet de mieux interpréter les données en termes de probabilité. Le rapport de cotes (RC) est une mesure de la probabilité relative d’un résultat particulier dans deux groupes. Le rapport de cotes pour l’observation du résultat en cas de présence d’un antécédent est :
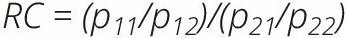
où p11/p12 représente la « probabilité » d’observer le résultat lorsque l’antécédent est présent, et p21/p22 représente la « probabilité » d’observer le résultat lorsque l’antécédent est absent. Ainsi, un rapport de cotes indique dans quelle mesure une variable explicative est associée à une variable de résultat catégorique comportant deux catégories (p. ex. oui/non) ou plus. Un rapport de cotes inférieur à 1 dénote une association négative ; un rapport de cotes supérieur à 1 indique une association positive ; et un rapport de cotes égal à 1 signifie qu’il n’y a pas d’association. Par exemple, si on analyse l’association entre le fait d’être une enseignante et le fait d’avoir fait de l’enseignement son premier choix de carrière, les rapports de cotes suivants seraient interprétés comme suit :
0.2 : Les enseignantes sont cinq fois moins susceptibles que les enseignants d’avoir fait de l’enseignement leur premier choix de carrière.
0.5 : Les enseignantes sont deux fois moins susceptibles que les enseignants d’avoir fait de l’enseignement leur premier choix de carrière.
0.9 : Les enseignantes sont 10 % moins susceptibles que les enseignants d’avoir fait de l’enseignement leur premier choix de carrière.
1 : Les enseignantes et enseignants sont tout autant susceptibles d’avoir fait de l’enseignement leur premier choix de carrière.
1.1 : Les enseignantes sont 10 % plus susceptibles d’avoir fait de l’enseignement leur premier choix de carrière que les enseignants.
2 : Les enseignantes sont deux fois plus susceptibles que les enseignants d’avoir fait de l’enseignement leur premier choix de carrière.
5 : Les enseignantes sont cinq fois plus susceptibles que les enseignants d’avoir fait de l’enseignement leur premier choix de carrière.
Les rapports de cotes sont en gras si le ratio relatif risque/cote est différent de 1 dans une mesure statistiquement significative à un niveau de confiance de 95 %. La signification statistique autour de 1 (hypothèse nulle) est calculé dans le scénario où la statistique du rapport risque/ratio relatif suit une distribution log-normale et non une distribution normale, selon l’hypothèse nulle.
Dans les modèles logistiques des tableaux II.2.53, II.2.54, II.2.55 et II.2.56 du chapitre 2, la probabilité que les enseignants souffrent « dans une grande mesure » de stress professionnel (variable binaire) varie en fonction de l’intensité (exprimée en nombre d’heures) de tâches spécifiques (variable explicative continue) et de leurs termes quadratiques, ajoutés pour tenir compte des cas possibles de non-linéarité.
Une fois estimés, les coefficients des modèles logistiques sont convertis en probabilité comme suit :
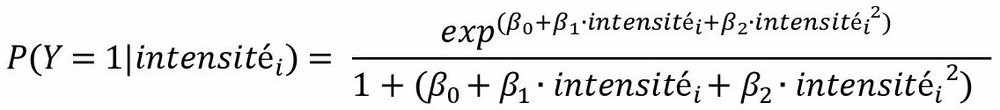
Où
P(Y=1|intensité) est la probabilité de souffrir « dans une grande mesure » de stress professionnel compte tenu du nombre d’heures (intensité) consacré à la tâche i (enseignement, planification ou préparation des cours, correction des copies des élèves et travail administratif d’ordre général) ;
β0, β1, β2 sont les coefficients du modèle logistique et, l’intercept.
Enfin, la probabilité de souffrir « dans une grande mesure » de stress professionnel associée à une intensité des tâches donnée est multipliée par 100 pour estimer le pourcentage d’enseignants souffrant de stress au travail « dans une grande mesure » à cette intensité.

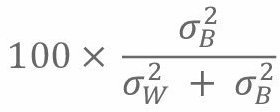
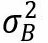 et
et 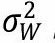 , sont respectivement la variance inter-établissements et intra-établissement estimée.
, sont respectivement la variance inter-établissements et intra-établissement estimée.